 夜雨聆风
夜雨聆风在 AI 视频生成的蛮荒时代,行业共识是 “带着镣铐跳舞”—— 版权数据是碰不得的红线,复杂场景是跨不过的鸿沟,专业制作是触不到的高塔。直到字节跳动扔下一颗重磅炸弹:Seedance 2.0,以 “敢为天下先” 的魄力,啃下版权影视数据训练的硬骨头,用碾压级的技术实力,重新定义 AI 视频生成的上限。当同行还在小心翼翼规避版权风险、在低质量生成中挣扎时,Seedance 2.0 已经带着 “导演级操控、电影级质感、工业化能力”,站在了行业金字塔的顶端。而那些试图追赶的对手,比如阿里的快乐马(Happy Horse),除了靠低价吸引流量,在核心技术、创作能力、生态壁垒上,根本没有与 Seedance 2.0 正面对抗的底气。这不是一场普通的技术迭代,而是一场由无畏者主导的、颠覆整个内容产业的革命。

一、无畏者的底色:撕开版权枷锁,才有的顶级质感
AI 行业永远有一个绕不开的终极命题:训练数据的质量,决定模型能力的上限。所有人都清楚,影视行业沉淀了百年的镜头语言、光影美学、叙事逻辑、动作设计,是训练视频生成模型最顶级的 “教材”。但百年版权壁垒如同一座高山,让所有玩家望而却步 —— 毕竟,触碰迪士尼、华纳、漫威等巨头的版权影视数据,无异于 “虎口拔牙”,面临的不仅是巨额赔偿,更是全球范围的业务封杀。
于是,行业形成了一种 “默契的妥协”:大家都用公开的、低质量的、碎片化的短视频数据训练模型。结果显而易见:生成的视频要么画面模糊、细节失真,要么动作僵硬、违背物理规律,要么镜头混乱、毫无叙事逻辑,更别说还原电影级的光影质感和情感张力。同行们一边抱怨 “模型能力天花板太低”,一边小心翼翼地在版权红线边缘试探,没人敢真正迈出那一步。
直到字节跳动带着 Seedance 2.0 入局,打破了这个 “心照不宣” 的僵局。
字节的选择简单而决绝:要做就做最好,要顶级质感,就必须啃下版权影视数据的硬骨头。没有犹豫,没有妥协,没有瞻前顾后,直接将海量版权影视数据纳入训练体系 —— 从好莱坞大片到国产经典,从院线电影到热门剧集,从动作大片到文艺片,几乎覆盖了影视行业所有的镜头类型、光影风格、叙事手法。
这一步,让字节瞬间站在了所有玩家的对立面。迪士尼、美国电影协会(MPA)第一时间发函指控,称其 “系统性侵权”,是 “虚拟世界的打砸抢”。全球舆论哗然,不少人断言:字节这次闯了大祸,Seedance 2.0 必将夭折。
但字节的回应,平静却有力:技术革命,从来都伴随着规则的重构;真正的创新,从不怕暂时的争议。字节没有退缩,反而顶着压力,持续优化模型 —— 因为他们清楚,只有经历过顶级影视数据的 “淬炼”,模型才能真正理解 “什么是好视频”,才能学会电影级的镜头语言、光影美学、动作逻辑,才能生成真正 “媲美实拍” 的内容。
