 夜雨聆风
夜雨聆风DeepSeek-V4-Flash发布后,不少打工人遇到一个问题:老板要求本地部署该模型,但一看提供的设备,只是普通的消费级显卡。
老板想要花小钱办大事,这种情况应该要如何应对?本文试从学术角度来讨论这一问题。
大模型所需显存空间构成
大模型部署通常受到两方面的显存限制:一方面是模型参数本身的存储开销,另一方面是推理过程中产生的 KV Cache 开销,工程上一般会留 10% 左右的总显存作为安全余量,避免碎片化、临时 buffer、CUDA graph 等导致显存溢出。
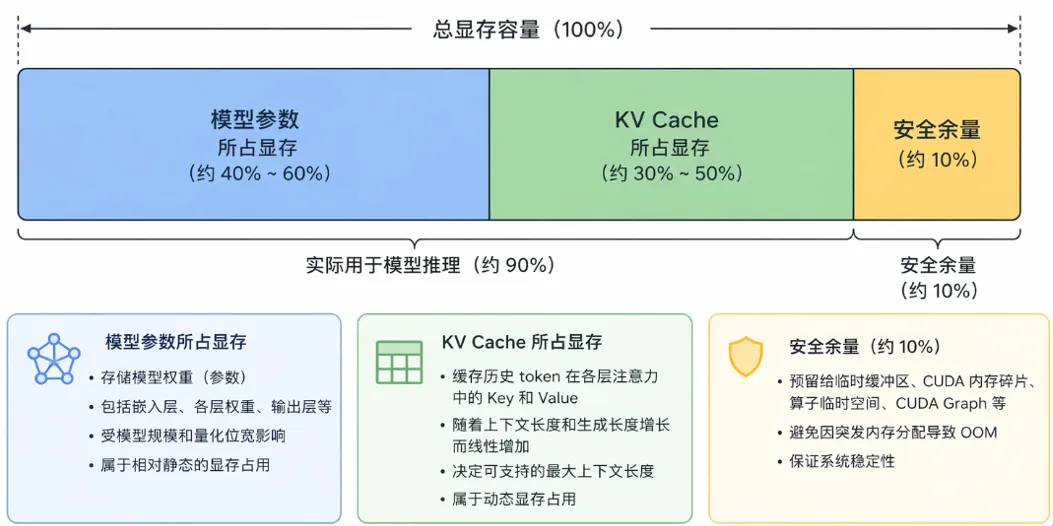
KV Cache 是在 Transformer 自回归推理过程中,对历史 token 在各层注意力模块中计算得到的 Key(键) 和 Value(值) 进行缓存。这样在生成下一个 token 时,模型无需重新计算前面所有 token 的注意力表示,只需在已有缓存基础上继续计算,从而显著提升推理效率。但与此同时,这部分缓存会随着序列长度线性增长,因此在长文本生成、多轮对话和大并发服务场景下,会带来显著的显存压力。
研究方向
为了部署更大参数量的模型,通常会压缩精度或降低速度的方式。
精度换空间
“精度换空间”主要是指通过量化(Quantization)等模型压缩手段,将原本采用 BF16、FP16 等高精度格式存储的模型权重、激活值或 KV Cache 转换为 8bit、4bit 乃至更低位宽表示,从而显著降低模型存储开销和推理显存占用。
(1)模型参数量化
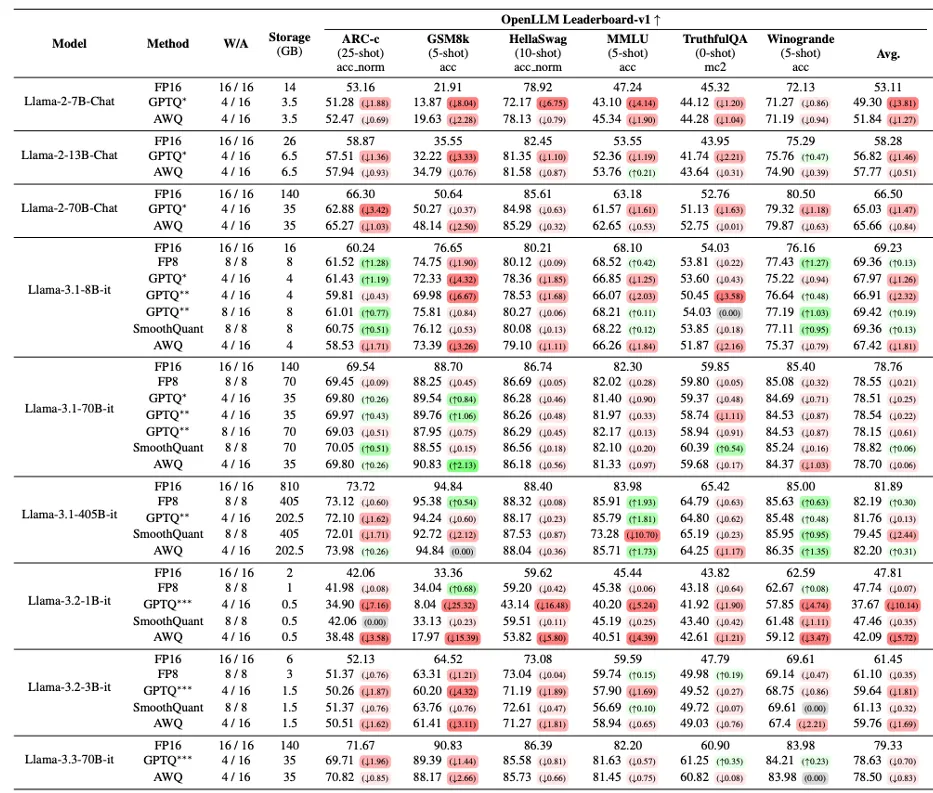
近几年常见的模型参数量化如下表所示。
表中的模型权重为W,在推理前向传播过程中产生的激活值为A,上述方法中有些是仅针对模型权重本身进行量化,有些是针对两者联合进行量化。
