夜雨聆风
夜雨聆风【龙虾养殖小白逆袭记】:10分钟教你快速上手Workbuddy AI 智能体
【龙虾养殖小白逆袭记】:10分钟教你快速上手Agent Skill,从零基础到实战高手!导读:你有没有想过,超市里的智能收银台怎么认出商品?自动驾驶汽车怎么"看"到行人?安防摄像头怎么识别入侵者?答案就在本文——YOLO11 目标检测。更厉害的是,结合 AI 编程助手 WorkBuddy,完全不写代码也能让 YOLO11 自动运行并给出分析报告!
导读:你有没有想过,超市里的智能收银台怎么认出商品?自动驾驶汽车怎么"看"到行人?安防摄像头怎么识别入侵者?答案就在本文——YOLO11 目标检测。更厉害的是,结合 AI 编程助手 WorkBuddy,完全不写代码也能让 YOLO11 自动运行并给出分析报告!
一、先搞清楚:"目标检测"到底是什么?
很多人听到"目标检测"就觉得高深莫测。其实,用一句大白话解释就是:
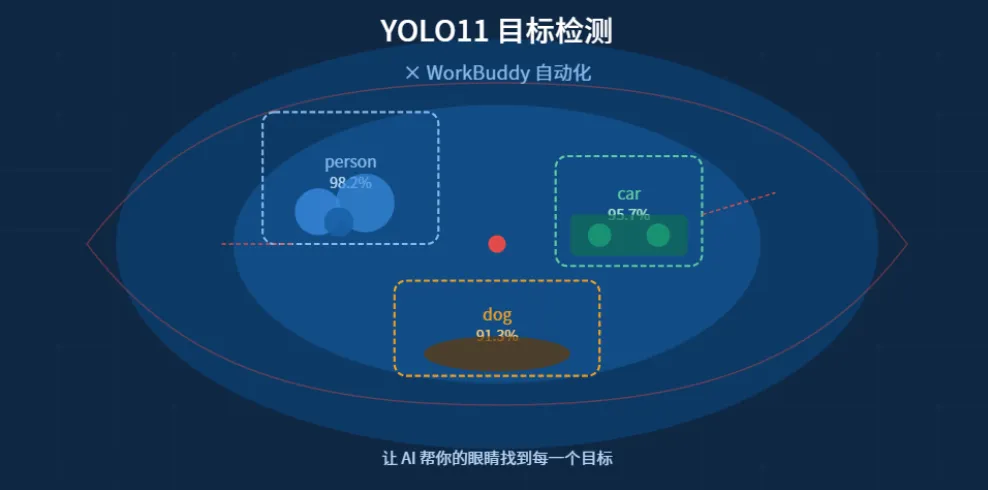
让计算机在一张图片或视频里,找出所有感兴趣的物体,告诉你"它在哪儿",还有"它是什么"。
你眼睛能看到的,目标检测模型基本也能"看到"——人、车、猫、狗、瓶子……甚至是 X 光片里的病灶。
目标检测输出的是什么?
每次检测,模型会给你三样东西:
| 边界框(BBox) | ||
| 类别标签(Label) | ||
| 置信度(Confidence) |
二、YOLO 是什么?为什么用它?
YOLO 是 You Only Look Once 的缩写,翻译过来就是——只看一眼。
这个名字精准描述了它的核心思想:
传统检测方法需要先"扫描"图片多遍找候选区域,再逐个分类,速度慢。 YOLO 把这两步合并成一步,一次前向传播就把所有目标检测出来,速度极快。
YOLO 的发展历史
2016年 YOLO v1 —— 开创性地提出"一次看完"思路
2017年 YOLO v2 —— 增加锚框,精度大幅提升
2018年 YOLO v3 —— 多尺度检测,能找小目标
2020年 YOLO v4/v5 —— 工程化更成熟,社区爆火
2022年 YOLO v8 —— Ultralytics 全面重构
2024年 YOLO11 —— 最新版本,更轻更快更准 ✨
YOLO11 vs 前代:哪里更强?
