 夜雨聆风
夜雨聆风
PART 01
PART 02
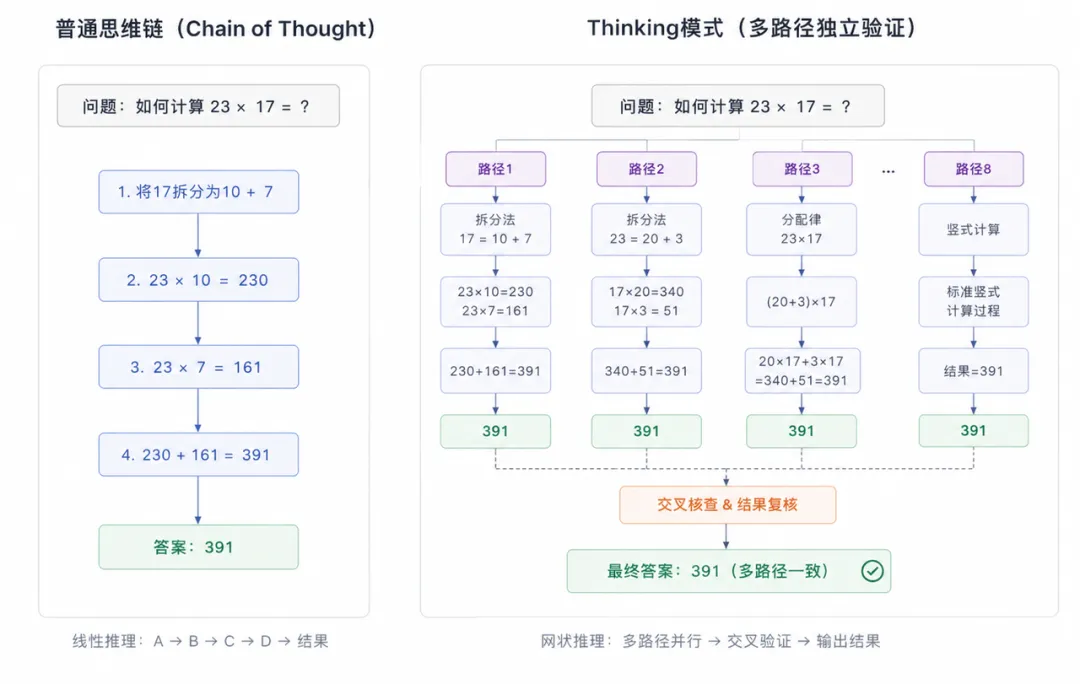
PART 03
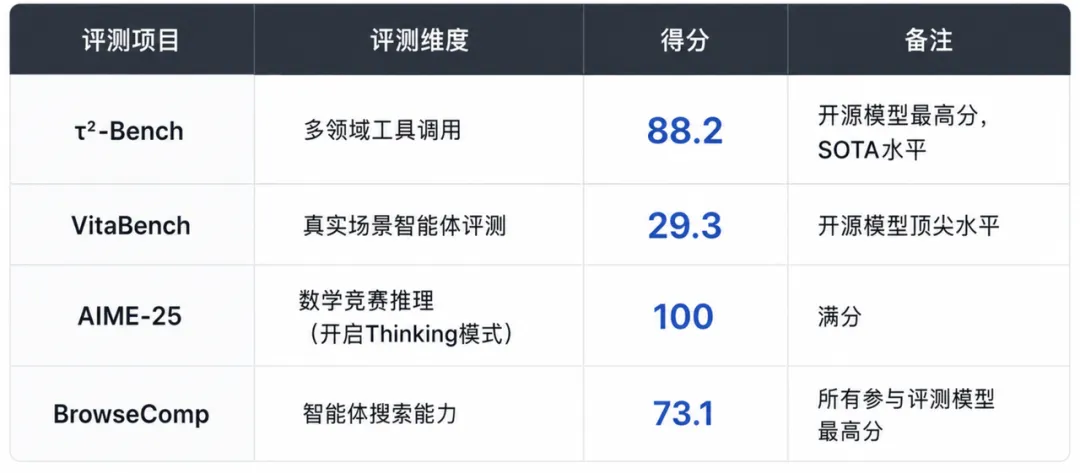
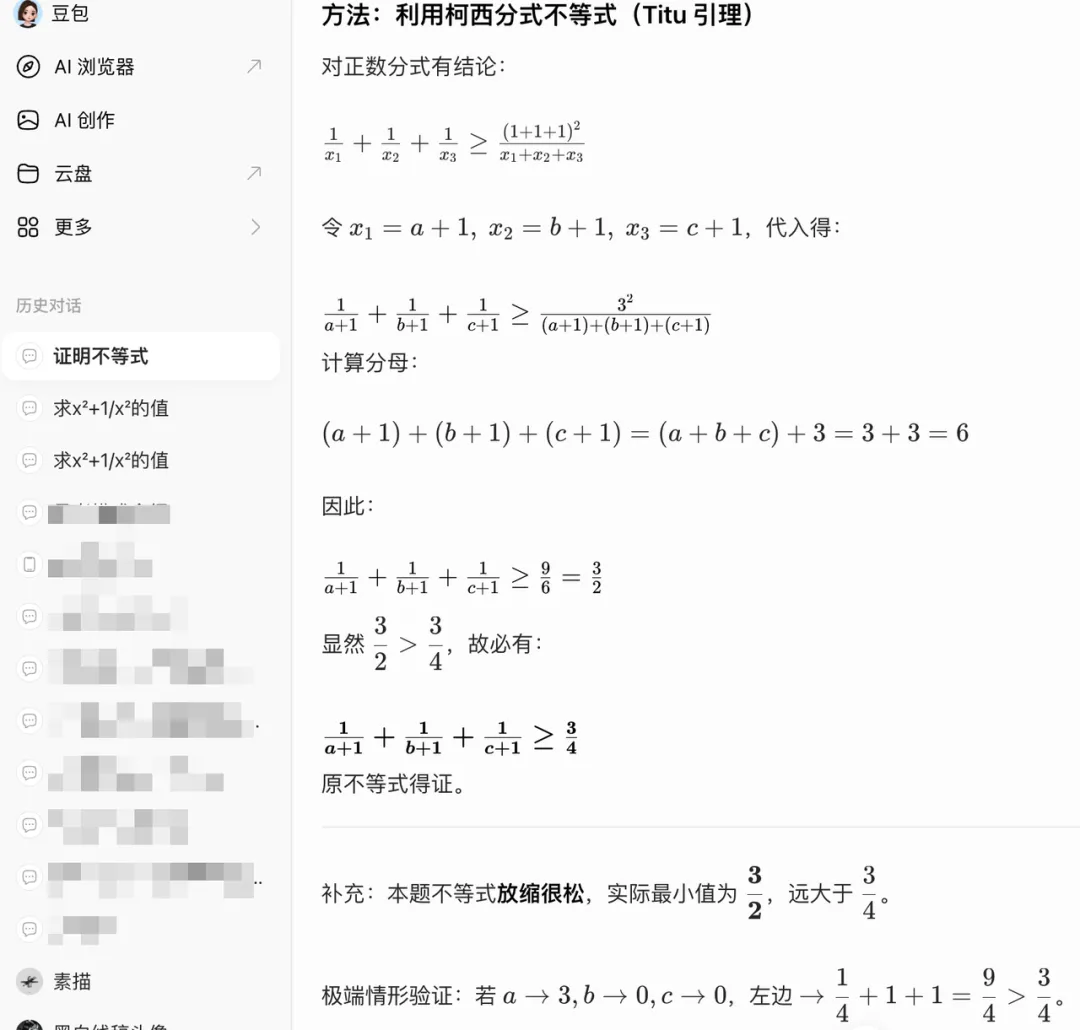
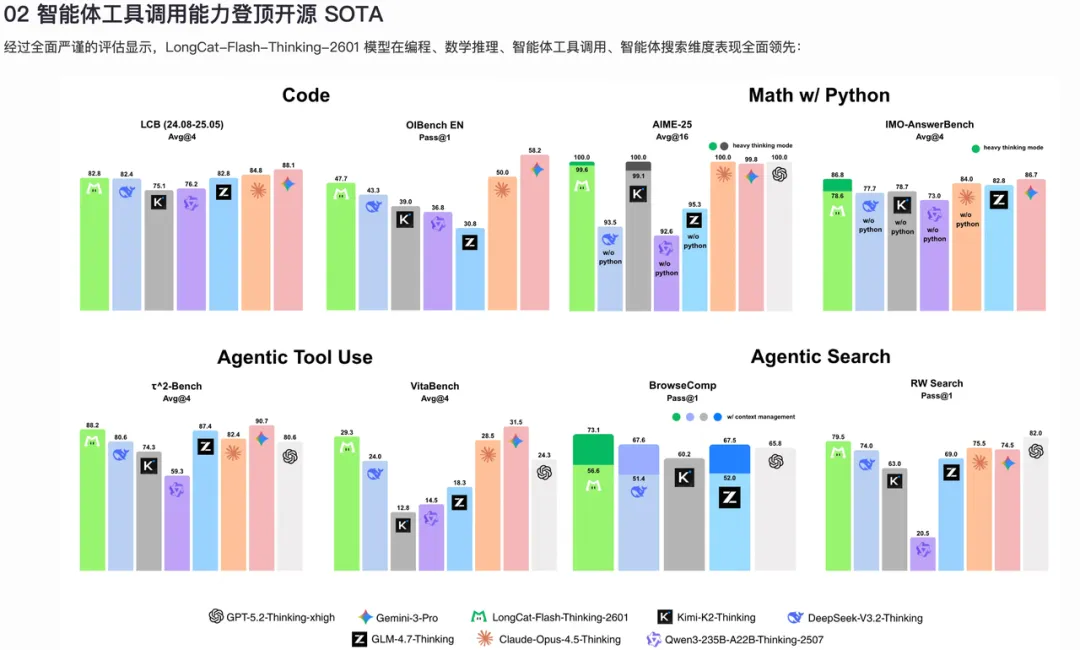
τ²-Bench(多领域工具调用):88.2分,开源模型最高分,SOTA水平
VitaBench(真实场景智能体评测):29.3分,开源模型顶尖水平
AIME-25(数学竞赛推理,开启Thinking模式):100分满分
