 夜雨聆风
夜雨聆风
01
当AI开始"读心"
上海前滩中心65层,云涧空间。下午两点的阳光极具穿透力,透过巨大的落地窗洒在地板上。
我刚戴上千问AI眼镜,它就传来"新闻播报"——而且正是我想听的海外科技新闻速读。
"它是怎么知道我的想法的?"
作为一名智能眼镜赛道的长期观察者,我脑海中闪过的第一个念头不是惊喜,而是审视。当一副眼镜开始尝试读懂你的意图、在你开口之前就给出答案,这究竟是人机交互的伟大进化,还是一种全新的"注意力入侵"?
这套"读心术"能给我们带来什么?它又是如何在几十克的躯壳里跑通的?带着这两个问题,我在5月7日和8日连续两天深度体验了千问AI眼镜S1的新版本,并在8日上午专访了阿里千问AI眼镜硬件产品负责人晋显。

🔺阿里千问AI眼镜产品负责人晋显在活动现场
02
跟着一天走:五个场景,五种"读心"
理解这套"读心术"最好的方式,不是看参数表,而是跟着真实的一天走一遍。阿里为千问AI眼镜这次升级设计了一条完整的全天候生活轨迹,从清晨到深夜,覆盖了现代都市人高频使用的五个显性场景与一条健康暗线。每一个场景里,"主动"的程度和形态都不一样,但背后的逻辑是一致的:让眼镜在你需要它的时候出现,在你不需要它的时候消失。
清晨:早安电台+智能陪跑
天刚亮,戴上眼镜的那一刻,千问不需要你开口。早安电台自动触发——天气播报、定制新闻、你爱的歌单,依次进入耳朵。手机不用拿出来,不需要解锁,不需要点开任何应用。
跑步时的体验更能说明问题。说一句"你好千问,开始跑步"之后,配速、距离、消耗卡路里同步显示在视野里。眼镜知道你在跑步这件事,不仅是因为你告诉了它,更是因为它感知到了你的步频和移动速度,从而主动做出适配:系统不仅会自动播放音乐,而且还会智能推荐节奏感更强、专门适合跑步听的专属歌单。
🔺说出“开始跑步”后,眼镜自动开启音乐,并显示配速、距离、消耗卡路里数据,图源:AR圈
除了基础的伴跑,我还发现了一个极具亮点的"高光时刻"功能。这是一种典型的条件触发(If-Then)机制:你可以通过可以通过语音一句话设置触发,也可以在APP内提前设定一个门限条件(例如"当配速即将达到6'00''时"),并绑定一个自动操作(如"录屏15秒")。在实际起跑后,一旦系统感知到你的配速突破该阈值,眼镜就会自动无感抓拍下这段高光视频。这种体验彻底跳出了冷冰冰的数据记录,让眼镜化身为一个懂你状态的智能陪跑教练。
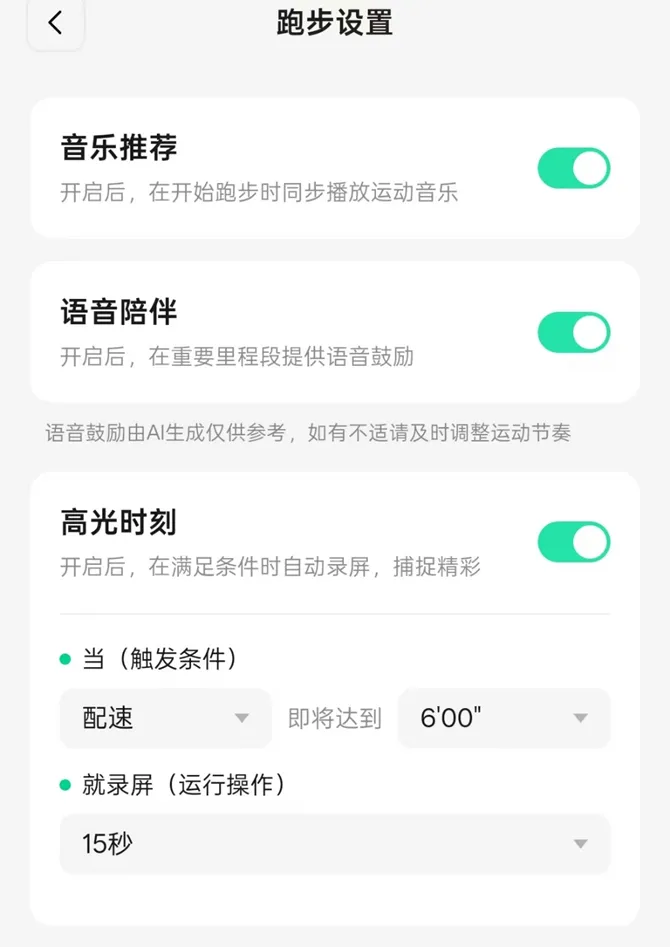
🔺高光时刻的触发阈值可以在手机APP设置,图源:AR圈
更令人惊喜的是,据透露该功能在不久后即将迎来一次新的升级:届时用户将不仅可以用手机APP设定阈值,还可以直接对眼镜说一句"你好千问,如果我配速快过每公里5分半就自动录一段视频",即可通过纯自然语音直接完成条件阈值的设定。