YOLO11 是 Ultralytics 于 2024 年发布的,主要升级点:
C3k2 模块:新型卷积单元,参数更少但特征更丰富 SPPF + C2PSA:空间金字塔池化 + 注意力机制,多尺度感知更强 推理速度更快:在相同精度下,推理速度比 YOLO v8 快约 2%,参数量减少约 22% 支持五大任务:目标检测、实例分割、图像分类、姿态估计、旋转目标检测
三、YOLO11 怎么工作的?(图解版)
YOLO11 把一张图片"看完"分三步:
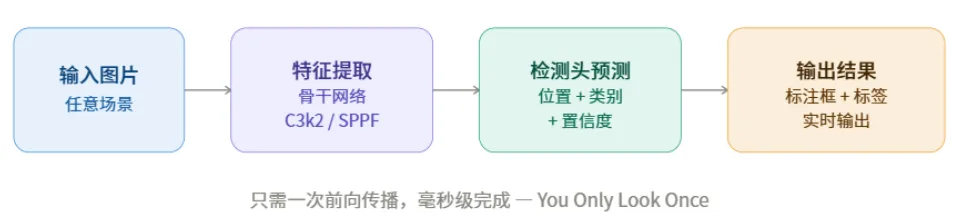
第一步:骨干网络提取特征
图片进入模型后,先经过一系列卷积层,把图片"压缩"成高维特征图。你可以理解成:把一张照片抽象成一堆数学特征,记住"这里有条边"、"那里有个圆弧"……
关键结构:C3k2 模块(改进的瓶颈结构)+ SPPF(空间金字塔池化)
第二步:颈部网络融合多尺度信息
大物体(如卡车)在粗粒度特征图里看得清;小物体(如行人、远处的小猫)在细粒度特征图里才能找到。颈部网络把不同尺度的特征图拼合在一起,确保大小目标都不漏。
第三步:检测头输出预测
最终,检测头在特征图的每个位置预测:这里有目标吗?是什么?在哪儿?有多确定?
整个过程只需一次前向传播,图片分辨率 640×640 时,现代 GPU 可达 100+ FPS(帧/秒)!
四、YOLO11 能干什么?(应用场景)
目标检测是计算机视觉最核心的应用之一,YOLO11 在以下场景中大放异彩:
安防监控
人脸 + 人体检测,识别入侵 人群密度分析 行为异常预警(摔倒检测、翻越围栏)
自动驾驶
实时检测行人、车辆、信号灯、标志牌 毫秒级响应,保障行驶安全
工业质检
产品外观缺陷检测(划痕、裂缝、异物) 生产线零件计数与分类
医疗影像
CT/X 光片中的病灶定位 皮肤病变检测
零售与物流
商品识别与自助结算 快递包裹分拣自动化
农业
作物病虫害识别 果实成熟度检测与采摘引导
五、YOLO11 模型怎么选?
YOLO11 提供五个尺寸版本,从小到大,精度和速度各有侧重:
| 最常用 | ||
小白建议:从
yolo11n.pt或yolo11s.pt开始,熟悉之后再换更大模型。
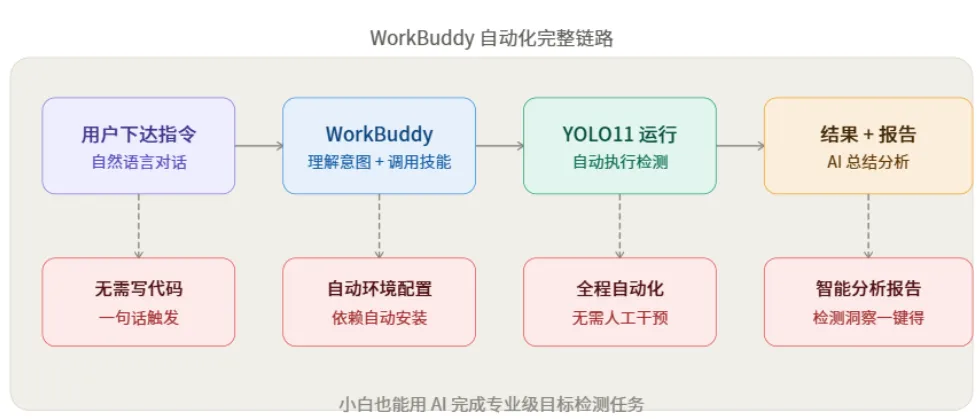
六、WorkBuddy 是什么?为什么要结合它用?
