 夜雨聆风
夜雨聆风
过去一年,如果你常刷 X、翻论文、看公司发布会,大概会注意到一个变化——"memory"这个词的密度突然变得很高。ChatGPT 悄悄加了"记住你"的功能;几家主流云厂商几乎同时上线了叫做"记忆银行"、"记忆内核"的基础服务;几十个开源项目蹦出来,喊自己是"给大模型装一副长期记忆"。
这不是营销跟风。它背后藏着一个很少被正视的事实:今天绝大多数大模型,本质上都是失忆症患者——每次回答完你之后,就把你和它之间发生过的一切忘得干干净净。你下次再打开对话框,它不认识你、不记得你昨天说过什么、更不知道上次交代的事情做到哪一步了。
当 AI 只是"一次性问答工具"时,这个缺陷可以忍。但当大家开始希望它变成长期陪你的数字助理、帮团队做事的 AI 员工、和你一起跑项目的协作者——失忆就成了天花板。
这篇文章想把"AI 记忆"这件事的十年变化讲清楚:它从什么开始的、为什么今天变成了行业焦点、又为什么真正的难点根本不是"记得住"。

一、从没有记忆,到会忘记的记忆
把时间线拉长看,AI 记忆这件事大致经过了六个阶段。
一句话可以把这六步概括完:AI 记忆从"没有"走到了"短时",再走到了"长时、结构化、可治理"。
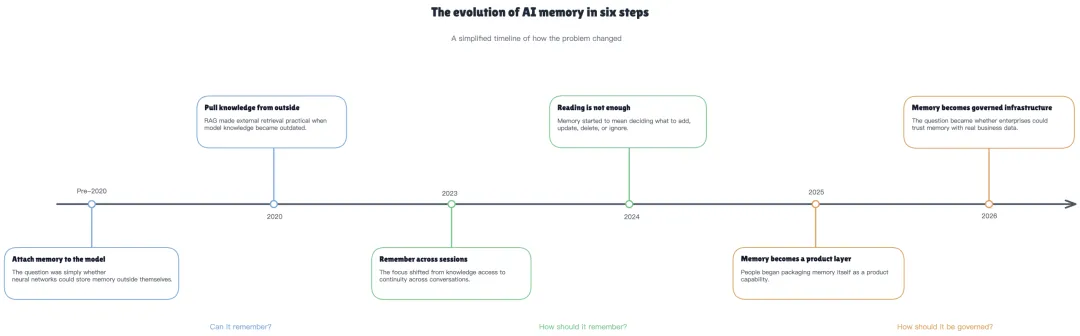
2020年前,学术圈在琢磨能不能给神经网络接一块硬盘,来解决“能不能记”的问题,此阶段主要停留在学术探索
2020年 RAG 出现,第一次把"外部记忆"做成了生产可用的东西,今天几乎所有 AI 产品的底层都还在用它。但 RAG 只解决了"读"的问题。它不管要不要记住这次对话、上次那条信息是不是已经过期、哪些信息应该给谁看。
2023年前后研究者们开始让 AI 具备跨会话的连续性
2024年行业共识转向一件更深的事——光能检索不够,还得会写、会改、会忘。
2025年记忆第一次变成了可以单独卖的产品
2026年云厂商全面进场,但他们在前台强调的已经不再是"我们记得多准",而是另外一组词——安全合规认证、审计日志、数据驻留、可删除证据、企业自带密钥。
为什么会有这个切换?这就要先把几个经常被搞混的概念讲清楚。
二、工作台、图书馆与大脑
很多人刚接触这个领域时,会把三个很不一样的东西当成一回事——上下文窗口、RAG、记忆系统。