这是主动服务极具穿透力的形态。它不抢戏,只在你切换状态的节点或达成某个特定条件的瞬间主动出现——从静止到运动,从室内到室外,从休息到工作。这种"感知状态切换"与"个性化条件触发"融合的能力,是过去所有单纯依靠唤醒词的AI助手都做不到的事。它改变的不只是交互方式,而是眼镜在你生活里的存在感:从一个等待指令的工具,变成了一个跟着你节奏走、甚至能为你提供情绪价值的伴侣。
上午:录音纪要+AI克隆同声传译
开会,是最能体现主动服务价值的场景之一,也是商务用户最容易被这款产品说服的切入点。
🔺会议纪要新增图文总结和脑图等新功能,图源:AR圈
千问AI眼镜内置录音纪要功能,会议进行时持续录音,结束后自动整理成能一图读懂要点的图文会议稿件,关键结论和待办事项单独提取。这个功能本身已经足够实用,但在现场体验后,更让我眼前一亮的是AI克隆同声传译。
之前的同声传译,翻译过来的声音都是固定的音色,而现在阿里千问眼镜可以直接克隆本人音色。我实际测试了让对方说中文或者英文,听到的音色几乎与本人没有区别。这个应用,已经不需要再去看翻译字幕了,直接听即可。这样一来,眼神始终可以落在对方脸上。整个沟通过程中,我没有一次低头看手机,没有一次打断对方说"等一下,我查一下翻译"。翻译稳定跟上讲话节奏,延迟控制在可接受范围内。
🔺AI克隆同声传译实拍,图源:AR圈
这种"眼神在场"的沟通质感,是手机翻译软件在物理上无法实现的。用手机翻译,你必然要低头,必然要分心,对方感受到的是你在看手机而不是在听他说话。眼镜翻译和人声克隆解决的不只是语言障碍,解决的是跨语言沟通时人与人之间的那种微妙疏离感。
对于有大量涉外沟通需求的商务人士来说,这一个场景就足以支撑购买决策。
中午:扫街探店+同款比价+极速支付
午间这条场景链,是阿里生态整合能力最直接的展示。
🔺阿里生态整合能力展示,图源:AR圈
走近一家店面,可以直接问眼镜这家店怎么样。眼镜自动识别门店,给出评分、人均消费、推荐菜品等等信息。在展区模拟的街边探店场景里,这个体验相当流畅。
逛街时看到心仪的物件,对着它拍一下,全网比价结果直接出来。这个功能的价值不只是省钱,更在于它把"值不值得买"这个判断从事后行为变成了当场行为——你站在货架前就能知道这个价格是不是最优,不用回家再搜。
结账时的极速支付是整条场景链最流畅的收尾。支付宝账号绑定眼镜后,扫码支付在视野里完成。这个体验在现场测试时几乎是无感的——你只是看了一眼,然后东西就付完了。另外值得一提的是,之前支付是需要语音确认的,对于社恐的人来说会比较尴尬。而新的升级可以无需语音“确认”,只需要点头或滑动镜腿即可完成付款,感觉好了很多。不过也期待未来能推出完全不需要说话的版本。