WorkBuddy 是一款 AI 编程与工作助手,最大的特点是:
💬 自然语言对话驱动:你说要干什么,它负责写代码、装依赖、运行、返回结果 🛠️ 内置技能市场:YOLO11 检测已经是预置技能,无需手动配置 🤖 自动化调度:可以设置定时任务,让它每天自动跑检测、生成日报 📊 智能分析报告:检测完成后,AI 自动总结"检测到了什么、数量、置信度分布"等洞察
一句话:YOLO11 是工具,WorkBuddy 是会用工具的人。
七、YOLO11 Skills:用 WorkBuddy 自动生成 YOLO11 Skills
使用skill开发生成YOLO11 Skills
由于使用YOLO11进行目标检测及对使用检测结果对原图进行标准的代码比较复杂,对于python小白技术门槛太高,所以从零开始写YOLO11 Skills是不太现实的。我们直接在Workbuddy代码开发模式中输入以下指令用Skill开发生成:
提交执行完毕后,将在C:\Users\用户名\.workbuddy\skills\自动生成一个yolo11-detector的目标检测技能,目录如下:
-yolo11-detector
--references
--scripts
--SKILL.md
在scripts目录中有一个run_detection.py脚本,用于进行目标检测并对处理结果。代码内容如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
YOLO11 目标检测脚本
使用 Ultralytics YOLO11 模型进行目标检测,输出结构化结果。
通过 Anaconda base 环境运行。
用法:
python run_detection.py --source <图片/视频/目录路径> [选项]
示例:
python run_detection.py --source image.jpg
python run_detection.py --source images/ --model yolo11n.pt --conf 0.3
python run_detection.py --source 0 # 摄像头实时检测
python run_detection.py --source video.mp4
"""
import argparse
import sys
import os
import json
from pathlib import Path
def check_dependencies():
"""检查并提示安装所需依赖"""
missing = []
try:
import ultralytics
except ImportError:
missing.append("ultralytics")
try:
import cv2
