 夜雨聆风
夜雨聆风AI 认知笔记
AI认知笔记 2026.04
"学而不思则罔,思而不学则殆。"
导引
这个月尝试更多的 AI 使用,一边实践一边思考,才能不被信息的海洋淹没。国外,GPT-5.5 与 Claude Opus 4.7 接连发布,图像生成进入推理式时代,桌面操作则让 AI 从"问答工具"走向"操作代理"。国内,DeepSeek V4、Kimi K2.6、GLM-5.1 相继更新,国产模型已跟上生产级水平。
资讯盘点 · 本月发生什么
04.07 Anthropic 发布十万亿参数模型 Claude Mythos 5,因安全风险仅向审查合作方开放
04.08 智谱发布开源模型 GLM-5.1,SWE-bench Pro 首次超越 Claude Opus 4.6
04.10 OpenAI CEO Sam Altman 住宅遭燃烧瓶袭击,FBI 定性为针对 AI 从业者的暴力升级
04.16 Anthropic 发布 Claude Opus 4.7,距上代仅 70 天,编码与智能体任务提升显著
04.20 月之暗面发布并开源 Kimi K2.6,万亿参数 MoE,支持 300 子智能体协同
04.21 SpaceX 与 Cursor 达成协议,拥有年底前以 600 亿美元收购的选择权
04.22 OpenAI 发布 GPT-Image-2,具备推理能力,登顶 Image Arena 全部榜单
04.22 Google Cloud Next 确认苹果新一代 Siri 将基于 Gemini 定制
04.23 小米发布 MiMo-V2.5 全模态模型,主打 Agent 能力与百万 Token 上下文
04.24 OpenAI 发布 GPT-5.5,智能体原生,综合性能登顶基准测试
04.24 DeepSeek 发布 V4 并开源,首次将国产 AI 芯片与英伟达 GPU 并列写入硬件验证清单
04.27 SpaceX 加速太空 AI 生态布局,xAI 合并后估值 1.25 万亿美元