这套体验能跑通,背后是支付宝、高德、淘宝三套数据底座在同时支撑。缺少任何一个节点,整条服务链路就会断裂。这不是硬件能力,这是生态能力——而这恰恰是其他AI眼镜品牌,最难复制的东西。

🔺阿里千问AI眼镜支付画面展示,图源:AR圈
下午:实况对话(逛展场景)
千问AI眼镜的"实况对话"功能,把多轮对话的上下文留存在眼镜里。你可以对着同一个对象连续追问,它记得你上一个问题是什么,回答会接续上下文而不是每次从零开始。这听起来简单,但在真实使用中差别很大。
在现场"午后花园"展区,我在一副油画前连续提了三个问题。三个问题没有一次重新唤醒,眼镜始终保持着对话的连贯性。
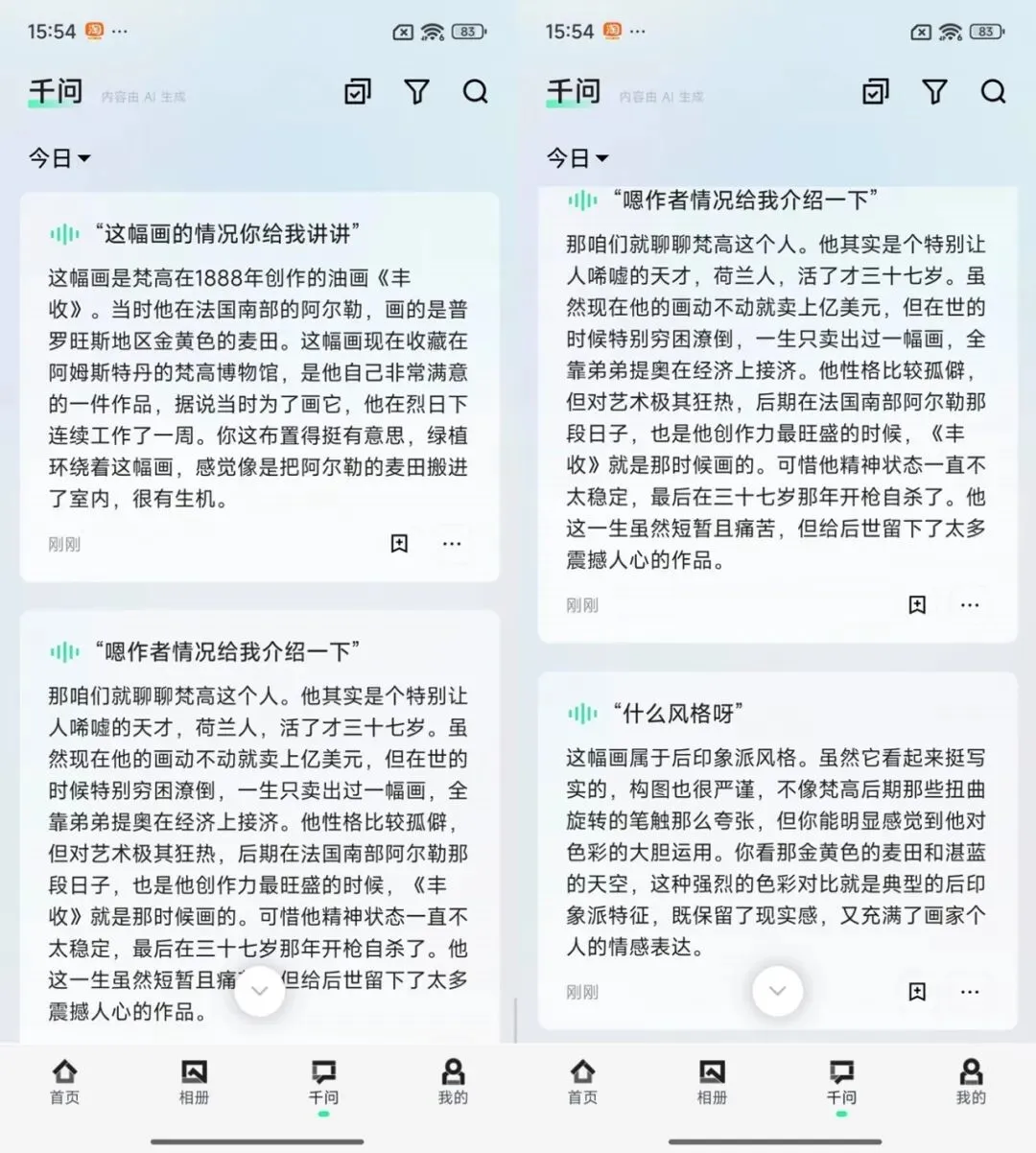
🔺由于实况过程中暂时无法对眼镜同步录屏,因此这里通过手机app的记录呈现实况对话的记录,图源:AR圈
这对逛展、参观博物馆、问诊、法律咨询等"需要连续深挖"的场景价值极高。过去你跟AI说话,每一句都是孤立的;现在它开始能跟着你的思路走,这是从工具到助理最关键的一步跨越。
值得一提的是,这个场景也让双目空间3D显示的价值体现得格外直观——字幕带有空间深度地悬浮在画作前方,仿佛真实呈现在现实空间里,而不是贴在镜片上的平面贴纸。这一点,我们在下面的章节会专门展开。
晚间:拍照答疑
晚间场景偏向学习和知识获取。对着一些题目拍照,千问直接给出答案,并主动追问"要不要听解析"——它不只是给你结果,而是带着引导逻辑,像一个有耐心的辅导老师,问你下一步想做什么。
在现场的体验里,我用眼镜对准了几道不同领域的选择题,拍照后两秒内得到了答案,随后眼镜主动说"这道题需要我展开讲一下吗"。这个主动追问的设计,比单纯给答案多走了一步,也是"主动服务"在学习场景里最直接的体现。
对于有孩子的家庭用户,或者正在备考的人群,这个场景的实用性相当直接。更重要的是,这个场景让眼镜从白天的工作效率工具,延伸成了晚间的学习辅助工具——一副眼镜覆盖了一天里大部分的高频需求。

🔺拍照答疑功能在手机端的记录,图源:AR圈
向内感知:一条贯穿全天的健康暗线
除了上述按时间线展开的向外理解与效率辅助,千问AI眼镜的这次升级还暴露了另一个底层野心:向内量化身体。相比于智能手表只能受限于手腕,智能眼镜占据了现代职场人最脆弱、也最核心的生理枢纽——颈椎。
基于头部姿态传感器的持续运作,千问AI眼镜在健康中心里构建了一套极具针对性的“颈椎健康”模型。它摒弃了笼统的步数统计,而是将用户的颈椎负荷实时划分为“良好”、“轻度”与“重度”三个阶梯。在提醒机制上,系统表现出了极佳的分寸感:它并不会因为你偶尔的低头就频繁报警,只有当底层数据确认颈椎连续处于“重度负荷”超过15分钟时,才会触发“颈椎疲劳提醒”,温柔地提示用户抬头放松。