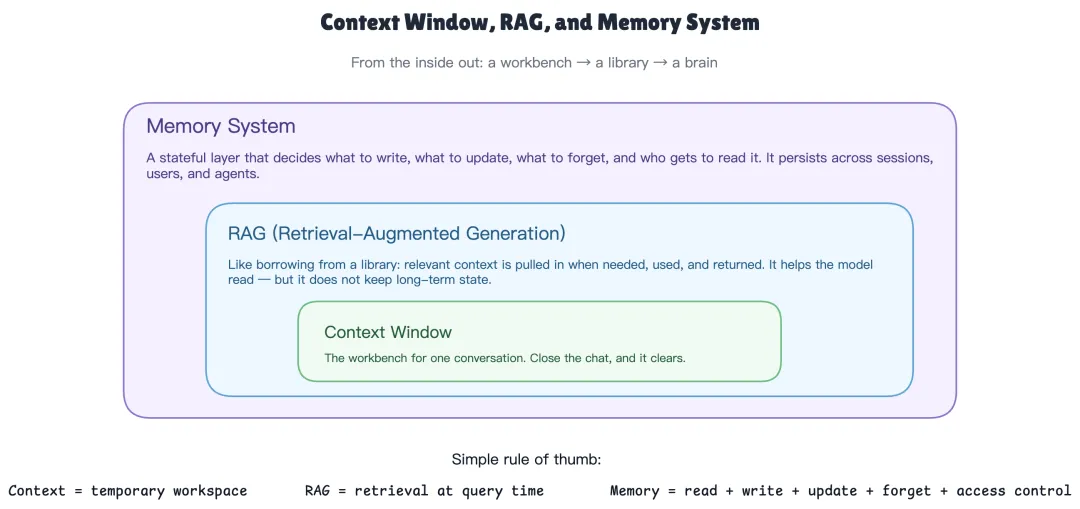
上下文窗口是模型在一次对话里能看到多少字。你给它一百万字也好,关掉对话框就清空了。它是工作台,不是记忆。
RAG是提问那一刻从资料里捞几段塞进对话里。它答完就走,在对话之间不留任何痕迹。它像图书馆借书——用完还回去,下次来还得重借。
记忆系统是一个带状态的层。它要做的事情多得多:什么时候写、写什么、什么时候改、怎么忘、谁能读。它跨会话、跨用户、跨 agent 地存在。如果说 RAG 是借书,记忆系统就是一个人本身的大脑——它会主动整理、遗忘、建立联想。
一个直白的区分方式是——RAG 是"读",记忆是"读 + 写 + 改 + 忘 + 管"。市面上很多项目挂着记忆的招牌,做的其实是 RAG 的延伸。
三、像操作系统一样理解 AI 记忆
理解记忆系统时,工程圈最流行的一个比喻是——把它当操作系统来看。
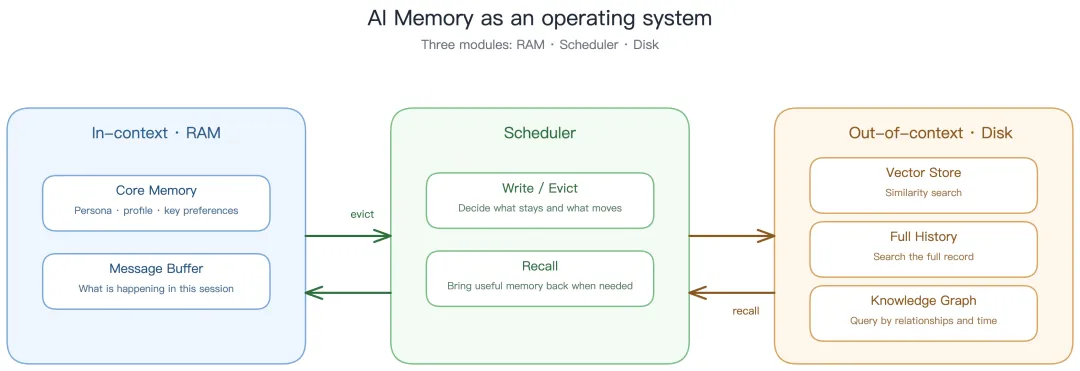
对应关系一眼能明白:
模型的上下文窗口 = 系统的 RAM,快但装不下你一辈子
外部的长期记忆库 = 硬盘,存得久但用的时候要走检索
记忆系统真正的核心工作 = 调度:什么时候常驻 RAM?什么时候换出?什么时候做后台整理?
很多记忆产品都有一个叫"反思"或"整固"的后台过程——这和操作系统在后台把脏页刷回磁盘是一回事:热路径只负责快速写下原始数据,冷路径趁安静的时候慢慢整理。
四、记得住根本不是问题
过去两年,关于 AI 记忆的讨论几乎都围绕"记得准不准"、"检索多快"、"召回率多高"。这些指标当然重要,但它们有一个共同特征——可复现、会被追上、不构成护城河。
当一家企业真的要在生产环境用 AI 记忆时,他第一批问的问题根本不是"能不能记住",而是这些:
员工和 AI 的对话都被记下来了,HR 看得到吗?法务查得到吗?
我换了公司,之前团队用的 AI 还记着我说过的话,它应该继续记得吗?
我让 AI "忘记我",它真的删了吗?能不能拿出已删除的证明?
欧洲用户行使"被遗忘权"找上门,我怎么证明我全删干净了?
AI 给客户做了个判断、出了问题,审计进来问"它当时为什么这么判",我能不能回放出当时依据的是哪几条记忆?
一个 AI agent 被下线了,它这半年记住的东西要不要跟着销毁?