BrowseComp(智能体搜索能力):73.1分,所有参与评测模型最高分
PART 04
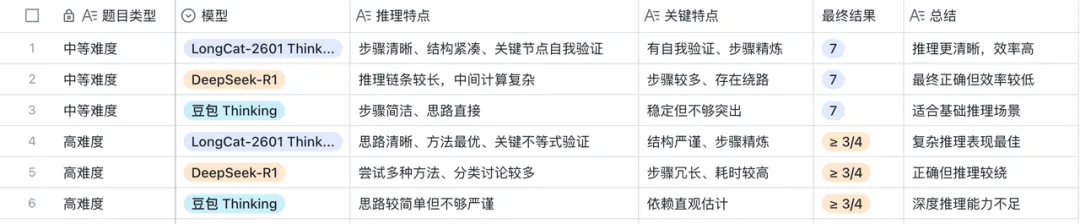



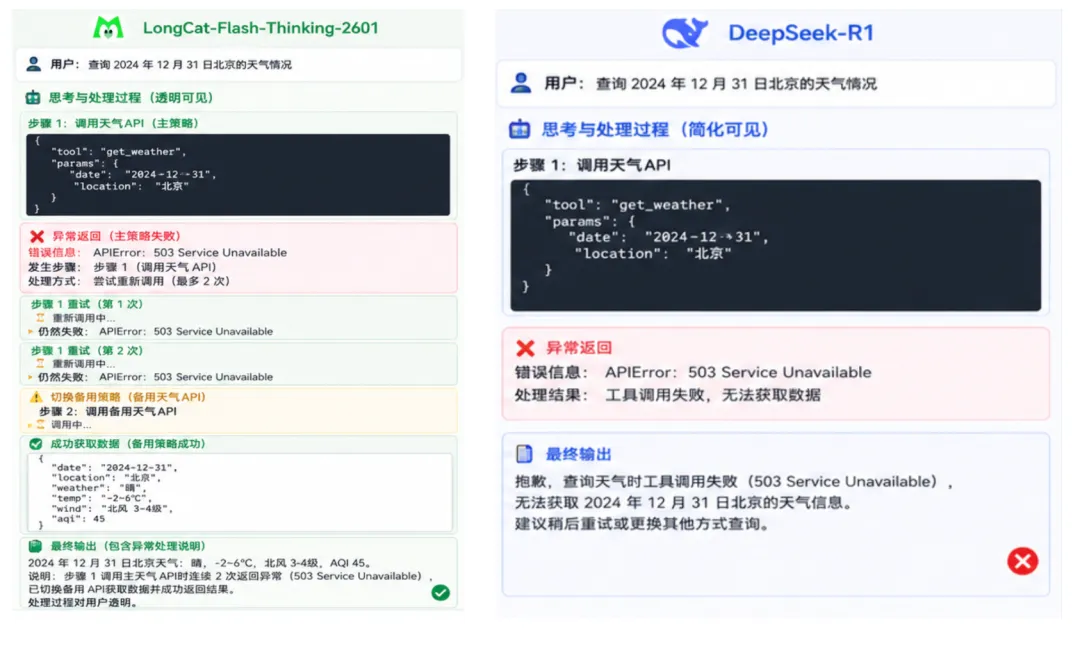
LongCat-2601 Thinking在遇到异常返回时,会先尝试重新调用,失败后切换备用策略,并在最终输出里标注了哪一步出现了异常以及它是如何处理的。整个过程对用户是透明的。
DeepSeek-R1在这个场景下的表现是:遇到异常后停止,给出了"工具调用失败"的提示,但没有尝试备用策略,也没有给出部分结果。
豆包Thinking在工具调用的场景下表现最弱,它在这个测试里直接跳过了异常工具,用自己的知识库填补了空缺,但没有标注这一步是估算而非实际调用结果——这对需要准确数据的业务场景来说是一个隐患。