事实证明,字节的 “冒险”,换来了碾压级的实力。Seedance 2.0 最直观的震撼,就是质感的跃迁:它能精准还原电影级的光影层次,从清晨的柔光到深夜的冷光,从室内的暖调到室外的冷调,细腻到每一缕光线的折射、每一处阴影的渐变;它能完美遵循物理规律,人物动作自然连贯,物体运动符合重力逻辑,流体、火焰、烟雾等特效逼真到以假乱真,没有一丝僵硬和违和感;它能实现 “导演级” 的镜头操控,推、拉、摇、移、跟、升、降,运镜流畅专业,多镜头切换自然连贯,角色一致性全程在线,仿佛有一位专业导演在幕后操控。
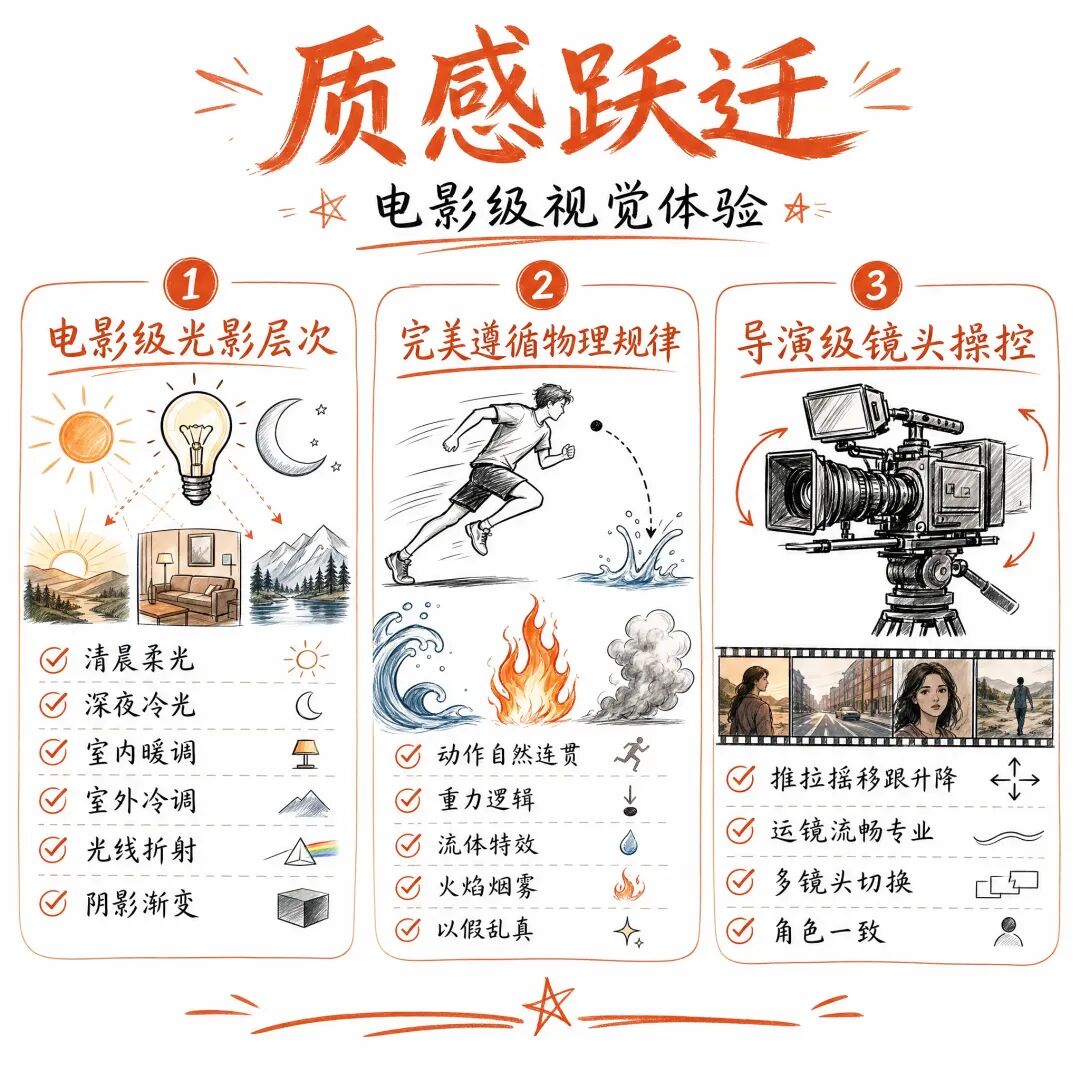
这种质感,是所有依赖公开短视频数据训练的模型永远无法企及的。同行们终于明白:不是做不好,而是不敢做;不是能力不足,而是勇气不够。在 AI 视频生成的赛道上,字节用 “无畏者” 的底色,撕开了版权的枷锁,也撕开了行业的天花板。

二、技术的碾压:Seedance 2.0 的四大 “降维打击”
如果说 “敢喂版权数据” 是 Seedance 2.0 的底气来源,那么四大核心技术能力,就是它碾压所有对手的 “杀手锏”。在 Seedance 2.0 面前,所谓的 “竞品”,更像是 “低配模仿者”—— 只能在表面做文章,却永远无法触及核心技术的内核。
(一)多模态全能输入:创作自由度的 “无限可能”
传统 AI 视频模型,大多只能支持单一的文生视频或图生视频,创作自由度极低,很难满足复杂的创作需求。而 Seedance 2.0 直接打破了模态壁垒,原生支持文字、图片、音频、视频四种模态混合输入,最多可同时接收 3 段视频 + 9 张图 + 3 段音频作为参考。
这意味着什么?创作者可以上传一张剧照、一段音频、一个动作片段,再配上文字描述,模型就能精准参考所有素材的构图、动作、运镜、特效、声音,生成风格统一、逻辑连贯、细节还原的视频。比如,你上传一张《流浪地球》的剧照,配上一段科幻音效,再输入文字 “角色在冰封的城市中奔跑,镜头跟拍,逆光效果”,Seedance 2.0 就能生成一段质感堪比原片的科幻视频 —— 光影、运镜、特效、氛围,完美复刻电影级水准。
这种多模态融合能力,让创作门槛直接降到 “零”,但创作上限却无限拔高。无论是专业导演制作分镜预览,还是短视频创作者打造爆款内容,无论是电商商家制作产品广告,还是游戏开发者生成剧情动画,Seedance 2.0 都能轻松胜任,真正实现 “所想即所见”。
(二)物理世界精准模拟:真实感的 “终极密码”
AI 视频生成的最大痛点,永远是 “不真实”—— 人物动作扭曲、物体漂浮空中、光影逻辑混乱、特效生硬违和,这些问题让 AI 生成内容始终无法登上 “大雅之堂”。而 Seedance 2.0 通过时空因果建模(STCM)架构,从根本上解决了这个难题,实现了对物理世界的精准模拟。
它能精准捕捉并还原复杂交互场景:多人对话时,口型与声音精准同步,肢体动作自然呼应;打斗场景中,动作连贯流畅,击打效果逼真,受力反馈符合物理逻辑;人群场景中,每个人物的动作、神态各不相同,却又和谐统一,充满真实感。