except ImportError:
missing.append("opencv-python")
if missing:
print("[错误] 缺少依赖包,请在 Anaconda base 环境中执行以下命令安装:")
print(f" pip install {' '.join(missing)}")
print("\n推荐在 Anaconda base 环境中安装:")
print(" D:\\Program\\anaconda3\\python.exe -m pip install ultralytics opencv-python")
sys.exit(1)
def run_detection(
source: str,
model_path: str = "yolo11n.pt",
conf: float = 0.25,
iou: float = 0.45,
save_img: bool = True,
save_txt: bool = False,
save_json: bool = True,
show: bool = False,
classes: list = None,
device: str = "",
project: str = "runs/detect",
name: str = "result",
):
"""
运行 YOLO11 目标检测
Args:
source: 输入源(图片路径/目录/视频/摄像头编号)
model_path: 模型权重文件路径
conf: 置信度阈值
iou: IOU 阈值(NMS 用)
save_img: 是否保存标注后的图片
save_txt: 是否保存检测结果为 .txt
save_json: 是否保存检测结果为 JSON
show: 是否弹出窗口显示(无 GUI 环境设为 False)
classes: 过滤类别(None 表示检测所有类别)
device: 推理设备("" 自动选择,"cpu","0" 表示 GPU 0)
project: 输出根目录
name: 输出子目录名称
"""
from ultralytics import YOLO
print(f"[INFO] 加载模型: {model_path}")
model = YOLO(model_path)
print(f"[INFO] 开始检测,输入源: {source}")
results = model.predict(
source=source,
conf=conf,
iou=iou,
save=save_img,
save_txt=save_txt,
show=show,
classes=classes,
device=device if device else None,
project=project,
name=name,
exist_ok=True,