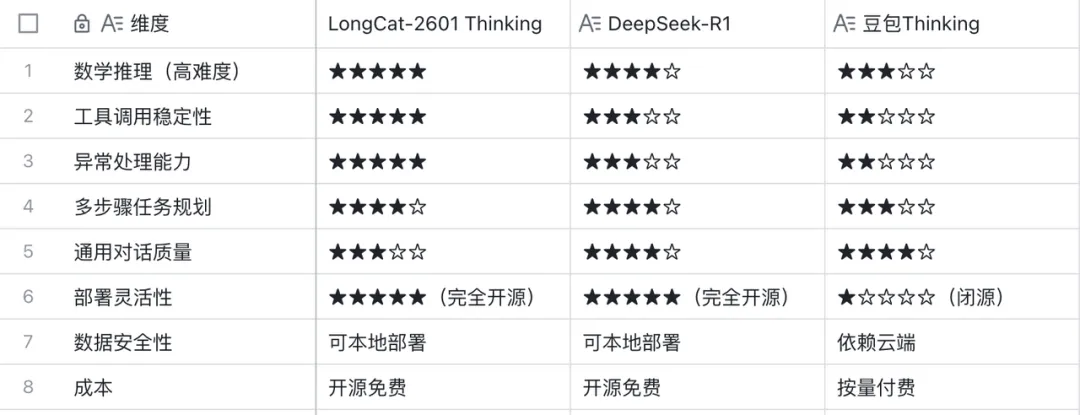
PART 05
它能不能稳定地完成我给它的任务? 遇到异常情况它怎么处理? 我的数据安不安全? 用它的成本我能承受得起吗?
PART 06







响应速度:Thinking模式的响应时间明显长于普通模式,简单问题可能需要20~30秒,复杂任务60秒以上。对于习惯了即时响应的C端用户来说,这个等待时间是一个体验门槛。对B端用户来说相对可以接受,但在需要高频交互的场景下依然是痛点。
