 夜雨聆风
夜雨聆风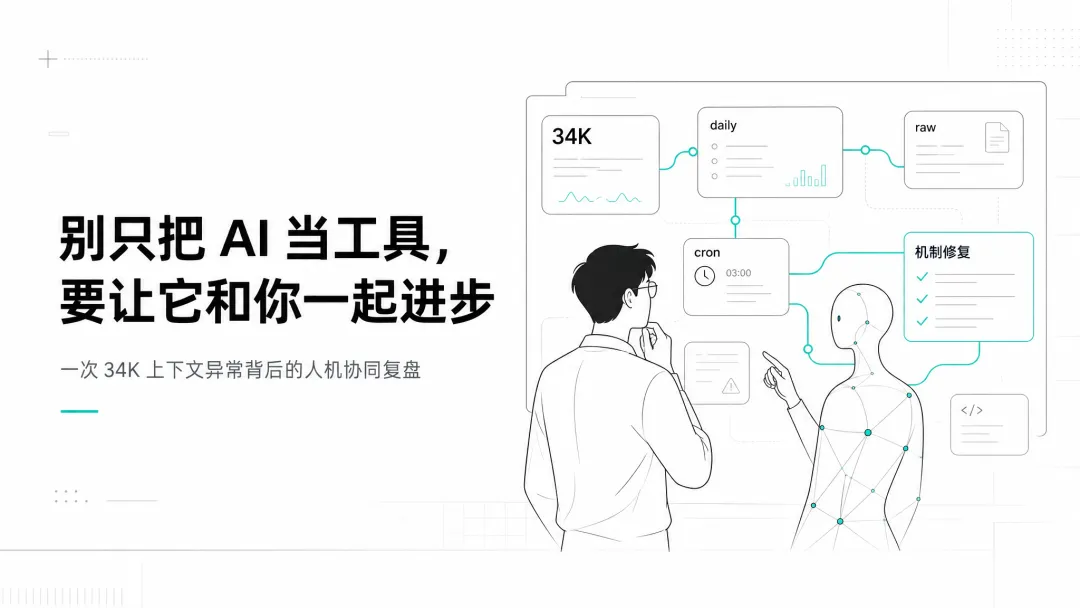
一次 34K 上下文异常背后的人机协同复盘
有些问题,机器不会主动觉得“不对劲”。但人会。
很多人用 AI,只把它当成一个执行工具:让它写、让它查、让它画、让它自动跑。
但今天这件小事让我更确定一件事:
真正好用的 AI 助手,不只是替你干活,而是能在一次次协作里,和你一起变得更可靠。
今天发生的事很小,但很值得记录。
不是一个宏大的技术突破,也不是某个模型突然变强了。
只是我在开了一个新会话之后,发现系统自带上下文大概有 34K。
按理说,这个数字不算特别离谱。
但是我隐约觉得不对。
因为这两天我们刚刚做过几件事:
- Image 2 工厂做了模板索引和结构化;
- 公众号发布工作台做了流程化;
- 图片输出目录做了归档规则;
- memory / daily / raw / topics 做过分层治理;
- 一些长过程本来应该被放进 raw,而不是继续压在 daily 里。
所以我的直觉是:
如果结构化做对了,默认启动上下文应该更干净,而不是更重。
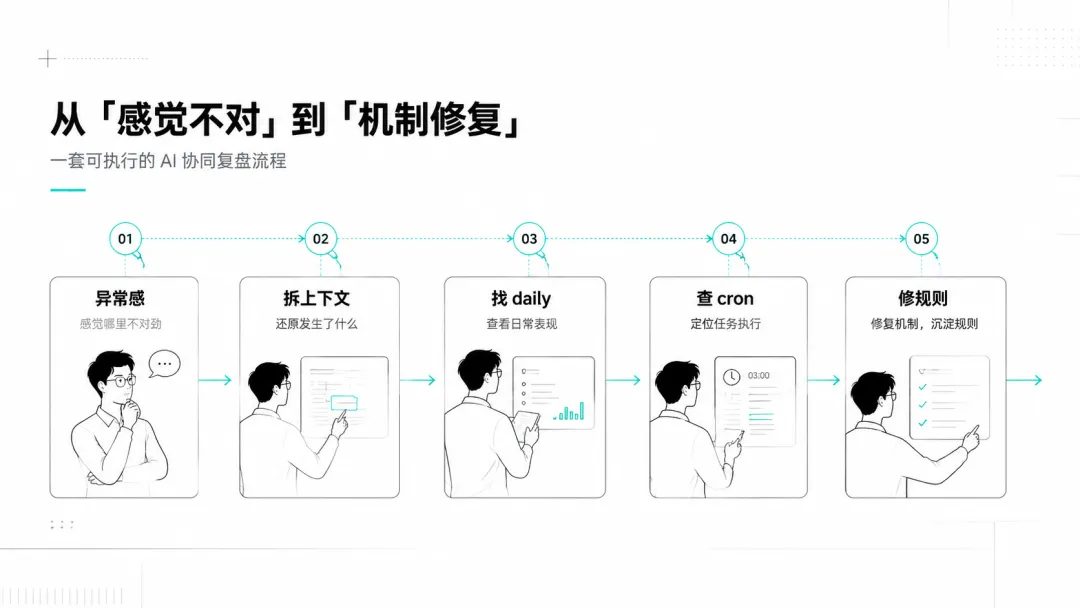
这就是今天这次人机协同的起点。
它不是一次“我下命令,AI 执行”的过程。
更像是一次共同复盘:人先感觉到异常,AI 负责查证和执行,最后我们一起把问题沉淀成更可靠的机制。
异常不是报错,而是“感觉不对”
很多系统问题不是以红色错误弹窗出现的。
它不会告诉你:
你好,我的记忆归档策略出问题了。
它只会在某个地方露出一点痕迹。
这次的痕迹就是:
`/new` 后,系统自带上下文仍然有 34K 左右。
如果只看数字,它可以被解释为正常:
- 有系统规则;
- 有工具说明;
- 有技能列表;
- 有 workspace 注入文件;
- 有长期 memory;
- 有今天和昨天的 daily;
- 还有 Telegram / runtime 元数据。