verbose=True,
)
# ---- 汇总输出 ----
summary = []
for i, result in enumerate(results):
frame_info = {
"frame": i,
"image_path": str(result.path) if hasattr(result, "path") else "",
"image_shape": list(result.orig_shape),
"speed_ms": result.speed,
"detections": [],
}
if result.boxes is not None and len(result.boxes) > 0:
boxes = result.boxes
names = model.names
for j in range(len(boxes)):
cls_id = int(boxes.cls[j].item())
conf_val = float(boxes.conf[j].item())
xyxy = boxes.xyxy[j].tolist()
xywh = boxes.xywhn[j].tolist() # 归一化 xywh
det = {
"id": j,
"class_id": cls_id,
"class_name": names[cls_id],
"confidence": round(conf_val, 4),
"bbox_xyxy": [round(v, 2) for v in xyxy],
"bbox_xywhn": [round(v, 4) for v in xywh],
}
frame_info["detections"].append(det)
summary.append(frame_info)
# ---- 控制台打印 ----
print("\n" + "=" * 60)
print(" YOLO11 目标检测结果汇总")
print("=" * 60)
total_dets = sum(len(f["detections"]) for f in summary)
print(f"处理帧数: {len(summary)}")
print(f"总检测数: {total_dets}\n")
for frame in summary:
print(f"[帧 {frame['frame']}] {os.path.basename(frame['image_path'])}")
print(f" 图像尺寸: {frame['image_shape']}")
spd = frame["speed_ms"]
if isinstance(spd, dict):
print(f" 推理耗时: preprocess={spd.get('preprocess', 0):.1f}ms "