它能精准还原细节与逻辑:仅凭一张建筑正面照,就能自动生成背面细节和环绕运镜,仿佛 “知晓未展示的场景”;特写镜头中,人物的发丝、皮肤纹理、衣物褶皱清晰可见,眼神神态自然生动,毫无 AI 生成的 “塑料感”;物体的光影随运动实时变化,反射、折射、阴影完全遵循物理规律,真实到令人窒息。
这种对物理世界的极致还原,让 Seedance 2.0 生成的视频,第一次真正具备了 “实拍级” 的真实感 —— 你甚至很难分辨,哪些是 AI 生成,哪些是真人拍摄。
(三)多镜头叙事 + 角色一致性:工业化内容生产的核心
对于专业内容创作(如短剧、漫剧、广告片)而言,多镜头叙事和角色一致性是核心要求 —— 需要多个镜头切换,角色外貌、服装、神态全程保持一致,否则内容会显得杂乱无章,无法观看。
此前,没有任何一款 AI 视频模型能完美实现这一点:要么镜头切换生硬,要么角色 “变脸”,要么风格前后不一。而 Seedance 2.0 凭借独有的多镜头叙事引擎和长效角色一致性技术,彻底攻克了这个难题。
它能自动规划分镜与运镜:只需输入一段复杂的脚本(如 “全景:城市夜景,主角从远处走来;中景:主角面部特写,眼神坚定;近景:主角手握武器,准备战斗;特写:武器寒光闪闪”),模型就能自动生成四个连贯的镜头,运镜流畅自然,镜头衔接毫无违和感。
它能全程保持角色一致性:无论镜头如何切换、场景如何变化、动作如何复杂,角色的外貌、发型、服装、神态、声音始终保持高度一致,不会出现 “变脸”“变装”“变声” 等问题。这种能力,让 AI 生成短剧、漫剧成为现实 —— 创作者只需输入一个故事脚本,Seedance 2.0 就能自动生成多镜头、连贯剧情、角色统一的完整视频,效率提升百倍,成本降低 90% 以上。
(四)原生音画同步:完整视频创作的 “最后一块拼图”
大多数 AI 视频模型,只能生成无声视频,后期需要额外配音、加音效,不仅麻烦,而且音画很难精准同步,影响观看体验。Seedance 2.0 则采用双分支扩散变换器架构,原生支持音视频联合生成,输出的视频自带原生音频,无需后期处理。
它能精准匹配口型与声音:生成人物对话时,口型与语音完全同步,语气、语调、情感与人物神态高度契合,毫无违和感;它能自动生成环境音效:根据场景自动匹配风声、雨声、脚步声、车辆声等环境音效,增强视频的沉浸感;它能还原声音特质:无需声音样本,就能还原人物的语气、音色、情感,甚至能生成符合角色设定的对白,自然生动。
原生音画同步能力,让 Seedance 2.0 实现了 “从 0 到 1” 的完整视频创作 —— 输入文字,直接输出带音频的完整视频,一步到位,无需任何后期处理。这种能力,是所有竞品都无法企及的,也是 Seedance 2.0 成为 “工业化内容生产工具” 的核心支撑。

三、快乐马的 “廉价狂欢”:除了低价,一无所有