04.30 Anthropic 寻求以 9000 亿美元估值融资,年化营收 300 亿美元
信息解读
国外:OpenAI 与 Anthropic 在高性能模型上持续竞争
GPT-5.5 与 Claude Opus 4.7 在智能体任务和编码能力上均有明显提升。双方同步推进商业化——OpenAI Pro 版 API 高定价策略探索天花板,Anthropic 估值两个月内从 3800 亿升至 9000 亿美元。两家公司正在各行业加速渗透,而非单纯的整合并购。
国内:模型厂商持续迭代,国产算力取得关键进展
GLM-5.1 在开源领域挑战 Opus 4.6 基准成绩。Kimi K2.6 展示 300 子智能体协同能力。DeepSeek V4 首次将国产 AI 芯片与英伟达 GPU 并列写入硬件验证清单,华为昇腾、寒武纪、摩尔线程实现 Day 0 适配。
开源不等于免费,商业模式正在分化
多家模型选择开源(GLM-5.1、Kimi K2.6、DeepSeek V4),但路径不同。DeepSeek 和 Kimi 通过开源吸引开发者生态,智谱在开源同时将 API 提价至接近海外水平。MiniMax M2.7 采用商用受限协议——"模型免费、服务收费"的模式正在成型。
社会对 AI 的不安情绪有所显现
Sam Altman 住宅遇袭是一个值得注意的信号。当 AI 进入生产环境并影响就业结构时,社会层面的反弹可能增多,这一趋势需要持续观察。
图像生成能力显著提升,信息验证面临挑战
冲浪1:GPT Image 2 初体验的推理式图像生成意味着低成本逼真图像制作成为可能,对信息真实性验证提出新的要求。
AI 榜单
本月发布的重点模型在 Artificial Analysis 的多项指数上接受了评测。以下基于其 Intelligence Index、Coding Index 和 Agentic Index 三项指标,对本月的模型格局做一个梳理。
三个指标分别衡量什么:
Intelligence Index(智能指数):综合 10 项评估(GDPval-AA、SciCode、GPQA Diamond、IFBench 等),衡量模型的综合能力
Coding Index(编码指数):基于 Terminal-Bench Hard 和 SciCode 的加权平均,衡量编程任务表现
Agentic Index(智能体指数):基于 GDPval-AA 和 τ²-Bench Telecom,衡量自主完成复杂任务的能力
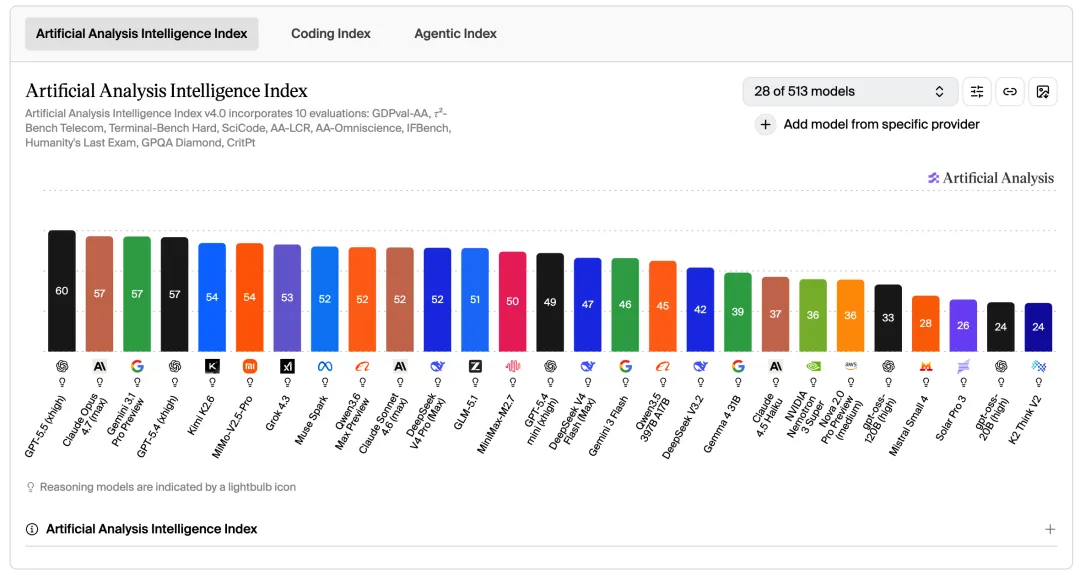
Intelligence Index
GPT-5.5 以 60 分领先。Claude Opus 4.7、Gemini 3.1 Pro Preview 和 GPT-5.4 均为 57 分。国内模型集中在 40-50 分区间,属于第二梯队。
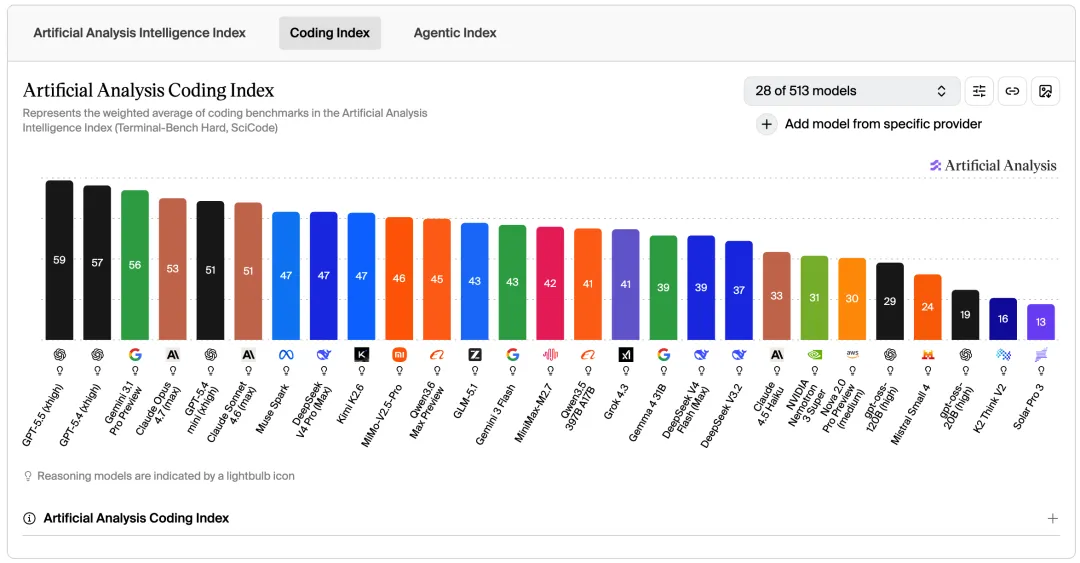
Coding Index
GPT-5.5(59分)、Gemini 3.1 Pro Preview(56分)、Claude Opus 4.7(53分)位居前三。三家包揽编码能力第一集团,国内模型差距较大。
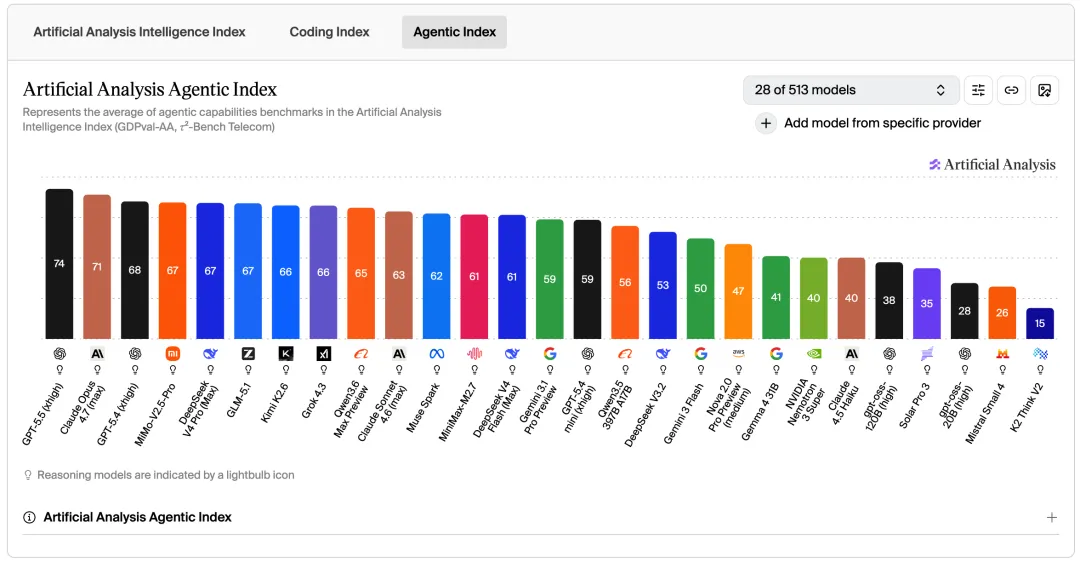
Agentic Index
GPT-5.5 以 74 分大幅领先,Claude Opus 4.7 获 71 分。国内模型表现亮眼——MiMo-V2.5-Pro、DeepSeek V4 Pro、GLM-5.1 均在 67 分梯队。
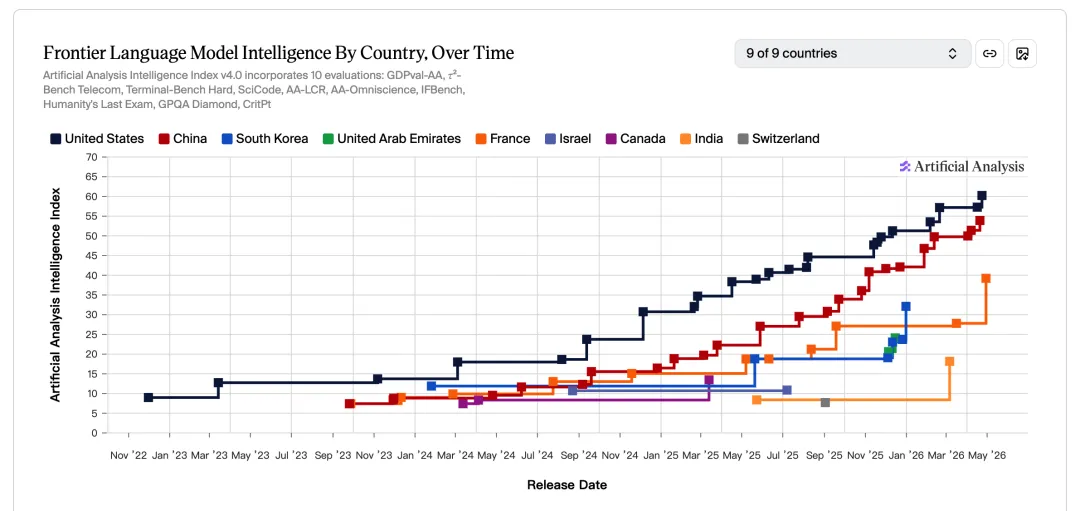
中美差距
中国模型在智能指数上大约落后美国 3-4 个月,差距在缩小。其他国家与中美存在明显断层。
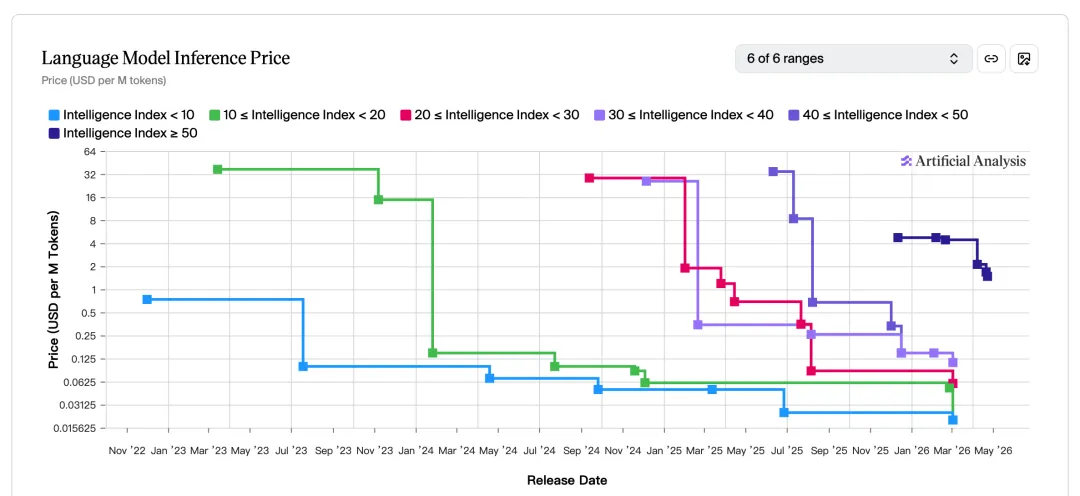
价格趋势
高智能模型推理价格已降至 1.x 美元/百万 Token,降价趋势持续,更多应用场景将被解锁。
实战心得 · 现在 AI 能做什么