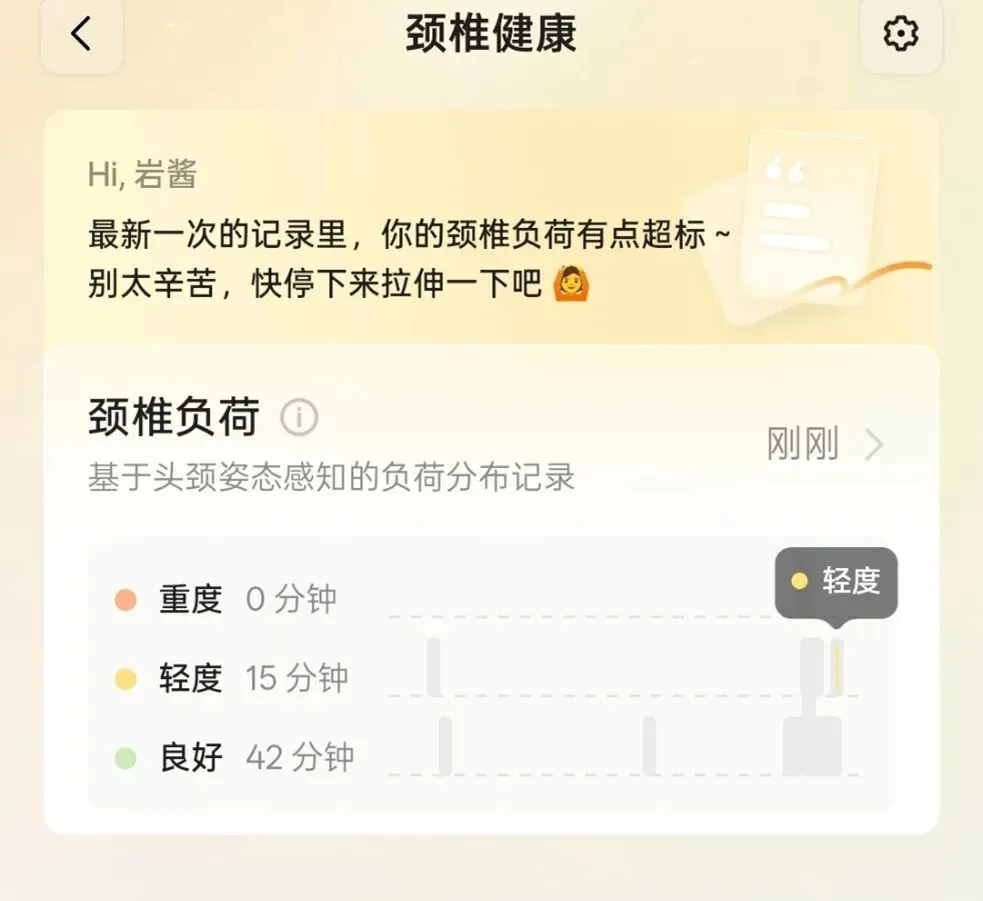
🔺颈椎健康记录能在手机端查看并设置健康提醒,图源:AR圈
而在更广阔的泛运动与基础健康层面,千问同样补齐了体验闭环。配合前文提到的“状态感知”无感触发机制,眼镜能顺滑地接管“户外跑步”与“户外骑行”的数据记录。运动结束后,不仅能查阅精确到秒的平均配速、用时与千卡消耗,还能直接生成包含高精度GPS轨迹路线的实景分享卡片,一键同步至社交网络。
此外,在最基础的“久坐提醒”上,阿里依然展现出了对打工人真实场景的细腻观察:除了支持自定义(如60分钟)的起身间隔外,还直接在首层设置了“午休免打扰”(如12:00至13:30)的强硬开关。
这套健康监测逻辑的全面铺开,彻底丰满了千问AI眼镜的“主动服务”的骨架。它证明了这副眼镜不仅能在你工作时充当外脑,更能成为一个全天候蛰伏在耳畔、时刻关注你生理底线的无声伴侣。
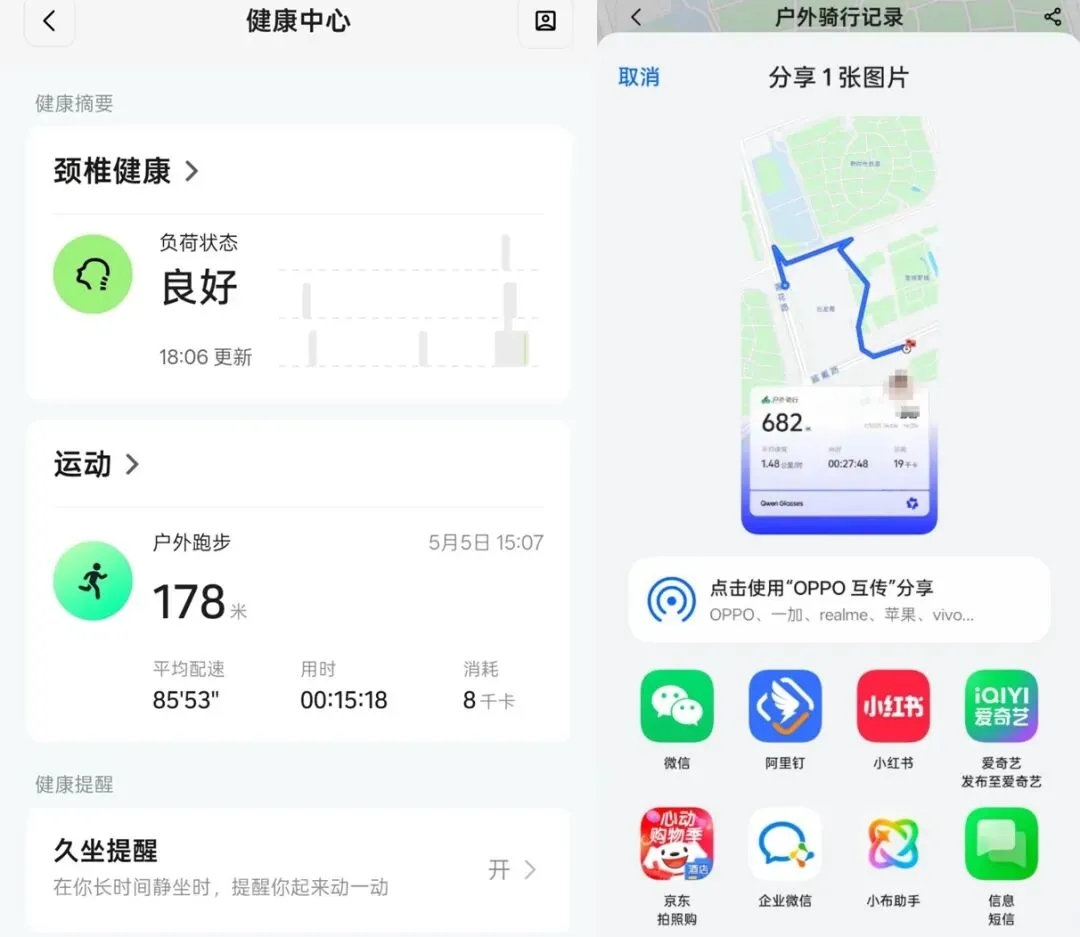
🔺手机端的健康中心可以查看颈椎、运动与设置久坐提醒、健康提醒,以及分享户外骑行运动记录,图源:AR圈
场景小结:一天的"读心术"说明了什么
从清晨的早安电台到晚间的拍照答疑,再到贯穿始终的健康凝视,这六个切面走下来,有一个感受越来越清晰:千问S1这次升级的核心,不是某一个单点功能的突破,而是用"主动感知+场景适配"重新定义了AI眼镜应该如何融入一个人真实的一天。
每个场景里的"主动"都是克制的。它不会在你跑步时突然说"检测到你在跑步,需要推荐运动食谱吗",也不会在你看展时每走三步就触发一次介绍。它在该出现的时候出现,不该出现的时候安静地待着。这种克制,比任何一个单点功能都更难做到,也是这款产品最值得认真对待的地方。
但随之而来的问题是:这套"读心术"背后的技术逻辑是什么?持续感知不会把电量榨干吗?主动触发的边界是怎么划定的?这些问题,在8日上午对晋显的专访里,得到了清晰的答案。
03
双目空间3D显示:突破二维割裂感
如果说"主动服务"是软件层面的激进,那么系统级空间3D显示就是硬件层面的硬核秀肌肉。
目前市面上绝大多数近眼显示都有一个通病:二维信息的"膏药感"。无论是音乐界面还是翻译字幕,都像是强行贴在单侧镜片上的贴纸——不仅遮挡视线,还与现实世界的深度完全脱节。你清楚地知道那个绿色箭头是虚假的,它只是一层覆盖在现实上的滤镜。

🔺其实这里的每个图标都是3D的,而且是动态3D,但受限于我们的媒体形式,只能依靠大家脑补了,图源:AR圈
在现场的街区实测中,千问S1的双光机双目MicroLED方案展示出了截然不同的体验质感。带有空间深度的UI出现在每个角落——菜单如此,具体应用亦如此。这种"空间感"一旦体验过,就很难再接受单眼的平面显示方案,就像从立体声退回单声道。