这些确实都会占上下文。
但是问题在于:
昨天还是 32K 左右,今天为什么变成 34K?
这 2K 的变化不大,但方向不对。
尤其是在我们刚做完结构化治理之后,人的直觉会冒出来:
不应该啊。
这三个字很重要。
在很多人机协同场景里,真正的起点不是命令,而是人的“不应该”。
机器第一次也会理解错
我一开始说:
默认都 34K。
AI 助手一开始理解成:
把默认上下文 / 输出参数都改成 34K。
于是它真的去改了配置。
这就是机器很典型的一种问题:
它很会执行,但有时会过早执行。
人的一句话可能是描述问题,也可能是下指令。机器如果没分清,就容易把“我要你解释”理解成“我要你修改”。
这一步其实也很真实。
人机协同不是机器永远正确,也不是人永远说得清楚。
更像是:
- 人发现方向不对;
- 机器先尝试理解;
- 理解错了,人纠偏;
- 机器承认并回滚;
- 然后继续排查。
这套过程,比“机器一次性完美完成任务”更接近真实工作。
后来配置被恢复到 200K,上下文上限回到正常。
但这只是表层问题。
真正的问题还没开始。
第一轮排查:34K 由什么组成?
接下来,我们先拆 `/new` 后系统自带上下文到底由什么组成。
大概包括:
1. OpenClaw 的系统 / 开发者规则;
2. 工具使用规则;
3. skills 列表;
4. workspace 注入文件;
5. `AGENTS.md`、`SOUL.md`、`USER.md`、`TOOLS.md`、`MEMORY.md`;
6. today / yesterday daily;
7. runtime、Telegram、session 元数据;
8. 当前会话里已经发生的消息;
9. 工具调用结果。
这一步给出了一个基本判断:
`/new` 清的是聊天历史,不清系统底座。
所以 34K 并不神秘。
但人的第六感仍然有价值:
组成合理,不代表增长合理。
于是我们继续追问:
昨天是 32K,今天多出来的是什么?