f"inference={spd.get('inference', 0):.1f}ms "
f"postprocess={spd.get('postprocess', 0):.1f}ms")
if frame["detections"]:
print(f" 检测到 {len(frame['detections'])} 个目标:")
for det in frame["detections"]:
print(f" [{det['id']+1}] {det['class_name']:20s} "
f"置信度: {det['confidence']:.2%} "
f"坐标(xyxy): {det['bbox_xyxy']}")
else:
print(" 未检测到目标")
print()
# ---- 保存 JSON ----
if save_json:
json_path = Path(project) / name / "detections.json"
json_path.parent.mkdir(parents=True, exist_ok=True)
with open(json_path, "w", encoding="utf-8") as f:
json.dump(summary, f, ensure_ascii=False, indent=2)
print(f"[INFO] JSON 结果已保存至: {json_path}")
# 保存路径
save_dir = Path(project) / name
if save_img:
print(f"[INFO] 标注图片已保存至: {save_dir}/")
print("\n[完成] 目标检测任务结束。")
return summary
def main():
parser = argparse.ArgumentParser(
description="YOLO11 目标检测脚本(通过 Anaconda base 环境运行)",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
示例:
python run_detection.py --source image.jpg
python run_detection.py --source images/ --model yolo11n.pt --conf 0.4
python run_detection.py --source video.mp4 --save-txt
python run_detection.py --source 0 --show # 摄像头实时检测
python run_detection.py --source image.jpg --classes 0 2 # 只检测人和车