在 Seedance 2.0 凭借碾压级实力横扫市场时,阿里的快乐马(Happy Horse)匆匆入局,试图靠 “低价策略” 分一杯羹。在国际权威 AI 评测平台 Artificial Analysis 的文生视频榜单上,快乐马一度以 1385 Elo 评分登顶,短暂超过 Seedance 2.0,引发了一波 “黑马逆袭” 的炒作。但褪去炒作的外衣,真相一目了然:快乐马的领先,只是 “廉价的狂欢”;除了低价,它没有任何能与 Seedance 2.0 抗衡的核心能力。
(一)价格优势:唯一的 “遮羞布”
快乐马的核心卖点,也是唯一能拿得出手的优势,就是极致的低价:720P 分辨率视频,会员折扣后低至 0.44 元 / 秒,而 Seedance 2.0 的价格是 1 元 / 秒,快乐马便宜了近 56%。对于预算有限、只需要低质量短视频的用户而言,快乐马确实有一定吸引力 —— 花更少的钱,生成能用的视频,足够满足基础需求。
但低价的背后,是赤裸裸的质量妥协:快乐马生成的视频,画面模糊、细节失真、色彩饱和度偏低;人物动作僵硬、表情生硬、肢体不协调;光影逻辑混乱、特效生硬违和、毫无质感可言;多镜头切换生硬、角色一致性差、经常出现 “变脸” 问题;音画同步精度低、口型匹配差、音效生硬。简单来说,快乐马的低价,是用 “牺牲质量” 换来的 —— 它能生成 “能用” 的视频,但永远生成不了 “好看” 的视频,更别说电影级质感。
(二)核心技术差距:全方位被碾压
抛开价格,从核心技术能力来看,快乐马在 Seedance 2.0 面前,就是 “低配版模仿者”,全方位被碾压,毫无还手之力。多模态能力:快乐马仅支持基础的文生视频、图生视频,不支持音频、视频参考输入,创作自由度极低;而 Seedance 2.0 支持四种模态混合输入,创作自由度无限,能满足复杂创作需求。
物理模拟能力:快乐马生成的视频,人物动作僵硬、物体运动违背物理规律、光影逻辑混乱、特效生硬违和,毫无真实感;而 Seedance 2.0 能精准模拟物理世界,动作自然连贯、细节逼真、光影质感堪比实拍。
多镜头叙事与角色一致性:快乐马不支持自动分镜规划,多镜头切换生硬,角色一致性差,经常 “变脸”;而 Seedance 2.0 能自动生成多镜头叙事,角色全程一致,完美适配短剧、漫剧等专业场景。
原生音画同步:快乐马生成的视频,音画同步精度低、口型匹配差、音效生硬,需要后期额外处理;而 Seedance 2.0 原生支持音视频联合生成,口型精准匹配、音效自然,一步到位输出完整视频。
简单来说,Seedance 2.0 做的是 “专业级创作”,而快乐马做的是 “玩具级生成”。快乐马能做的,Seedance 2.0 能做得更好;Seedance 2.0 能做的,快乐马根本做不到。所谓的 “榜单登顶”,不过是因为评测平台仅考核单片段质量,无法衡量多镜头连贯性、角色一致性、音画同步等核心能力 —— 而这些,恰恰是 Seedance 2.0 的强项,也是快乐马的致命短板。
