 夜雨聆风
夜雨聆风国产 AI 配音进全球前三:普通人也能当“配音导演”了
如果你做过短视频、课程、播客,应该知道最麻烦的往往不是写稿,而是配音。
自己录,容易卡壳;找人录,成本不低;用 AI 配音,又常常像在读说明书。
所以今天这条消息值得看:AIHOT 显示,阶跃星辰的 StepAudio 2.5 TTS 在 Artificial Analysis 语音竞技场盲测榜进入全球前三,Elo 评分 1187。公开信息还提到,它支持全局语境提示和行内情感标签,价格为每百万字符 85 美元,速度约 37.6 字符/秒。
这不是“国产模型又上榜了”这么简单。
对普通内容创作者来说,真正的变化是:AI 配音不只是把文字念出来,它开始能按场景、角色和情绪去“演”。
先别只盯着声音像不像真人
很多人试 AI 配音,第一反应是换声音。
男声不行换女声,年轻声不行换成熟声,普通话不行换播音腔。折腾半天,还是觉得不自然。
问题常常不在声音,而在稿子。
你给 AI 的如果只是一段干巴巴的文字,它当然只能干巴巴地读。就像你把一页稿子递给演员,却不告诉他这是广告、故事、吐槽,还是一段给家长看的提醒。
好的配音,不只是音色。
它还包括停顿、轻重、情绪、速度,以及这一段话到底想让听的人紧张、放松、好奇,还是立刻行动。
这也是 StepAudio 2.5 TTS 这类“语境感知”语音模型值得关注的地方。StepFun 文档里写到,它支持全局语境自然语言指导,也支持在文中做更细的语境控制。换句话说,你可以不只写“读这段话”,还可以写“用什么状态读”。
真正该学的是“配音导演思路”
以前用 AI 配音,很像点外卖。
选一个声音,贴一段文字,等它生成。
现在更像坐在录音棚里做导演。
你要先说明:这段内容给谁听?是在讲一个新闻,还是教一个方法?语气是轻松一点,还是提醒一点?哪些地方要慢,哪些地方要稍微加重?
这听起来麻烦,但对创作者反而是好事。
因为门槛从“谁有录音棚、谁会播音”下降到了“谁更会写提示、谁更懂自己的读者”。
一个公众号作者,可以把文章摘要改成音频开头;一个课程老师,可以先让 AI 读出不同版本,挑最自然的一版;一个小团队,可以给产品介绍做几条不同情绪的短音频,不必每次都重新找配音。
这里的重点不是省掉人,而是让普通人先有一个可用版本。
你可以先用 AI 做草稿,再决定哪些内容值得真人精修。
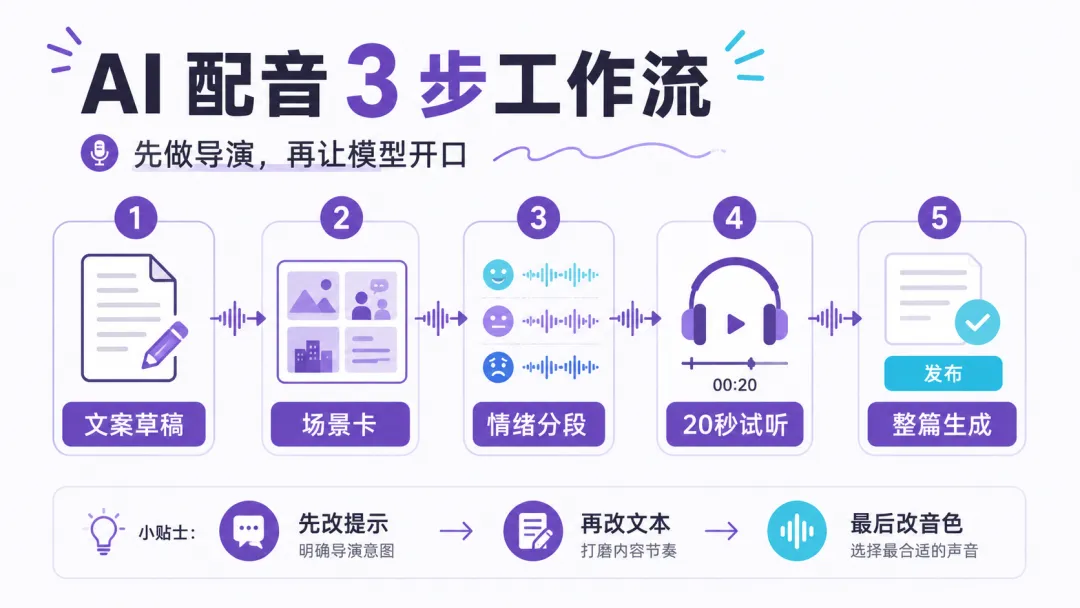
普通人可以按这 3 步用
第一步:先写“场景卡”,不要直接贴全文
在正文前加一小段说明。
比如:这是一条给视频号观众的 60 秒口播,语气要像朋友提醒,不要像新闻播报;前半段稍微好奇,后半段更坚定。
这段说明不需要很长。StepFun 文档提到 instruction 有 200 字符上限,反而提醒我们:提示要短、准、具体。
你不需要写一堆形容词,只要说清楚听众、场景和情绪。
第二步:把一整段拆成几种情绪
不要把 1000 字一次性丢进去。
先拆成开头、解释、清单、结尾。
开头要抓人,可以稍快一点;解释部分要稳一点;清单部分要清楚;结尾要像在给一个可执行建议。
如果工具支持行内情感标签,就把这些变化写在对应段落旁边。即使不用标签,你也可以在文案里用括号或短句标注,让自己知道每一段要达到什么效果。
第三步:先试 20 秒,再决定整篇
很多人一上来就生成整篇,听到后面才发现节奏不对。
更好的做法是先试开头 20 秒。
如果开头已经像机器人,后面大概率也救不回来。先改场景说明,再改段落情绪,最后才换声音。
这个顺序很重要:先改导演提示,再改文本,最后改音色。
一张可收藏的检查清单
下次做 AI 配音前,可以先问自己 5 个问题。
第一,这段声音给谁听?是给家长、学生、客户,还是朋友?
第二,它出现在哪里?是短视频开头、课程讲解、播客引子,还是产品说明?
第三,听完以后,希望对方做什么?继续看、收藏、下单、留言,还是转给别人?
第四,哪一句必须读得慢一点?哪一句必须读得轻一点?
第五,生成后有没有先用手机外放听一遍?很多电脑上听着还行的声音,到了手机外放会变得很硬。
这 5 个问题,比盲目换 20 个音色更有用。

对公众号作者尤其值得试
公众号正在变得越来越多格式。
一篇文章可以变成音频摘要,可以变成短视频口播,也可以变成社群里的 30 秒语音预告。
过去这一步很费时间,所以很多人只写图文。
但如果 AI 配音越来越可控,内容生产会多出一条很实用的支线:先把文章变成声音,再让声音去分发。
这也符合现在内容创作者最需要的能力:不是每天凭灵感重做一遍,而是把一篇内容拆成标题、图文、封面、音频、短视频和复盘数据。
StepAudio 2.5 TTS 上榜,给我们的提醒不是“赶紧换工具”。
更准确地说,是该把“配音提示词”放进自己的内容流程里了。
最后
如果你今天只记一句话,就记这句:
AI 配音的下一步,不是找一个最像真人的声音,而是学会告诉它怎么演。
下次做视频、课程或文章音频时,别急着点生成。
先写 3 行导演提示:给谁听、在什么场景、用什么情绪。
声音会不会更像人,往往从这 3 行开始。