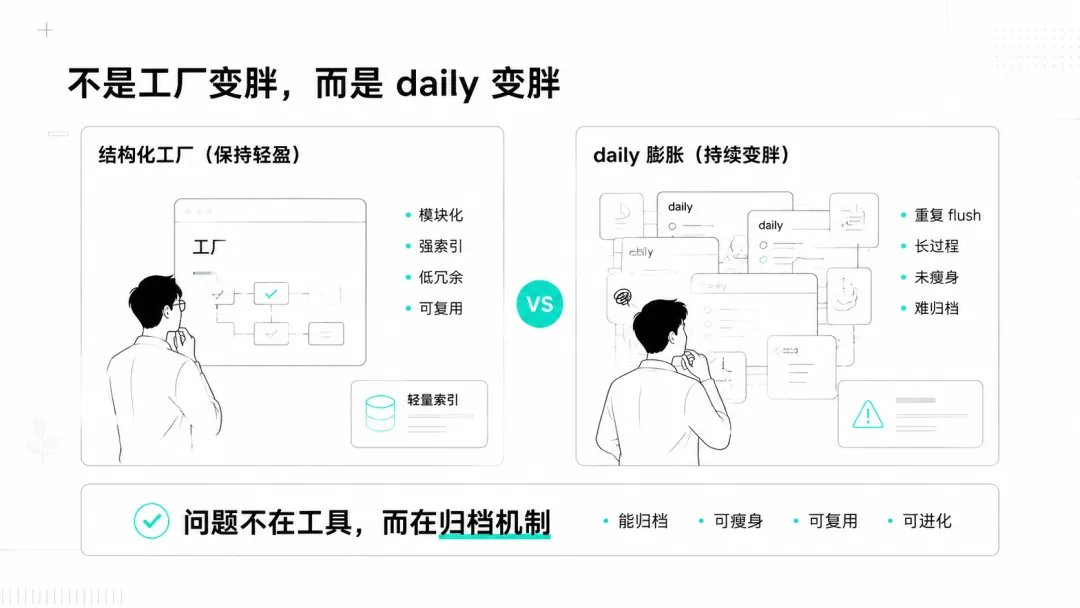
第二轮排查:不是工厂变胖,而是 daily 变胖
我们查了各个常驻文件的大小。
真正可疑的是昨天的 daily 文件。
`memory/daily/2026-05-07.md` 接近 28K 字符。
这就很反常。
因为按照我们之前定的规则:
- `daily/` 只应该记录当天发生了什么、定了什么、还有什么要跟进;
- 详细过程应该进入 `raw/`;
- 可复用规则应该进入 `topics/`;
- 长期硬规则才进 `MEMORY.md`。
也就是说,daily 应该是轻日志,不是大仓库。
但昨天的 daily 里出现了几个明显信号:
- 有 imported-from-memory-root 标记;
- 有重复的 durable memory flush 区块;
- 有大量过程细节;
- 已经迁移到 raw / topics 的内容,还留在 daily 里。
这时问题就清楚了一半:
Image 2 工厂的模板索引没有变胖,公众号工作台也不是主要原因。真正变胖的是 daily。
换句话说:
结构化工具本身做对了,但记忆归档的收尾没做干净。
第三轮排查:为什么规则没生效?
这一步是最关键的。
因为如果只是发现 daily 变胖,那还只是清理文件。
真正要问的是:
为什么明明有规则,最后还是没按规则归档?