这些问题,没有一个是靠"更好的向量索引"能解决的。它们要的是一整套配套——权限系统、读写审计、保留期策略、删除证据、数据驻留。也就是说,要把记忆当成受监管的数据系统来治理。
2C 产品其实也一样,只是说法不同——你能不能看到 AI 对你的记忆?能不能修改?能不能带走?能不能真的删掉?
这也解释了为什么最近云厂商的记忆产品发布会全在谈合规认证、加密、权限、审计。不是因为这些词听起来更高级,而是因为客户真正愿意付钱的价值点在这里。
五、走到今天,AI 记忆有五个关键判断
走到今天,AI 记忆这个赛道里其实有很多还在讨论中的问题。但如果把过去几年的实践、产品演化和行业取舍压缩一下,大致可以沉淀出五个比较清晰的判断。
第一,长上下文不会取代记忆系统。百万 token 级的上下文窗口,确实会吃掉一部分原本属于 memory 的场景。比如短任务、小知识库、一次性分析,很多时候直接把资料塞进 prompt 就够了,未必要再额外搭一层记忆系统。
但它替代不了的部分同样明显:跨会话连续性、长期个性化、事实会过期、多租户隔离、可删除、可审计——这些问题都不是“窗口更大”就能解决的。换句话说,长上下文能解决“这一轮怎么看更多”,但解决不了“下一轮还记不记得、该不该记、谁能看、怎么删”。
第二,向量和图不是二选一,而是场景分工。过去一段时间,很多讨论会把“向量库”和“知识图谱”对立起来,好像未来一定只有一条路会胜出。但真实情况更像是:它们适合解决的是两类不同问题。
如果你要记的是个人偏好、习惯、相似语义片段,向量通常已经足够;但如果你要处理的是多主体、跨时间、带关系、要溯源的场景,比如“谁在什么时候和谁发生了什么关系”,图会自然得多。真正的系统大概率不会只选一种,而是按问题拆分:该用向量的地方用向量,该用图的地方用图。
第三,主动写入不是越多越好。很多人第一次接触 memory 时,会本能地觉得“记得越多越聪明”。但真正做过产品之后,大家很快就会发现,问题恰恰不是记不进去,而是记进去以后会不会污染系统。 如果写入过于激进,AI 会把大量短期噪音、偶发表达、甚至用户随口一说的话都当成长期事实保存下来,最后带来的往往不是更好的理解,而是更重的偏差、过拟合和误判。一个好的记忆系统,不只是能写,更重要的是知道什么时候不该写,什么应该被淡化,什么应该被遗忘。
第四,把记忆写进模型参数里,短期还不会成为主流底座。把记忆“烧”进模型权重里,看起来很诱人:推理时快、不用每次检索、响应也更自然。但它的问题同样明显——更新慢、难审计、难删除、难证明已经删除。 尤其一旦进入企业和合规场景,这些缺点会被迅速放大:如果一条记忆已经进了模型参数,后面怎么改?怎么删?怎么向客户证明“我已经删干净了”?这些都是外部记忆层更容易处理的问题。所以短期看,参数内记忆更像一个补充方向,而不是会取代外部 memory 系统的主底座。
第五,真正的护城河不在召回率,而在治理能力。过去两年,大家总爱比较谁召回更准、谁检索更快、谁上下文更长。但这些能力会越来越像标配,它们很重要,却很难构成长期壁垒。 真正会把产品拉开差距的,是另一组能力:写入决策、冲突消解、权限控制、审计能力、删除证据、跨场景连续性。换句话说,真正难的从来不是“让 AI 想起来”,而是“让 AI 记得对、删得掉、解释得清、责任分得明”。这也是为什么今天这个赛道真正往前走时,讨论的重点会越来越从效果走向治理。
六、结语
AI 记忆这件事的奇特之处在于,它听起来是一个技术问题——怎么让模型记住更多东西。但走到 2026 年再看,它其实已经变成了三件事叠在一起:一个产品问题(怎么让客户放心地用),一个合规问题(怎么对记忆负责),也是一个哲学问题(AI 应该记住什么、忘掉什么、向谁负责)。
真正的难点从来不在"记得住"——记得住是最容易的那部分。难的是知道什么该写、什么该改、什么该忘、谁能看、出了事能不能追溯。
这也是 AI 记忆这一波真正在重新定义的东西:它不是单纯在给大模型加一个新功能,而是在回答一个更老的问题——当 AI 要真正融入人的生活和组织的日常时,它应该以什么姿态"记住"我们。
往期推荐
保密且能干的AI员工?zCloak.ai与互联网之父跨时空对齐,亮相AI+IoT高峰论坛
可信经济新纪元: zCloak正式发布企业 AI 大脑与数字员工

