 夜雨聆风
夜雨聆风
AI Coding Agent 的三驾马车:MCP、Skill 与上下文工程
很多人第一次接触 AI Coding Agent,会把精力放在选模型上——用 Opus 还是 Sonnet,GPT-4o 还是 Claude。但工程实践告诉我们,模型选择对最终效果的影响,远没有工具设计、上下文管理和 Skill 系统来得大。
这篇文章聚焦三个关键词:AI Coding Agent、MCP、Skill。不讲概念,讲工程决策——为什么这样设计,不这样设计会出什么问题,以及数据说话。
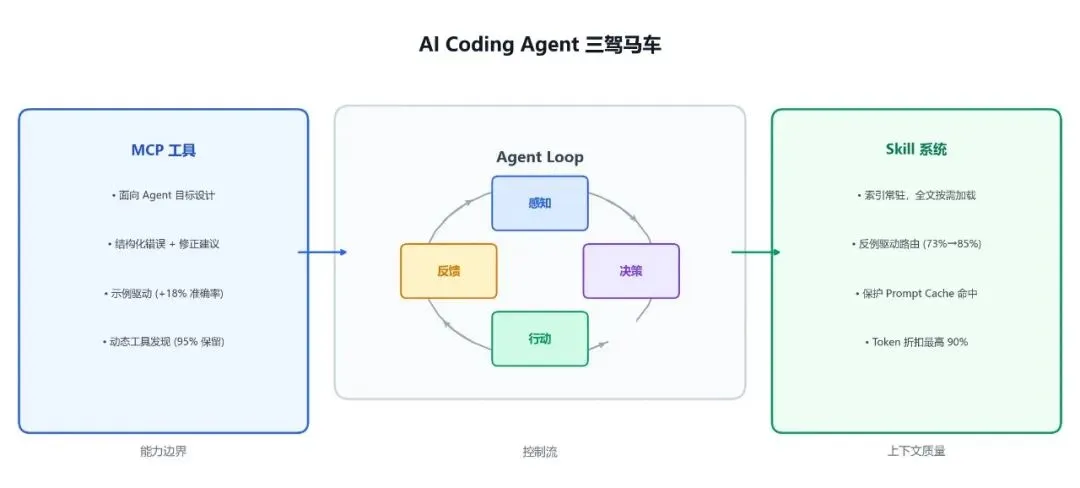
AI Coding Agent 三驾马车:Agent Loop 是骨架,MCP 是肌肉,Skill 是神经系统
01
AI Coding Agent 到底在跑什么
Agent Loop 的核心逻辑抽象后不到 20 行:
const messages: MessageParam[] = [{ role: "user", content: userInput }];while(true) {const response = await client.messages.create({model: "claude-opus-4-6",max_tokens: 8096,tools: toolDefinitions,messages,});if(response.stop_reason === "tool_use") {const toolResults = await Promise.all(response.content.filter((b) => b.type === "tool_use").map(async (b) => ({type: "tool_result" as const,tool_use_id: b.id,content: await executeTool(b.name, b.input),})));messages.push({ role: "assistant", content: response.content });messages.push({ role: "user", content: toolResults });} else {return response.content.find((b) => b.type === "text")?.text ?? "";}}
感知 → 决策 → 行动 → 反馈,四个阶段不断循环,直到模型返回纯文本为止。
这个循环本身相当稳定。从最小实现扩展到支持子 Agent、上下文压缩和 Skills 加载,主循环基本没有变化。新能力通常只通过三种方式接入:扩展工具集和 handler、调整系统提示结构、把状态外化到文件或数据库。
核心循环逻辑和工具调用逻辑要分开,不应该让循环体本身变成一个巨大的状态机。模型负责推理,外部系统负责状态和边界,一旦这个分工确定下来,核心循环就很少需要频繁调整了。
OpenAI 的 Codex 团队用这个模式做到了什么?3 个工程师 5 个月写了百万行代码,将近 1500 个 PR,是传统开发速度的 10 倍。速度背后不是模型有多强,而是几个工程决策做对了:约束编码化而非文档化、Agent 端到端自主完成任务、可观测性栈按任务临时创建。
02
工具设计的三代演进
MCP(Model Context Protocol)是 Anthropic 提出的工具通信标准协议,解决的是 Agent 和外部工具之间的接口问题。但协议本身只是基础,工具设计的质量才是决定 Agent 能不能用好工具的关键。
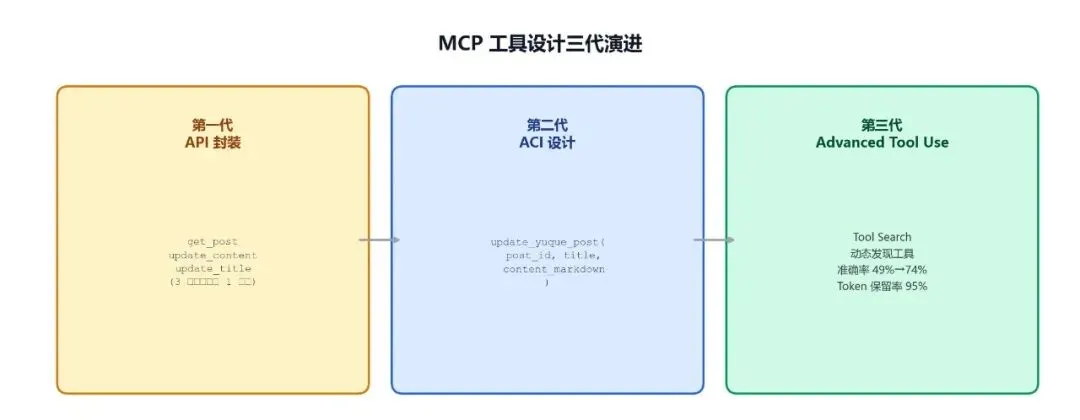
工具设计三代演进:从 API 封装到 ACI,再到 Advanced Tool Use
工具设计经历了三代

第一代,API 封装:每个 API Endpoint 对应一个工具,粒度过细。Agent 往往需要协调多个工具才能完成一个目标,比如更新一篇语雀文章,要先 get_post,再 update_content,再 update_title,三步才能做完一件事。
第二代,ACI(Agent-Computer Interface):工具应对应 Agent 的目标,而不是底层 API 操作。直接给一个 update_yuque_post(post_id, title, content_markdown),一次把目标动作说完整。
第三代,Advanced Tool Use:在工具设计之上,进一步优化工具的发现、调用和描述方式:
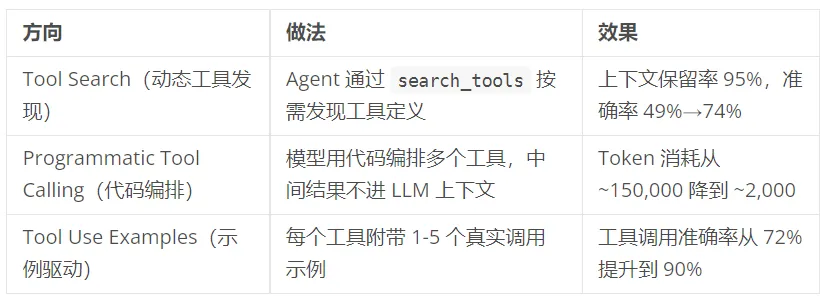
好工具和差工具的区别

差的工具设计:参数模糊,出错只返回字符串,Agent 不知道怎么修正。
// 差:参数模糊,错误不可修正const tool = {name: "update_yuque_post",input_schema: {properties: {post_id: { type: "string" },content: { type: "string" },},},};// 出错时return"Error: update failed";
好的工具设计:参数描述直接约束格式,错误结构化给出修正建议:
const updateTool = betaZodTool({name: "update_yuque_post",description: "更新语雀文章内容,不适合创建新文章",inputSchema: z.object({post_id: z.string().describe("语雀文章 ID,纯数字字符串,如 '12345678'"),title: z.string().optional().describe("文章标题,不改时可省略"),content_markdown: z.string().describe("Markdown 格式正文"),}),run: async (input) => {const post = await getPost(input.post_id);if(!post) thrownew ToolError("文章 ID 不存在", {error_code: "POST_NOT_FOUND",suggestion: "请先调用 list_yuque_posts 获取有效的 post_id",});return await updatePost(input.post_id, input.title, input.content_markdown);},});
调试 Agent 时应先检查工具定义,大多数工具选择错误的原因出在描述不准确,不在模型能力。
MCP 工具的 token 成本

仅 5 个 MCP 服务器就可能带来约 55,000 tokens 的工具定义开销,相当于在 200K 上下文里还没开始对话就用掉了近三成。工具一旦过多,模型对单个工具的注意力也会被稀释。
Cursor 做过一个 A/B 测试:把工具描述同步到文件夹,Agent 默认只看到工具名,需要时再查询具体定义,调用 MCP 工具的任务总 token 消耗减少了 46.9%。这个思路和 Skills 延迟加载是同一套逻辑。
03
Skill:上下文工程的核心模式
Skill 是上下文工程里非常有效的一种模式,核心思路是:系统提示只保留索引,完整知识按需加载。
const systemPrompt = `可用 Skills:- deploy: 部署到生产环境的完整流程- code-review: 代码审查检查清单- git-workflow: 分支策略和 PR 规范`;async function executeLoadSkill(name: string): Promise<string> {return fs.readFile(`./skills/${name}.md`, "utf-8");}
为什么要按需加载

上下文分层管理的核心问题是:信息密度不对。偶尔用的东西每次都加载进来,稳定的规则和动态的状态混在一起,模型能看到的内容越来越多,但真正有用的部分越来越难被注意到。这类现象通常被叫作 Context Rot。

上下文分层管理:按信息的使用频率和稳定性分层,每层只放自己该放的东西
解决方式是按信息的使用频率和稳定性分层:

Skills 延迟加载还有一个隐藏好处:保护Prompt Caching 命中率。
LLM 推理时,如果当前请求的输入前缀和之前某次请求完全一致,这部分 KV 就不需要重新计算,直接从缓存读取。命中的前提是精确前缀匹配,任何一个 token 不同都会破坏匹配。
按需注入的 Skill 内容不破坏系统提示前缀,而是追加在稳定前缀之后。接了很多 MCP 工具的 Agent 如果工具集频繁变动,缓存命中就会不断失效。稳定的大系统提示,比频繁变动的小提示实际成本更低,因为写入成本只付一次,后续每次调用读取的折扣可以达到 90%。
Skill 描述符怎么写

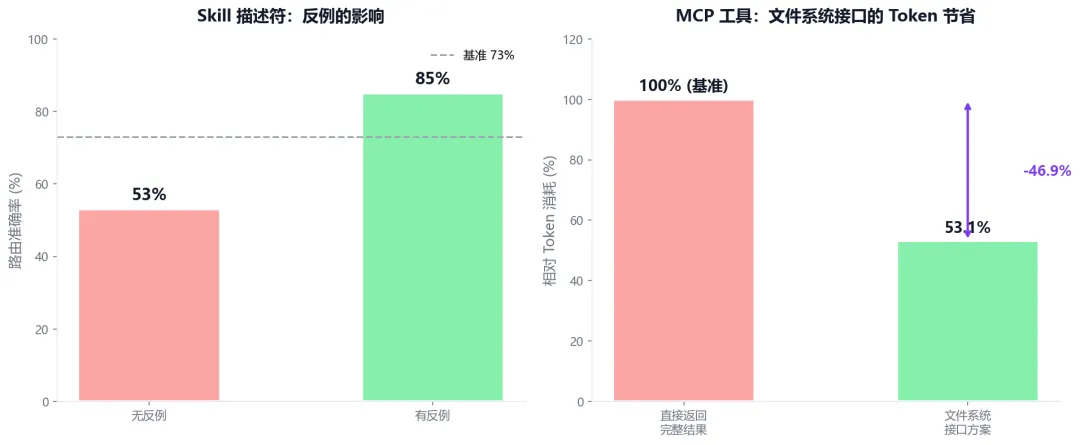
左:反例对 Skill 路由准确率的影响;右:文件系统接口方案的 Token 节省效果
Skill 描述要足够短,避免常驻上下文持续涨 token,也要足够像路由条件而不是功能介绍。
printf("hello # 低效(约 45 tokens)description: |This skill handles the complete deployment process to production.It covers environment checks, rollback procedures, and post-deployverification. Use this before deploying any code to production.# 高效(约 9 tokens)description: Use when deploying to production or rolling back.world!");
更关键的是反例。没有反例时准确率从基准 73% 掉到 53%,加上反例后升到 85%,响应时间还降了 18.1%。反例不是可选项,是 Skill 描述能不能起作用的关键。
最直接的写法是 Use when / Don't use when 再补几条反例:
# git-workflowdescription: Use when creating branches, PRs, or following commit conventions.Don't use when: just running git status/log, or when the task is aboutcode review content(use code-review skill instead).
系统提示里也要把调用规则写明确:每次回复前先扫描 available_skills,有明确匹配时再读取对应 SKILL.md,多个匹配时优先选最具体的那个,没有匹配就不读取,一次只加载一个。
Skills 和 MCP 的选择

Skills 和 MCP 在上下文成本上的特征并不相同。很多 MCP 会把完整结果直接返回给模型,更容易迅速吃掉上下文预算。CLI + 单句描述的 Skill 更接近模型熟悉的调用方式,在大多数可过滤、可拼接的数据读取任务里也更简洁。
当然 MCP 也有明确适用场景,例如 Playwright 这类需要维护状态的任务,或者需要实时数据的工具调用。
04
三者如何协作
AI Coding Agent、MCP 和 Skill 不是三个独立的概念,而是同一个工程问题的三个层面:
Agent Loop决定控制流——感知、决策、行动、反馈如何循环,状态如何外化,任务如何跨 session 续跑。
MCP 工具决定能力边界——Agent 能做什么,工具设计是否面向 Agent 目标,错误是否可修正,token 成本是否可控。
Skill系统决定上下文质量——哪些知识常驻,哪些按需加载,如何防止 Context Rot,如何保护缓存命中率。
三者的关系可以用一句话概括:Agent Loop是骨架,MCP是肌肉,Skill是神经系统。骨架决定能不能动,肌肉决定能做什么,神经系统决定做得准不准、稳不稳。
一个常见的反模式是:系统提示越来越长,工具越加越多,然后发现 Agent 开始选错工具、忽略规则、在第 20 轮对话后决策质量明显下滑。这不是模型的问题,是工程约束没立住。
修法很简单:约定留在系统提示,领域知识移到 Skills;合并重叠工具,明确命名空间;监控 token 占用,超阈值自动触发记忆整合。
05
一个可运行的最小架构
把上面的原则落到代码里,一个最小可运行的 AI Coding Agent 架构大概是这样:
classAgentLoop {constructor(private provider: LLMProvider,private tools: ToolRegistry, // MCP 工具注册表private skills: SkillLoader, // Skill 按需加载器private memory: MemoryManager, // 跨会话记忆) {}asyncrun(userInput: string, session: Session){// 1. 构建分层上下文const systemPrompt = await this.buildLayeredContext(session);// 2. 主循环const messages = [{ role: "user", content: userInput }];for (let i = 0; i < MAX_ITER; i++) {const resp = await this.provider.chat(messages, this.tools.definitions());if (resp.hasToolCalls) {for (const call of resp.toolCalls) {// 3. Skill 触发时按需加载if (call.name === "load_skill") {const skillContent = await this.skills.load(call.args.name);messages.push(toolResult(call.id, skillContent));} else {const result = await this.tools.execute(call.name, call.args);messages.push(toolResult(call.id, result));}}} else {// 4. 记忆整合(token 超阈值时触发)await this.memory.maybeConsolidate(session, messages);return resp.content;}}}privateasyncbuildLayeredContext(session: Session): Promise<string> {return [await readFile("SOUL.md"), // 常驻层:身份和约束await this.memory.load(session), // 记忆层:跨会话事实this.skills.buildIndex(), // Skills 索引(描述符,不含全文)buildRuntimeContext(session), // 运行时:时间、渠道、用户信息].join("\n\n");}}
这个架构的关键设计决策:
系统提示按层构建,Skills 只注入索引,不注入全文
工具注册表和 Skill 加载器分离,MCP 工具走 tools.execute,Skill 走 skills.load
记忆整合在每轮结束后检查,不是在上下文满了才处理
主循环不感知渠道(Telegram、CLI、IDE),渠道适配在外层
06
划重点
Agent Loop 的核心循环很稳定,新能力通过工具扩展、提示结构调整和状态外化接入,不要让循环体本身变成状态机。
MCP 工具设计要面向 Agent 目标,不是面向底层 API。参数描述直接约束格式,错误结构化给出修正建议,每个工具附带真实调用示例。
工具数量要克制。5 个 MCP 服务器约 55,000 tokens,动态工具发现可以把上下文保留率提升到 95%。
Skill 系统的核心是延迟加载:系统提示只保留索引,完整知识触发时注入。Skill 描述符要写路由条件,不是功能介绍,反例是关键。
没有反例时 Skill 路由准确率从 73% 掉到 53%,加上反例后升到 85%,响应时间还降了 18.1%。
稳定的大系统提示比频繁变动的小提示实际成本更低,Prompt Caching 写入成本只付一次,后续折扣可达 90%。
调试 Agent 时先检查工具定义,再检查 Skill 描述,最后才怀疑模型能力。大多数工具选择错误出在描述不准确。
如果你在用 AI Coding Agent 遇到了工具选错、上下文膨胀或者 Skill 路由失准的问题,欢迎交流。