Anaconda base 环境运行方式:
D:\\Program\\anaconda3\\python.exe run_detection.py --source image.jpg
""",
)
parser.add_argument("--source", required=True,
help="输入源:图片/视频路径、目录、摄像头编号(0)或 URL")
parser.add_argument("--model", default="yolo11n.pt",
help="模型权重路径(默认: yolo11n.pt,优先使用当前目录下的文件,不存在则自动下载)")
parser.add_argument("--conf", type=float, default=0.25,
help="置信度阈值(默认: 0.25)")
parser.add_argument("--iou", type=float, default=0.45,
help="NMS IOU 阈值(默认: 0.45)")
parser.add_argument("--device", default="",
help="推理设备:'' 自动 / 'cpu' / '0' GPU编号")
parser.add_argument("--classes", nargs="+", type=int, default=None,
help="过滤类别 ID,例如 --classes 0 1 2")
parser.add_argument("--save-txt", action="store_true",
help="同时保存 .txt 格式结果")
parser.add_argument("--no-save-img", action="store_true",
help="不保存标注图片")
parser.add_argument("--no-save-json", action="store_true",
help="不保存 JSON 结果")
parser.add_argument("--show", action="store_true",
help="弹窗显示检测结果(需要 GUI 环境)")
parser.add_argument("--project", default="runs/detect",
help="输出根目录(默认: runs/detect)")
parser.add_argument("--name", default="result",
help="输出子目录名称(默认: result)")
args = parser.parse_args()
check_dependencies()
run_detection(
source=args.source,