唯一遗憾的是,这种体验几乎无法通过图像传达——它本质上依赖双眼视差,是只属于佩戴者的感知,镜头捕捉不到。只能请各位自行脑补了。

🔺阿里千问AI眼镜S1搭载双光机,图源:AR圈
当然,双光机方案不是免费的午餐。两颗光机意味着更高的硬件集成难度、更大的散热压力,以及对镜腿空间的极致压榨——所有模块必须在宽度仅7.5mm的镜腿截面内共存。
但阿里押注双目,显然不只是为了一个更好看的信息提示。
千问S1真正激进的地方在于:3D显示被写进了系统级UI规范。这不是某个功能碰巧支持空间感,而是每一个菜单、每一个界面,都在遵循同一套3D视觉语言——重要内容浮在更近的层次,背景信息退入更深的底层,信息的主次关系通过空间距离直接传达给眼睛,而不需要大脑费力去解析颜色、字号或加粗。
这套逻辑有点像苹果的Human Interface Guidelines:不是一次性的炫技,而是一套所有应用都必须遵守的设计语言。区别在于,苹果的规范在平面屏幕上营造层级感,而千问S1的规范,是在真实的三维空间里建立层级。
结果是:你看一个界面的速度变快了。因为空间深度本身就是信息——大脑处理"这个东西离我更近"的速度,远快于处理"这个字更粗所以更重要"。这是人类视觉系统几百万年进化的结果,3D规范只是第一次让智能眼镜学会了用这门语言说话。
对于复杂度的代价,晋显在采访中没有回避:
"我们在硬件选择上从没想过走容易的路。双光机双目是我们认为未来AI眼镜应该走的方向,现在承受这个复杂度,是为了在正确的路上建立领先。"
04
"读心术"背后:算力与克制的博弈
从"指令驱动"到"意图感知"
千问AI眼镜这次软件升级的核心关键词只有两个字:主动。
过去的交互逻辑是"指令驱动"——你不开口,它就装死,等待唤醒词。而现在,它试图成为真正的生活助理。但聪明之处在于,它没有走让摄像头和麦克风时刻保持"微觉醒"那条既耗电又侵犯隐私的笨路,而是切换到了"状态感知"与"底层传感器融合"的路径。
例如,系统能精准感知"眼镜戴上"这一动作,结合当前时段自动触发相应任务(如晨间播报);或者通过IMU捕捉到用户正在跑步,顺势启动运动音乐并开启后台记录。感知在前,响应在后,全程无需一句唤醒词。
意图感知:化解矛盾的底层逻辑
尽管绕开了音视频常驻监听,多传感器的持续运转与全天候续航之间,依然是一对结构性矛盾——感知越多,耗电越快;电越快耗完,用户越不想戴;越不戴,数据越少,主动服务就越没有意义。
在上午的专访中,晋显没有回避这个问题。他坦言,当AI与人的交互频次呈指数级上升,功耗的"负利"必然随之而来,关键在于如何让"正利"远大于"负利"。他将千问S1的解法提炼为三个层面的克制:
首先是算力克制。主动服务不靠摄像头全程狂奔,而是依赖极低功耗的传感器进行轻量触发。
其次是场景克制。必须精准区分用户的明确意图与模糊意图,具备'场景屏蔽'能力——如果传感器察觉到用户正在沉浸式通话或登台演讲,系统会自动静音退让。
最后是交互克制。信息呈现必须像手机顶部的通知栏,只占边缘视线而不遮挡全屏;同时,必须把随时打断、随时修改的绝对控制权还给用户。主动智能绝不能变成让人感到失控的野蛮入侵。
这三条克制,对应着一套严密的软硬协同机制。
在硬件底层,是极致的主副分工。S1没有让主芯片全程待命,而是把环境感知压在协处理器(如BES2800)上充当"神经末梢",只有当本地判断触发了阈值,才瞬间唤醒主处理器与云端大模型介入。"本地轻量感知+云端重度推理"的端云协同,稳稳守住了全天候续航的红线。
在软件表层,是空间级的防打扰设计。结合双目3D显示,千问S1的主动推送不再是生硬贴在视线中央的"膏药",而是带有空间深度地悬浮在余光边缘。点头、摇头,或一句语音,随时可以回应,也随时可以打断。
这套逻辑彻底厘清了"主动服务"的伦理边界:感知在后台,呈现靠边缘,控制权永远在人手里。
"分寸感":最难调校的不是算法,是克制
主动服务最难跨越的鸿沟,从来不是技术瓶颈,而是"打扰"的边界。每隔几分钟就强行刷存在感的眼镜,和永远装死的眼镜一样令人沮丧——前者制造焦虑,后者形同虚设。
这条线究竟画在哪里,是整个产品体验最难拿捏的灵魂所在。晋显透露,内部在触发阈值上选择了极其保守的策略:
"比如早晨通勤场景,它只做精准播报,内容高度可自定义,绝不输出任何多余的废话。主动服务的高级感,恰恰来自这种绝不逾矩的分寸感。"
传统硬件的"主动"往往沦为暴力的"打扰"——无效通知推送得越多,用户越想一键关闭。千问S1的底层逻辑是反共识的:宁可少触发,也绝不触发错。
在两天的深度体验里,我确实未曾遭遇一次唐突的推送。它的介入总是恰好卡在那个微妙时刻——或者更准确地说,卡在我"可能需要、但还没意识到自己需要"的隐性萌芽处。这种克制的分寸感,是任何产品都无法靠堆料来伪装的成熟度。
当然,触发边界的最终标定绝非一日之功。实验室的演示场景永远是理想化的真空,这条线最终该落在哪里,只有数百万用户的真实体感才能给出最终裁判。
05
和美国对手PK
提到AI眼镜,自然绕不开Meta。但如果还拿无屏的Ray-Ban Meta去对标千问S1,是错位拉踩。真正与千问S1在同一牌桌上的,是搭载了近眼显示的Ray-Ban Meta Display。
把两款产品的核心维度放在一起,差距比想象中要大。
重量:50克和69克之间隔着什么