继续往下查,发现有一个每天早上的 cron 任务:
memory-root-md-auto-classify
每天 07:15
它的目标是好的:
检查 memory 根目录有没有跑偏的 markdown 文件,并归位到合适目录。
但旧 prompt 里有一句危险规则:
明确是日期日志 / 当天流水的,移动或合并到 memory/daily/YYYY-MM-DD.md。
问题就在这里。
它只说了“合并到 daily”,但没有说清楚:
- 先备份;
- 长过程进 raw;
- daily 只能留摘要;
- 不能全文倒入 daily;
- 重复 flush 要去重;
- daily 超过阈值要瘦身;
- 可复用规则要进 topics。
于是这个自动任务就按照字面意思,把一些 root 临时文件合并进了 daily。
它没有恶意。
它只是太听话了。
这其实是自动化系统里非常常见的问题:
自动化不是不需要规则,而是更需要精确规则。
规则写得粗,机器就粗暴执行。
规则写得细,机器才有可能稳定执行。
第四轮排查:横向检查 5 月和 4 月
问题不能只处理 5 月 7 日。
因为一旦发现机制有漏洞,就要横向扫一遍。
我们继续检查 5 月每天的 daily。
结果发现:
- 5 月 7 日:约 28K,已明显膨胀;
- 5 月 6 日:约 18.6K,也明显过长;
- 5 月 5 日:约 7.3K,有两个 durable flush 区块;
- 其他日期基本健康。
于是我们做了处理:
- 5 月 7 日 daily 从 27.8K 瘦到 3.4K;
- 5 月 6 日 daily 从 18.6K 瘦到 3.5K;
- 5 月 5 日 daily 从 7.3K 瘦到 2.2K;
- 完整原文全部保存在 raw;
- 精确备份也保存在 raw/misc;
- daily 只保留摘要和指针。
然后再查 4 月。
4 月没有发现同类膨胀:
- memory 根目录没有 4 月日期型 md;
- April daily 文件体量整体健康;
- 没有重复 durable flush;
- 没有 imported root 膨胀。
这一步很重要。
因为它把问题范围缩小了:
不是整个 memory 系统长期失控,而是 5 月某几天在 cron 自动归档规则下出现了局部偏差。
最后不是只清理,而是修机制
如果只把 daily 瘦下来,问题还会回来。
所以最后一步是修 cron。
新的规则变成:
- `memory/YYYY-MM-DD.md` 只视为临时落点;
- 日期型 root 文件必须先备份;
- 会话摘要、过程记录、flush 大段文本进 raw;
- daily 只保留 3~10 条摘要和 raw 指针;
- 如果 daily 超过 12K,或者有重复 durable flush,就必须备份后瘦身;
- 可复用规则进 topics;
- 不确定的内容进 raw/misc;
- 不要把 flush 指令里的路径当成最终目录规则。
这才是真正的解决。
不是“清了一次文件”,而是把下一次自动化的行为边界写清楚。
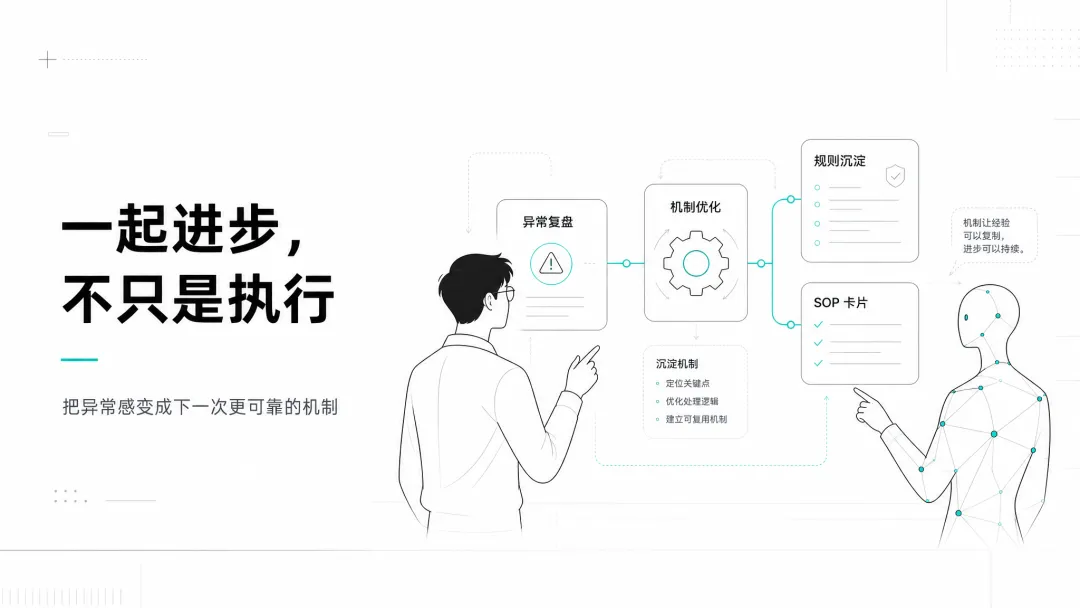
别只让 AI 执行,要让它参与改进
这件事小吗?