通用对话质量:如果你只是想随便聊聊,或者问一个不需要深度推理的问题,LongCat-2601 Thinking的表现并不比其他模型有优势,甚至因为它"想太多"而显得有点笨重。它不是一个全能选手,它是一个在特定赛道上极其出色的专项选手。
中文长文创作:在需要生成大段中文内容的场景下(比如营销文案、故事创作),它的表现明显弱于豆包和千问。这不是它的设计目标,但如果你同时有这类需求,需要搭配其他工具使用。
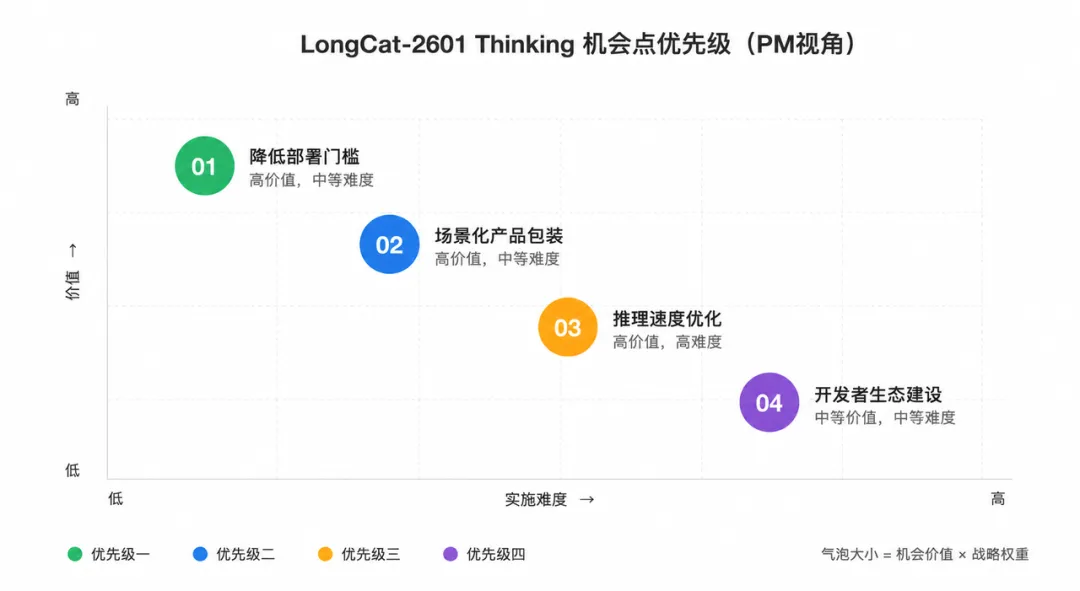
部署门槛:完全开源意味着你能拿到完整的模型权重和代码,但也意味着你需要有一定的技术能力才能把它跑起来。对于没有技术团队的小公司来说,这依然是一个不小的门槛。
PART 07
PART 08
PART 09
PART 10
PART 11