(三)生态与壁垒:毫无可比性
除了技术差距,生态壁垒更是快乐马无法逾越的鸿沟。Seedance 2.0 已全面接入豆包、即梦 AI、火山引擎等字节全系产品,形成了 “模型 + 产品 + 生态” 的完整闭环。创作者可以在豆包直接体验 Seedance 2.0,一键生成视频;企业可以通过火山引擎 API,将 Seedance 2.0 集成到自己的产品中,实现定制化开发;内容创作者可以在即梦 AI,享受 Seedance 2.0 的全部能力,打造爆款内容。
而快乐马,仅作为阿里的一款独立工具,没有形成完整生态,用户量少、创作者生态薄弱、企业接入意愿低。更重要的是,字节的版权数据壁垒,是快乐马永远无法突破的—— 阿里不敢像字节一样,啃下版权影视数据的硬骨头,只能依赖公开短视频数据训练模型,这就从根本上决定了,快乐马的质量上限,永远无法企及 Seedance 2.0 的下限。

四、无畏者的未来:Seedance 2.0,重构万亿内容产业
在 AI 视频生成的赛道上,从来没有像今天这样,技术、勇气、格局如此清晰地分化出两个阵营:一边是字节跳动,以 Seedance 2.0 为武器,无畏无惧、技术碾压、格局宏大;另一边是阿里等同行,以低价为噱头,畏首畏尾、模仿跟风、格局狭小。
短期来看,快乐马或许能靠低价吸引一部分预算有限的用户,获得一定的市场份额;但长期来看,技术才是硬道理,质量才是核心竞争力。随着 AI 视频生成从 “尝鲜” 走向 “工业化应用”,用户对质量的要求会越来越高 —— 无论是专业创作者、企业用户,还是普通消费者,最终都会选择 “质感更好、能力更强、创作自由度更高” 的 Seedance 2.0,而不是 “低价低质” 的快乐马。
Seedance 2.0 的意义,远不止于一款 AI 视频生成模型 —— 它是万亿内容产业的重构者。在影视行业,它能大幅降低短剧、漫剧、广告片的制作成本,提升生产效率,让优质内容规模化产出;在短视频行业,它能让普通创作者一键生成电影级质感的爆款视频,打破专业壁垒,实现 “人人都是创作者”;在电商行业,它能让商家快速生成高质量的产品广告,提升转化率,降低营销成本;在游戏、教育、传媒等行业,它也能发挥巨大价值,重构内容生产方式。

而这一切的起点,都是字节那份 “无畏者” 的勇气 ——敢为天下先,敢啃硬骨头,敢突破规则的束缚。在这个人人都追求 “安全”“稳妥”“不犯错” 的时代,字节的 “冒险”,显得格外珍贵;Seedance 2.0 的出现,显得格外震撼。
未来已来,大势所趋。当其他同行还在为版权问题瞻前顾后、为低价流量沾沾自喜时,Seedance 2.0 已经带着无畏者的勇气、碾压级的技术、宏大的格局,踏上了重构万亿内容产业的征程。属于 Seedance 2.0 的时代,才刚刚开始;属于字节的技术革命,永远不会停止。