从表面看,很小。
就是一次 `/new` 后上下文数字异常,一次 memory daily 清理,一次 cron prompt 修正。
但从协作方式看,它很典型。
整个过程其实是这样的:
1. 人先发现异常。
不是因为系统报错,而是因为人对整体结构有感觉。
2. 机器快速排查。
它可以查文件、查 cron、查 daily、查大小、查重复区块。
3. 人继续补充历史线索。
“是不是早上的 cron 没按标准处理?”这句话直接把排查方向推进了一层。
4. 机器再次验证。
查到 cron 旧规则确实存在漏洞。
5. 最后一起修机制。
清理旧数据,更新自动任务规则,留下可复查的 raw 证据。
这就是人机协同的价值。
如果 AI 只是在执行命令,它最多是一个更快的工具。
但如果它能参与排查、复盘、修正、沉淀规则,它就开始变成一个会和你一起进步的协作者。
人不是只负责提需求。
机器也不是只负责执行命令。
更好的模式是:
人提供判断、直觉、目标和纠偏;机器提供检索、验证、执行和固化。
这两者缺一不可。
为什么“人的第六感”仍然重要?
很多人讨论 AI 时,喜欢问:
AI 能不能替代人?
但今天这个案例说明,至少在复杂系统里,更好的问题应该是:
人和 AI 怎么一起发现单独一方都不容易发现的问题?
如果只有人,可能会觉得不对,但很难快速翻遍:
- memory 文件;
- daily 文件;
- raw 证据;
- topics 规则;
- cron 任务;
- 配置变更;
- 自动任务 prompt。
如果只有机器,它可能会机械解释:
34K 是系统规则、技能列表、memory 和元数据组成的,属于正常。
但人会追问:
可是昨天还是 32K,而且我们刚做了结构化,为什么反而更重?
这个问题很值钱。
因为它不是一个事实查询,而是一个系统判断。
这种判断来自经验,也来自对目标状态的感觉。
今天的问题,就是被这种感觉抓出来的。
这件小事给我的启发
这次我最大的感受是:
AI 系统越复杂,越需要人保留“异常感”。
不要因为机器能跑,就默认它跑对了。
不要因为自动任务显示 ok,就默认它真的符合你的规则。
不要因为文件都被归档了,就默认归档层级是对的。
真正可靠的系统,不是没有问题。
而是:
- 人能感觉到异常;
- AI 能快速查证;
- 查出来能承认;
- 承认后能修正;
- 修正后能沉淀成规则。
这才是个人 AI 助手真正有价值的地方。
它不是一个“听话工具”。
它更像一个和你一起维护复杂系统的协作者。
当然,人也不能完全放手。
因为很多关键问题,机器不会主动觉得“不对劲”。
它需要人说一句:
等等,这不太对。
然后它才能顺着这句话,把问题刨到底。
结尾
今天这次排查,不是一次技术事故。
更像是一次很好的协同样本。
人发现异常,机器验证异常。
人补充历史线索,机器定位机制漏洞。
人决定处理标准,机器执行清理和修复。
最后,系统变得更干净,规则变得更明确,下一次自动化也更可靠。
所以我越来越觉得:
好的 AI 助手,不是替代人的判断,而是在协作中放大人的判断,并把一次次问题变成下一次更好的机制。
而好的人机协同,也不是人把一切都交给机器。
是人和机器一起,把那些“好像哪里不对”的感觉,变成可验证、可修复、可沉淀的系统改进。
这才是 AI 真正进入日常工作后的样子。
不是炫技。
也不是单纯提效。
而是一起把事情做对,并且下一次做得更好。
延伸到团队管理,也是同一个道理。
好的管理者,不是只让团队执行任务,而是在系统看似正常时仍能察觉异常、提出关键问题、组织复盘,并带着团队把一次偶然的问题,沉淀成下一次更可靠的机制。
带 AI 是这样,带团队也是这样:别只把对方当工具,要让TA和你一起进步。