model_path=args.model,
conf=args.conf,
iou=args.iou,
save_img=not args.no_save_img,
save_txt=args.save_txt,
save_json=not args.no_save_json,
show=args.show,
classes=args.classes,
device=args.device,
project=args.project,
name=args.name,
)
if __name__ == "__main__":
main()
八、实战演示:用 WorkBuddy 自动运行 YOLO11
场景一:单张图片检测
在demo目录这种有一张dog.png图片:

只需在 WorkBuddy 对话框中输入:
帮我对这张图片(./demo/dog.png)进行 YOLO11 目标检测,使用./demo/yolo11n.pt 模型,输出标注结果和检测报告。
WorkBuddy 会自动:
检查 Anaconda 环境,安装 ultralytics依赖调用 YOLO11 模型对图片推理 保存带标注框的结果图 输出检测汇总:检测到几个目标、分别是什么、置信度多少
可见,已经调用YOLO11 的技能。

执行完成后将输出目标检测结果,并自动在当面目录中生成一个result文件夹用于存放生成的结果。
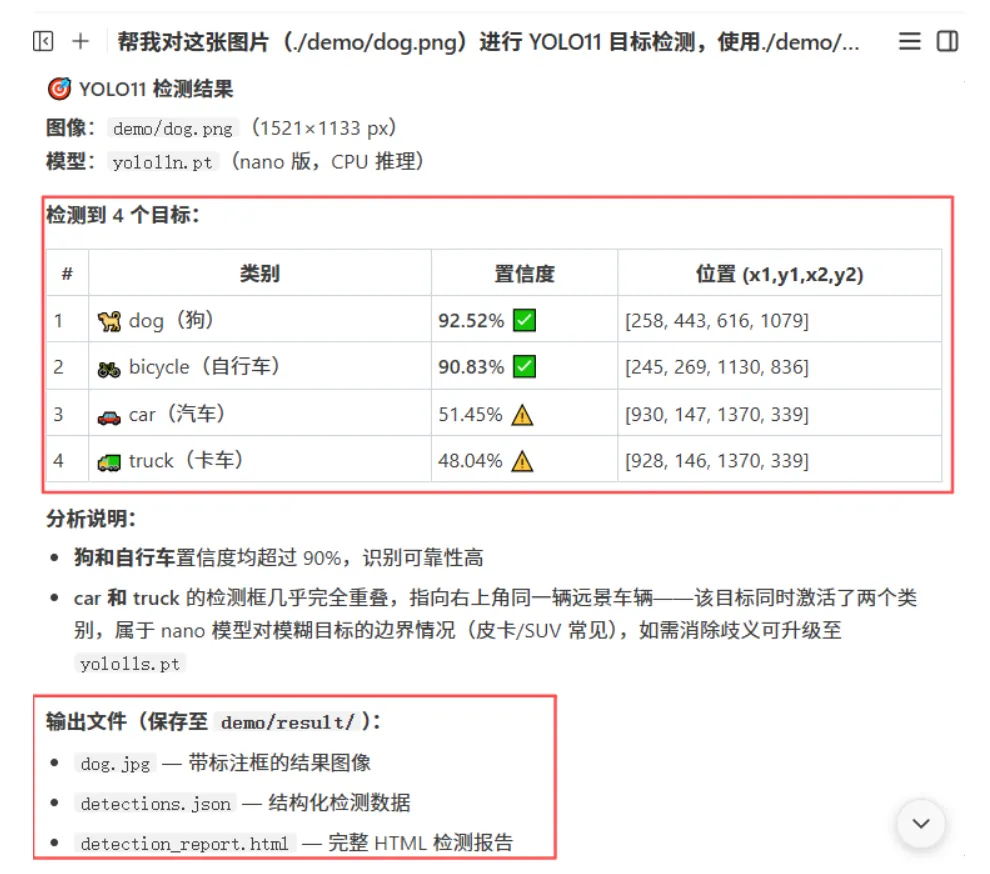
我们查看detection_report.html文件
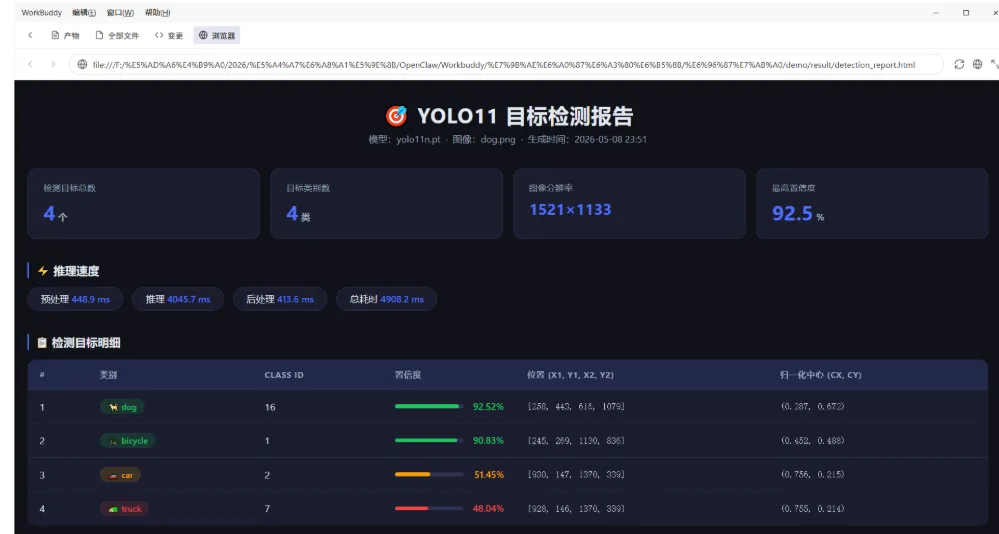
我们查看带标注结果的图片。
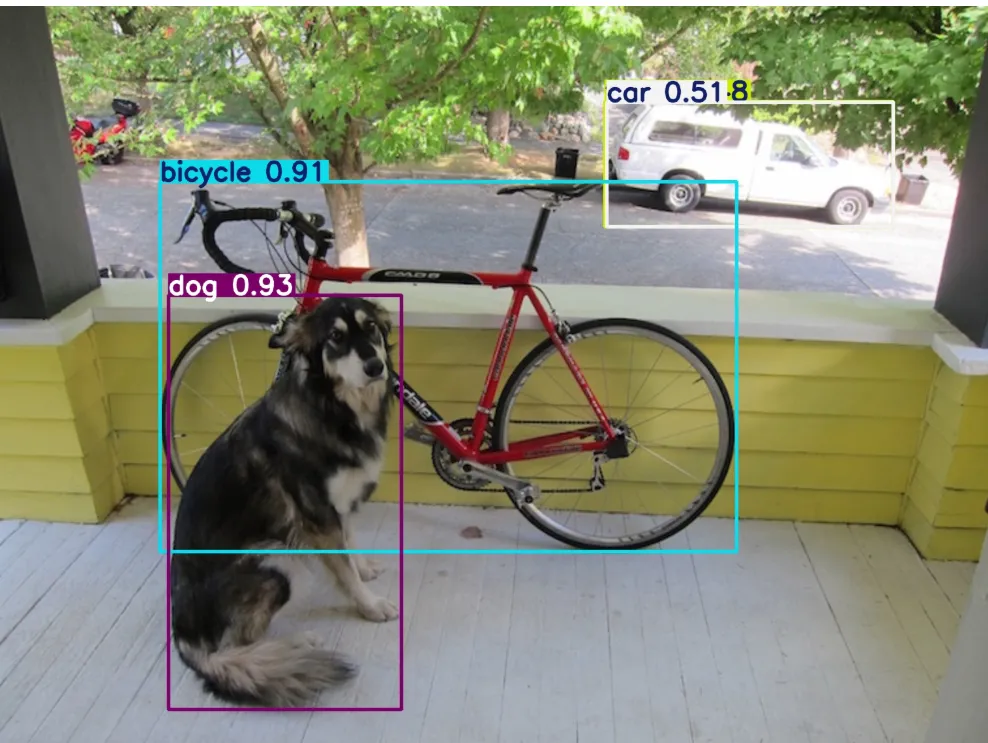
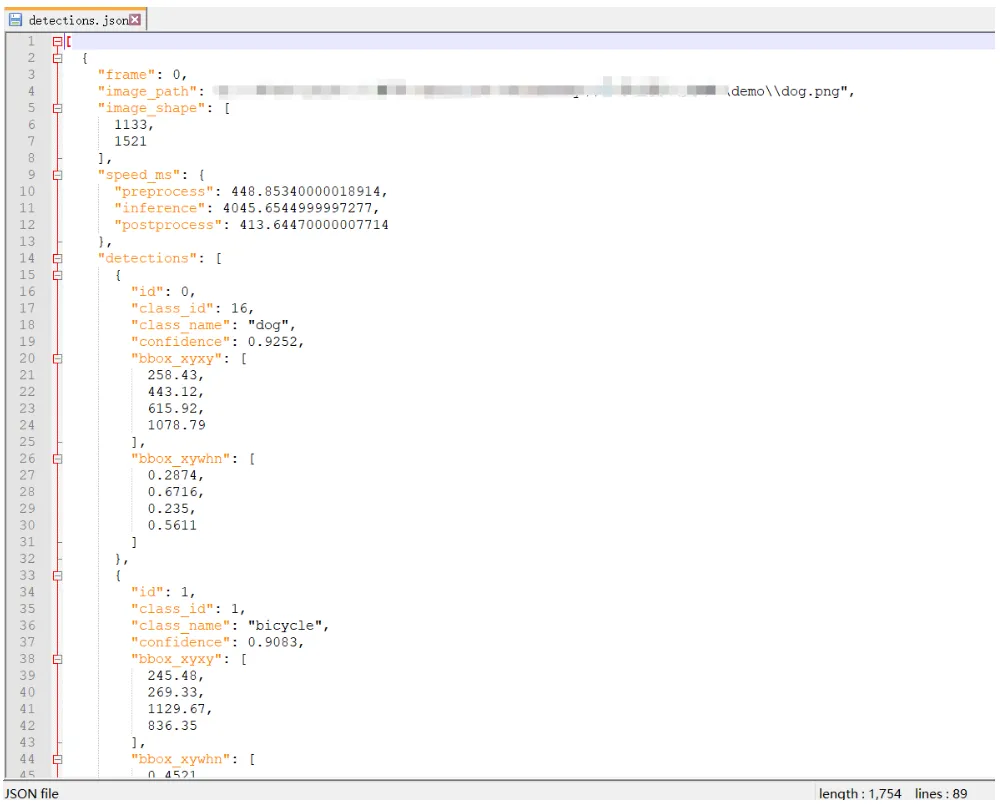
我们查看detections.json文件
场景二:批量图片检测
对 ./demo 目录下所有 png 文件进行 YOLO11 目标检测,使用./demo/yolo11n.pt 模型。统计每张图片中出现的目标类别和数量,生成 Excel 汇总报告
WorkBuddy 会自动:
遍历目录,逐个处理图片 汇总每章图片的检测结果 生成 Excel 格式的数据报告
执行结束后,将生成检测结果和yolo11_检测报告的Excel文件。
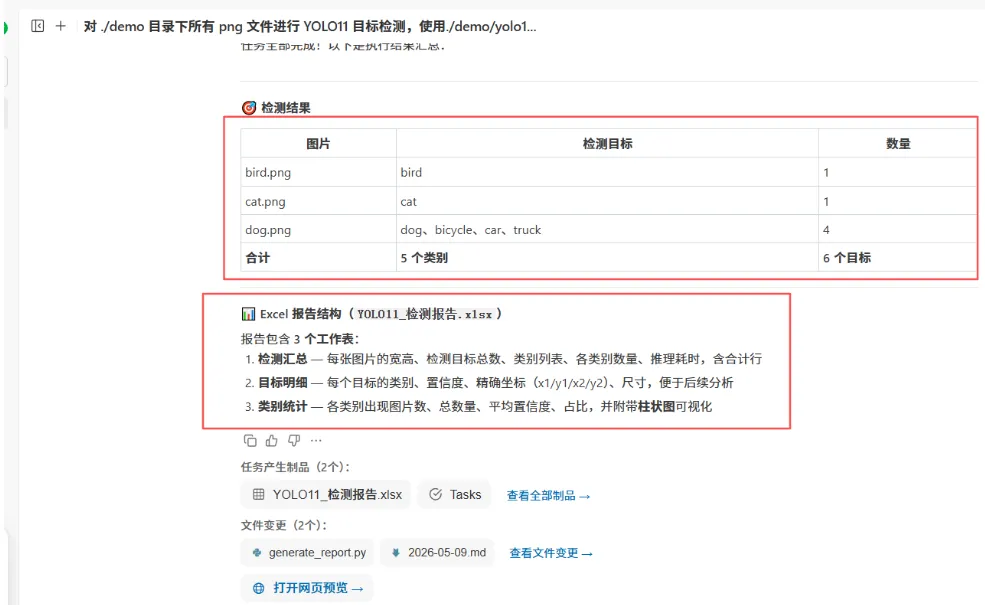
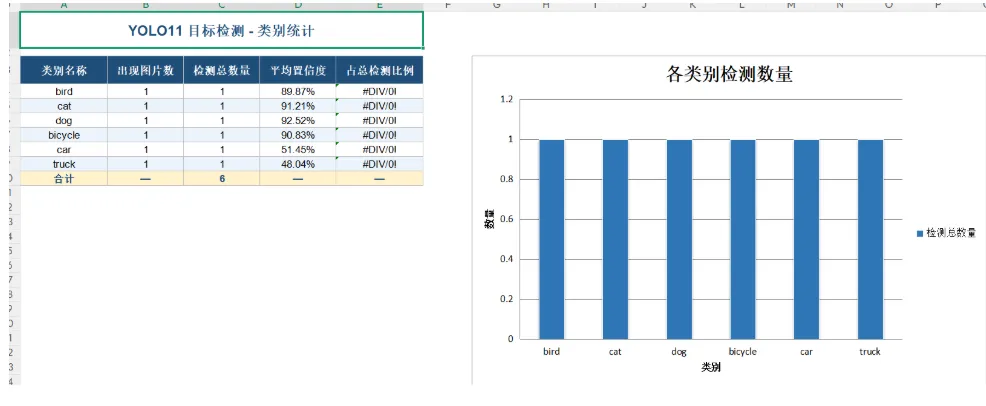
检测报告的检测汇总如下:
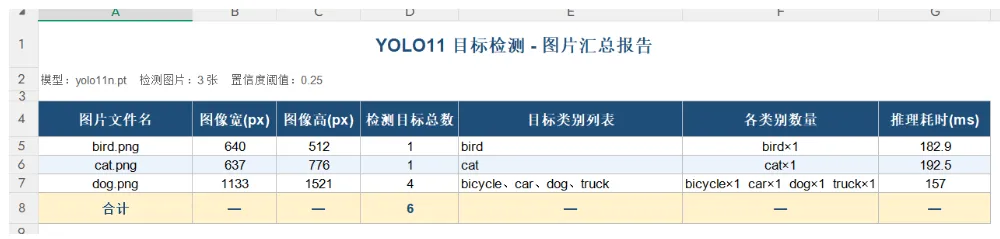
目标明细如下:
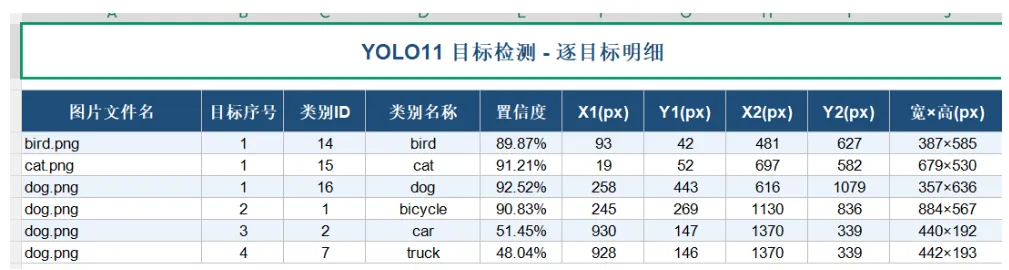
类别统计如下: