 夜雨聆风
夜雨聆风当AI开始读你的代码,你写给它看的文档,和你写给人看的文档,已经是两件事了。
引子:一场悄悄发生的革命
你打开一个GitHub仓库,根目录里除了老朋友README.md,现在还躺着AGENTS.md、CLAUDE.md、.cursorrules,以及网站根目录的llms.txt……
这些文件看起来都是Markdown,内容也大同小异,凭什么要分这么多种?
答案只有一句话:读者变了。
从前,文档的读者是人。现在,文档同时要服务于人和AI Agent。而人和AI,对信息的消化方式截然不同——这一个根本差异,催生了AI时代全新的"文档分类学"。
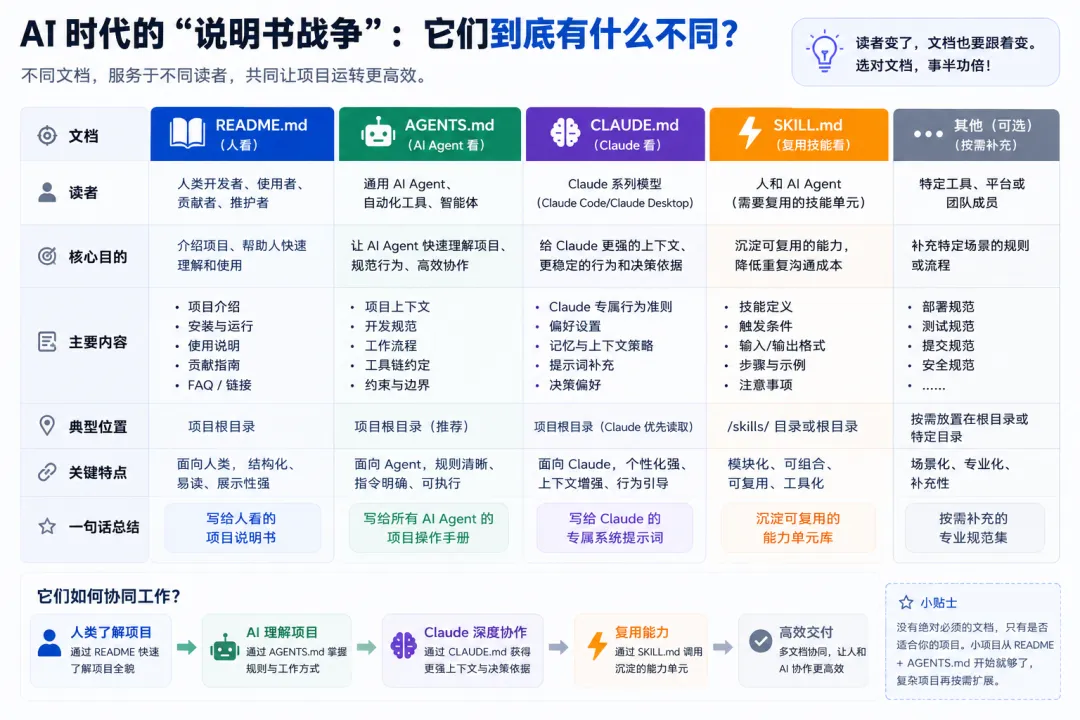
本文从信息架构角度,系统梳理这场变革中涌现的所有主要文档类型,帮你搞清楚:每种文件给谁看、在哪用、解决什么问题。
第一层:给人看的文档(Human-facing)
README.md — 项目的"门脸"
这是一切的起点。README.md出现于上世纪70年代Unix时代,本质是项目的第一印象,面向所有第一次接触这个项目的人类读者。
它回答的问题是:
这个项目是什么? 我怎么跑起来? 我怎么参与贡献?
README是被动文档——它安静地躺在那里,等人去读,不触发任何机器行为。这也是它的核心特征:面向人类的叙事结构,有温度,有背景,有故事。
但随着AI工具兴起,很多开发者开始把越来越多的技术细节塞进README,结果让它越来越臃肿。这个矛盾,正是AGENTS.md诞生的直接原因。
CHANGELOG.md / CONTRIBUTING.md / LICENSE.md
同属"给人看"的文档家族,各司其职:
CHANGELOG:版本历史,读者是用户和贡献者 CONTRIBUTING:贡献指南,读者是社区开发者 LICENSE:法律授权,读者是所有使用者
这些文件都遵循一个原则:以人类理解为第一优先级,信息结构服从于可读性,而非机器可解析性。
第二层:给AI编码助手看的文档(Agent-facing,项目级)
这一层是2024~2025年爆发的全新品类。核心需求来自一个根本性问题:
AI没有持久记忆。每次会话从零开始。
你每次打开Claude Code、Cursor或Codex CLI,它对你的项目一无所知——技术栈、编码风格、构建命令、测试流程……全要重新告诉它。没有这些文件,你会在每个会话里重复同样的上下文,效率极低。
AGENTS.md — AI时代的"跨平台通用标准"
诞生时间:2025年8月,由OpenAI发布
核心定位:A README for agents
——给AI coding agent看的README。
AGENTS.md是一个简单、开放的格式,给AI代码助手提供项目级的上下文和操作指引,包括构建步骤、测试流程、编码规范,以及任何对人类贡献者来说可能无关紧要、但AI需要知道的细节。
最关键的一步:2025年12月,Linux基金会宣布成立Agentic AI Foundation(AAIF),OpenAI将AGENTS.md贡献给该基金会,与Anthropic的MCP、Block的goose并列成为三大开放标准之一。参与方包括Google、Microsoft、AWS、Anthropic、Cloudflare、Bloomberg等巨头。
截至2026年初,AGENTS.md已被超过6万个开源项目采用,支持它的工具包括:GitHub Copilot、Cursor、Gemini CLI、Devin、Factory、Amp、VS Code等。
内容写什么?
Project Overview
Next.js 14 + PostgreSQL + Stripe的电商平台
Build
pnpm install && pnpm build
Test
pnpm test -- 所有PR必须通过测试
Code Style
使用函数组件,TypeScript strict模式 Server Components优先,除非需要客户端交互 与README的边界:AGENTS.md不取代README,而是互补。README给人看,保持简洁;AGENTS.md给AI看,可以写得更细、更结构化。
CLAUDE.md — Anthropic的"私有方言"
核心定位:Claude Code的专属项目记忆文件
发现机制:Claude Code启动时,从当前目录向上递归查找所有CLAUDE.md并合并加载。子目录的CLAUDE.md在Claude读取该目录文件时按需加载,形成树状分层记忆系统。
CLAUDE.md拥有一些AGENTS.md没有的独特能力:
@path语法:可以import其他文件,如See @docs/architecture.md,支持递归嵌套(最深5层)/init工作流:自动初始化项目记忆Auto Memory:Claude根据你的纠正和偏好自动写入 ~/.claude/projects/,形成自进化记忆** ~/.claude/rules/**:用户级别的全局规则,对所有项目生效
现实问题:截至2026年4月,Claude Code原生不支持AGENTS.md(GitHub上有上千人投票的issue在催促Anthropic)。目前社区标准的解决方案是symlink:
# 写AGENTS.md,然后建软链接
ln -s AGENTS.md CLAUDE.md
这样一个文件,两个工具都能读,内容永不漂移。
.cursorrules / .cursor/rules/*.mdc — Cursor的"方言"
Cursor最早普及了"项目规则文件"的概念,但格式只对Cursor生效。
旧格式: .cursorrules,根目录单文件,纯文本,已被标注为deprecated新格式: .cursor/rules/*.mdc,支持YAML frontmatter、glob pattern作用域,可以针对不同文件类型激活不同规则
优势:社区生态极其丰富,awesome-cursorrules收集了数千个框架专用规则 劣势:Cursor-only,其他工具完全无视这个文件
GEMINI.md / JULES.md / .windsurfrules / .clinerules...
同类文件的各家私有版本。每家AI工具都有自己的"记忆文件"命名:
内容90%相同,格式各异——这正是AGENTS.md作为统一标准被推动的历史背景。
第三层:可复用的AI技能包(Agent-facing,能力级)
SKILL.md — 超越项目边界的"可移植技能"
核心区别:前面所有文件都是"项目级"的——告诉AI这个项目是什么,怎么工作。SKILL.md是"任务级"的——告诉AI如何做一件特定的事情,与项目无关。
SKILL.md不描述项目,它描述一个可复用的工作流:如何做Code Review、如何写Commit Message、如何生成文档……
核心特性:
可移植:同一个SKILL.md在Claude Code、Codex CLI、Cursor、Gemini CLI等多个Agent上通用 模块化:独立安装、启用、禁用,互不干扰 触发式:不是每次都加载,而是当你的请求匹配时才激活(CLAUDE.md是每次必加载) 可发布:可以上传到技能市集(如Agensi、ClawHub)供他人使用
格式特征:YAML frontmatter + Markdown body
---
name:code-review
description:对PullRequest进行系统性代码审查,检查安全性、性能、可读性
---
# Code Review Skill
当用户要求review代码时:
1.检查安全漏洞...
2.分析性能瓶颈...
本质上,SKILL.md是AI时代的函数库。CLAUDE.md是应用上下文,SKILL.md是可调用的工具函数。
与CLAUDE.md的关系(一句话总结):
CLAUDE.md:让AI了解"我在做什么项目" SKILL.md:让AI掌握"这件任务该怎么做"
第四层:给AI爬虫/代理看的网站文档(Web-facing)
llms.txt — 网站的"AI导航地图"
诞生:2024年9月,由FastAI创始人Jeremy Howard提出
类比:如果把你的网站比作一个图书馆——
sitemap.xml是完整馆藏目录robots.txt是禁止进入的书架标签llms.txt是图书管理员的推荐阅读清单
它放在网站根目录(example.com/llms.txt),用Markdown格式列出:网站最重要页面的链接和描述,帮助AI代理快速理解网站结构,而不是让它费力解析复杂的HTML。
谁在用:Perplexity、Anthropic、Cursor、Stripe、ElevenLabs、Hugging Face、Cloudflare……
llms-full.txt:进阶版,把所有文档内容合并成单一Markdown文件,让开发者可以直接把一个URL粘进ChatGPT/Claude,即可获取完整上下文。相比HTML,可以减少高达90%的token消耗。
现实评估:目前仍是实验性标准,对SEO没有明确收益,主要价值在于让AI Agent使用你的API/SDK时更准确,对有开发者文档的产品更有意义。
第五层:新兴的"AI编程语言"(Program-facing)
program.md — Andrej Karpathy的极端实验
2026年初,特斯拉前AI总监Andrej Karpathy发布了autoresearch项目,其中整个人类的贡献只是一个叫program.md的Markdown文件——它直接驱动AI完成一整套研究流程。
这代表了Markdown角色的终极演变:从文档,到AI的程序代码。
这个趋势呼应了一个更大的判断:Markdown之所以成为AI时代的通用指令语言,原因有四:
在训练数据里大量存在,AI天然理解其结构语义 灵活不僵化,自由文本、结构表格、代码块可以共存 人可读,可审计,每一行指令一目了然,不像YAML config黑箱 Git友好,Agent行为的每次变更都是可追踪的commit
六维对比矩阵
| 主要读者 | ||||||
| 作用层级 | ||||||
| 加载时机 | ||||||
| 跨工具支持 | ||||||
| 是否有正式标准 | ||||||
| 典型内容 |
开发者实战策略
场景一:个人项目,只用Claude Code
README.md ← 给人看 CLAUDE.md ← 给Claude看
简单直接,不需要引入更多复杂度。
场景二:开源项目,多工具协作团队
README.md ← 给人看 AGENTS.md ← 跨工具通用上下文 CLAUDE.md ← 软链接到AGENTS.md(ln -s AGENTS.md CLAUDE.md) 一套内容,两个工具都读,永不漂移。
场景三:有自动化工作流需求
在项目中安装SKILL.md技能包,或发布自己的技能供社区使用。把可复用的工作流(代码审查、PR写作、文档生成)抽离成SKILL,而不是每次在提示词里重复。
场景四:有开发者文档的产品/API
在网站根目录增加llms.txt,列出最重要的API文档、Quickstart、参考手册的链接。特别是当你的用户会把你的文档喂给AI工具时,这一步有实际价值。
结语:文档的受众,决定文档的形式
AI时代的文档分类学,本质上是一个信息接收方多元化的问题:
README→ 写给第一次见面的人类 AGENTS.md→ 写给跨平台AI工具 CLAUDE.md→ 写给Claude,利用其独特能力 SKILL.md→ 写给任何Agent,封装可复用的"本领" llms.txt→ 写给游走在Web上的AI爬虫和代理 program.md→ 写给AI执行引擎,直接驱动任务
这些文件名各异,但都指向同一个趋势:**Markdown正在从"人类文档语言"变成"AI指令语言"**。
写好这些文件,不是技术细节,是AI时代的基础设施能力。
就像当年的工程师学会写注释、写单元测试,今天的开发者,要学会为AI写上下文。
作者:和我一起学AI
本文涵盖截至2026年5月的最新信息,部分标准仍在快速演进中。