模型量化后,往往会产生性能损失,根据文章[21]的实验结论,精度从16位量化到8位,损失并程度并不明显,量化到4位,则会产生明显掉点,最多会出现20%的性能衰退。
(2)KV Cache参数量化
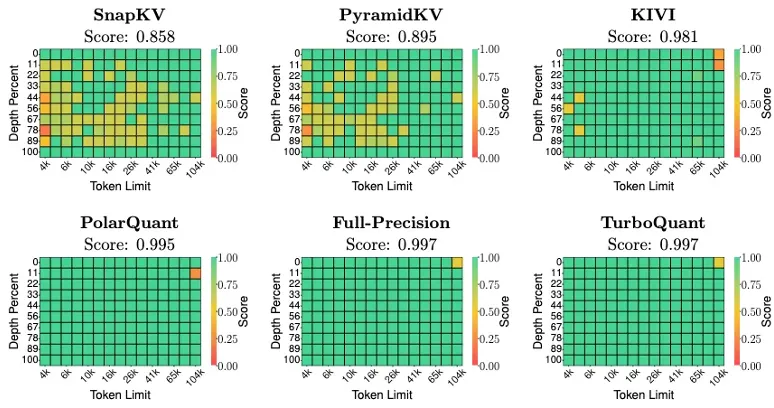
近几年常见的KV Cache参数量化如下表所示。
KV Cache做量化的空间比模型参数量化的空间大一些,以Google最新的TurboQuant[22]为例,对KV Cache做了约4倍量化(16->4)后,精度仍然能保持99.7%。
速度换空间
“速度换空间”主要是指在模型参数规模过大、显存无法完整容纳模型权重或长上下文推理过程中 KV Cache 占用过高的情况下,不再单纯依赖低比特量化压缩模型表示,而是通过CPU-GPU 异构卸载、分层加载、KV Cache 卸载、按需重算以及混合注意力计算等方式,将原本需要常驻显存的数据转移到 CPU 内存甚至磁盘中,以增加数据搬运与额外计算时间为代价,换取更大的模型部署能力。
与“精度换空间”相比,这类方法通常不会直接改变模型参数本身的数值精度,因此模型能力保持相对稳定,但其代价在于推理速度下降、端到端时延增加,尤其在长上下文和超大模型场景下更为明显。
近几年常见的模型空间优化方法如下表所示。
使用这类方法会造成模型的吞吐量大幅降低,通常会降低10倍以上,仅适用于对“时延不敏感”的离线推理场景。
总结
想要在硬件受限的情况下部署大参数模型,要么就是牺牲精度,要么就是牺牲速度,天下没有免费的午餐。
对实际应用来说,主要还是区分应用场景,比如应用场景是让模型去清洗数据这种无强时效性的场景,可以优先选择 CPU offload 的思路;如果是实时对话,那只能从量化和压缩的角度考虑。
参考文献
[1] Dettmers T, Lewis M, Belkada Y, et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale[EB/OL]. 2022.