千问S1的整机重量控制在50克,恰好压在行业公认的"舒适临界线"上。Ray-Ban Meta Display的重量是69克,标准款如此,大号款更甚。
19克的差距,听起来不大,戴在脸上是完全不同的感受。50克是你能忘记自己戴着眼镜的重量,69克是你会持续感知到鼻梁压力的重量。一副你会想一直戴着的眼镜,和一副你会时不时摘下来休息的眼镜,在"主动服务"这个命题上的价值截然不同——主动服务的前提,是你愿意一直戴着它。
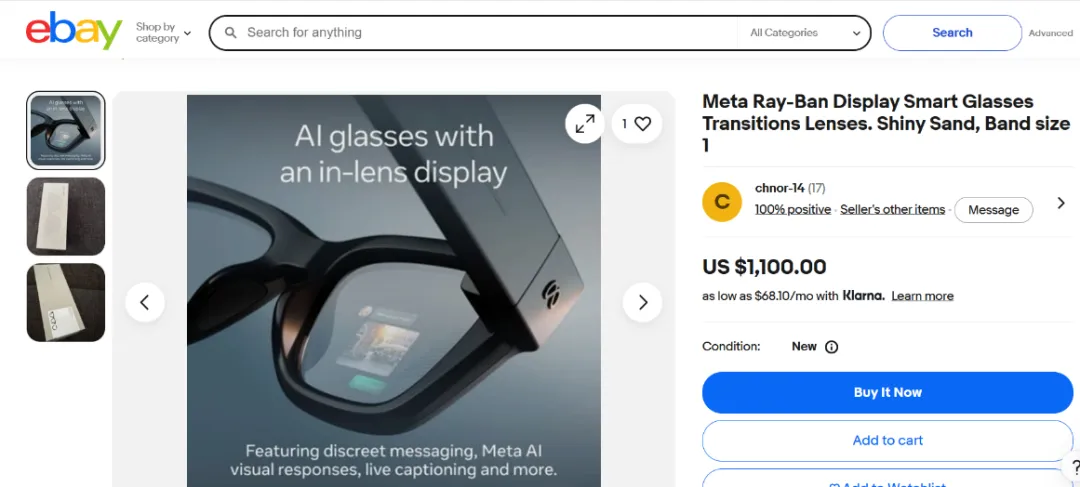
🔺Ray-Ban Meta Display眼镜799 美元,如加配近视镜,整套价格超过7千元人民币,图源:eBay
显示方案:双目3D和单目2D的本质差异
千问S1采用双光机双目MicroLED方案,支持双眼空间3D显示。Ray-Ban Meta Display虽然是彩色显示,但采用单目方案——一块600×600像素的屏幕只置于右侧镜片,只能呈现2D效果。
这不只是参数层面的差异。单目显示的根本问题在于不对称:你的右眼在看屏幕,左眼在看现实,大脑需要持续协调两个不同的视觉输入,长时间使用极易引发眼部疲劳,部分用户甚至会出现眩晕症状。双目显示从根本上消除了这个问题——两眼都能看到信息,视觉负担大幅降低。
在实际体验里,这个差异在"逛展看画"和"会议同传"两个场景里体现得最明显。字幕出现在双眼视野里和只出现在右眼里,是完全不同的信息获取体验。
续航策略:热插拔vs物理失联
千问S1采用热插拔双电池设计,配合便携换电仓,在不关机、不中断音频和服务的情况下瞬间换电,真正实现全天候不断电。Ray-Ban Meta Display内置不可拆卸电池,电量耗尽后必须摘下放回充电盒,存在强制"物理失联"的使用断点。
对于主打"主动服务全天候"的产品来说,这个设计差异直接决定了产品承诺的可信度。你不可能对一副需要定时充电、强制摘下的眼镜建立"它一直在"的信任感。
06
53%之后:阿里千问真正想做的是什么
销量第一只是入场券
自3月8日正式开售以来,千问AI眼镜线上累计销量已超过国内AI眼镜市场总份额的53%,位居绝对头部。
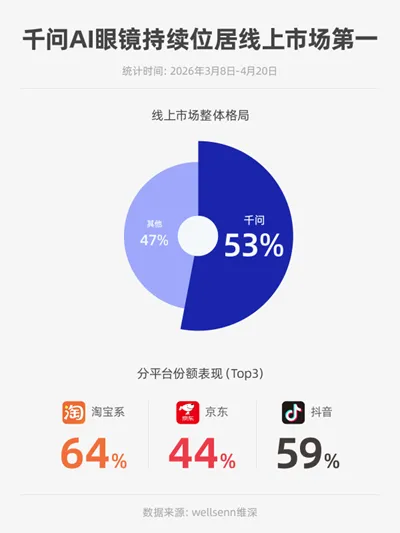
但在科技行业,销量第一只是留在牌桌上的入场券。透过S1这轮升级,我们清楚地看到,阿里的野心远不止于此。千问真正想做的,是下一个"物理世界的AI索引入口"——一个能够持续获取用户第一视角、实时生活数据的连接节点。
这个定位背后有一个关键的数据逻辑:每一次用户用眼镜问路、识物、翻译、支付,都在帮助千问大模型理解用户的真实生活语境。这是手机APP的交互日志无法比拟的数据质量——第一人称视角、实时发生、多模态感知,且用户处于主动使用状态而非被动刷屏。这些数据将成为阿里AI能力迭代最稀缺的燃料,也是AI眼镜这个品类对巨头们真正的战略价值所在。