Claude Code + 国内模型 组合已可应对大多数实际工作场景,兼顾成本与效果
阿里云终端支持原生 Agent,终端可自动识别文字或命令,交互从对话走向任务执行
Kimi.com Agent 集群 可端到端完成报告、文档等任务,效果接近在线版 Agent(留坑后续研究)
GPT-5.5 和 Claude Opus 4.7 已支持接入桌面操作,实现更深层系统控制(留坑继续研究)
个人洞察 · AI 会走向何方
效率提升的瓶颈在哪里?
从"裁员潮会开始吗"演化而来。技术不再是问题——组织结构、为人构建的基建、人机交互界面将成为效率瓶颈。
Agent 将如何演进?结
逐步进入工作和生活,不再讨论。
科研的边界在哪里?
引领新思路、定义新问题的能力重要。需要尝试自己构建 AI 科研系统。
软件开发会被颠覆吗?结
必然颠覆,不再讨论。
大模型开源生态会走向何方?
惊喜发现国内模型除了 Qwen 都在走开源。开源利好更多服务商,可布局垂类领域模型市场。
算力与模型如何共生?结
问题超前,短期不再讨论。
教育的本质将发生什么改变?
计算机将成为通识课程,AI 使用能力成为必备技能。计算机专业会存在但更关注量子计算、AI 算法研究等深度方向。
国内算力芯片是否会走向自给新
模型和芯片层面:能。但芯片设计、设计工具、芯片制造三块——走向自给还有距离。
AI 的应用边界在哪里新
边界不在于 AI 能做什么,而在于人能控制什么。不同地方因人的能力不同而边界不同。
AI 是否会带来危险新
会。危险来自人为滥用、系统失控、权限放大三个维度——便捷性和风险性同步提升。
总结
首先,关注你的身心健康。AI 发展再快,身体依然是本钱。
这个月最大的感受是:国内 AI 已经到了生产级,可以更快地构建你想完成的事。不要被信息覆盖,多去尝试。
Kimi Agent 集群、GPT-5.5 的桌面操作能力、AI 科研系统……都值得后续深入研究。信息在爆炸,时间有限,挑最感兴趣的下手。只有真正用过,才能知道它能帮到你什么。
欢迎 点赞 · 转发 · 评论