[2] Frantar E, Ashkboos S, Hoefler T, et al. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers[EB/OL]. 2022.
[3] Xiao G, Lin J, Seznec M, et al. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models[EB/OL]. 2022.
[4] Lin J, Tang J, Tang H, et al. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration[EB/OL]. 2023.
[5] Shao W, Chen M, Zhang Z, et al. OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models[EB/OL]. 2023.
[6] Ashkboos S, Mohtashami A, Croci M L, et al. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs[EB/OL]. 2024.
[7] Liu Z, Zhao C, Fedorov I, et al. SpinQuant: LLM Quantization with Learned Rotations[EB/OL]. 2024.
[8] Sun Y, Liu R, Bai H, et al. FlatQuant: Flatness Matters for LLM Quantization[EB/OL]. 2024.
[9] Elangovan R, Sakr C, Raghunathan A, et al. BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference[EB/OL]. 2025.
[10] Kim S, et al. ReSpinQuant: Efficient Layer-Wise LLM Quantization via Residual Subspace Rotation[EB/OL]. 2026.
[11] Dadgarnia A, Tabesh S, Nikdan M, et al. GSQ: Highly-Accurate Low-Precision Scalar Quantization for LLMs via Gumbel-Softmax Sampling[EB/OL]. 2026.
[12] Liu Z, Yuan J, Jin H, et al. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache[EB/OL]. 2024.
[13] Hooper C, Kim S, Mohammadzadeh H, et al. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization[EB/OL]. 2024.
[14] He Y, Zhang L, Wu W, et al. ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification[EB/OL]. 2024.
[15] Cai Z, Zhang X, Tan Z, et al. NQKV: A KV Cache Quantization Scheme Based on Normal Distribution Characteristics[EB/OL]. 2025.
[16] Tomar A, Hooper C, Lee M, et al. XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization[EB/OL]. 2025.
[17] Yang H, et al. XQuant: Achieving Ultra-Low Bit KV Cache Quantization with Cross-Layer Compression[EB/OL]. 2025.
[18] Cheng W, et al. QAQ: Quality Adaptive Quantization for LLM KV Cache[EB/OL]. 2025.
[19] Jia J, Li J, Zhou Z, et al. SAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving[EB/OL]. 2026.
[20] Boroujeni S P H, Mehrabi N, Woods P, et al. Don’t Waste Bits! Adaptive KV-Cache Quantization for Lightweight On-Device LLMs[EB/OL]. 2026.
[21] Lee J, Park S, Kwon J, et al. Exploring the trade-offs: Quantization methods, task difficulty, and model size in large language models from edge to giant[J]. arXiv preprint arXiv:2409.11055, 2024.
[22] Zandieh A, Daliri M, Hadian M, et al. Turboquant: Online vector quantization with near-optimal distortion rate[J]. arXiv preprint arXiv:2504.19874, 2026
[23] Rajbhandari S, Ruwase O, Aminabadi R Y, et al. ZeRO-Inference: Democratizing Massive Model Inference[EB/OL]. 2022.
[24] Sheng Y, Zheng L, Zhong C, et al. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU[EB/OL]. 2023.
[25] Wu J, Yin S, Liu S, et al. LM-Offload: Performance Model-Guided Generative Inference of Large Language Models with Parallelism Control[EB/OL]. 2024.
[26] Chen H, et al. KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models[EB/OL]. 2025.
[27] Tomar A, Hooper C, Lee M, et al. XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization[EB/OL]. 2025