生态开放:自留地,还是公共市场?
当被问及千问眼镜未来的生态边界时,晋显的回答颇具深意。
硬件接口:时机未到,并非不开放
在他看来,硬件开放的核心障碍不是意愿,而是时机。AI眼镜目前仍处于渗透初期,整体设备保有量有限——在这个规模下,即便将硬件接口对外开放,第三方开发者算一算ROI也很难跑通,投入转化的积极性自然不高。与其过早开放却换来一片冷清,不如先把设备保有量做上去。
"我们并没有说现在就主动把硬件接口做开放。但当有了一定市占、一定设备保有量之后,我觉得是有可能的。"
他也坦言,从长期来看,硬件本身并非千问眼镜的终极护城河——随着产业链成熟,关键器件的可获得性提升,类似架构的产品迟早会出现。真正的核心竞争力,始终是整套AI解决方案,是"AI生活助理"这个定位本身。
软件生态:从重度自研到平台开放
软件侧的逻辑分两个阶段理解。
第一阶段,千问选择了重度自研。这个阶段的首要任务是"为AI眼镜正名"——验证市场、打造标杆场景。如果过早引入研发资源有限的第三方,一旦体验接不上用户期待,口碑崩塌的代价远大于开放带来的收益。即便如此,晋显坦言目前依然面临严峻压力,现有功能仍需持续打磨。
第二阶段,平台开放的时机正在临近。随着特定场景、特定人群、特定行业的差异化需求不断涌现,全靠自己重度研发既跑不过时间,也撑不住投入。目前团队已完成眼镜近端、APP移动端、云端能力的全面梳理,SDK规划已从定义层面落地,正进入快速开发周期。
"未来无论是各种应用、Agent,还是广场、商店,我们都会持续做好版本管理和开发者激励,把基于千问AI眼镜的开发成本和周期压缩到最低。"
两段话合在一起,是同一套产品哲学的延伸:在规模与生态之间,千问选择先把规模做扎实,再把门打开。
06
结语
离开上海前滩中心的时候,我从便携换电仓里抽出一块满电电池,顺手完成了热插拔,眼镜里的音乐会继续播放。
这个细节,某种程度上是千问S1的缩影:硬件躯壳还是熟悉的配方,但整套系统运转的方式,正在悄然改变。
从"你问我答"到"主动读心",从二维贴纸到双目3D呈现,从单一设备到开放生态的野心——千问S1的这轮升级,走的是一条激进且代价清晰的路:用更高的工程复杂度和功耗预算,换取更接近"真正懂你的助理"而非"智能配件"的产品体验。
这条路走得通吗?现在下结论还为时尚早。主动服务的分寸感需要在数百万用户的真实生活里被校准,生态开放的承诺需要开发者社区用脚投票来验证。这些都不是靠一次软件升级能解决的问题。
但至少,在AI眼镜赛道百镜大战、大多数参与者还在用堆摄像头规格和低价抢市场的当下,千问S1提出了一个更有价值的问题:
一副眼镜,什么时候才算真的"懂你"?





