 夜雨聆风
夜雨聆风Multi-Agent 大爆发:AI 从「个人助手」进化为「研发团队」
AI 辅助编程的终极形态 —— 不再是「一个 AI 帮你写代码」,而是「一支 AI 团队替你开发软件」。
一、为什么需要 Multi-Agent?
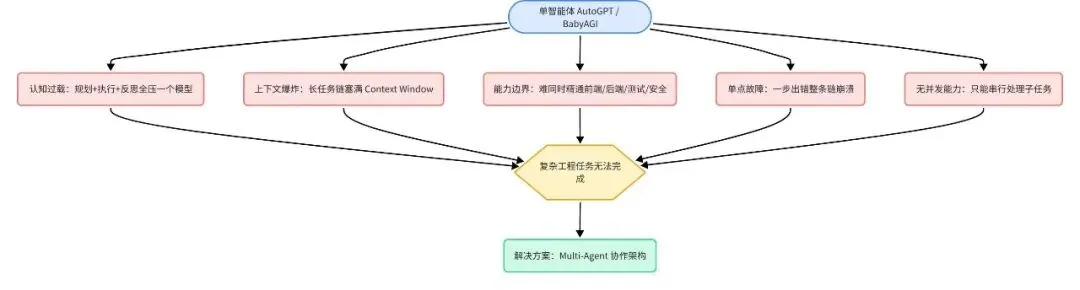
单智能体(如 AutoGPT、BabyAGI)的失败案例揭示了一个结构性问题:当你让一个 Agent 完成「帮我开发一个电商网站」这类复杂任务时,它会在第 5-8 步因上下文溢出或工具调用失败而崩溃,并进入无限重启循环。
这不是模型能力的问题,而是单智能体架构本身的结构性缺陷 —— 就像让一个程序员同时担任 CEO、架构师、前端、后端、测试、运维。
人类软件工程师团队已经用几十年的实践证明了分工协作的必要性:一个 10 人团队能完成一个人 100 倍的工作量,不只是因为人数多了,更是因为专业分工带来了质的提升。Multi-Agent 架构把这个朴素的管理哲学迁移到了 AI 世界。
一个具体的对比数据:Stanford 和 Google 的研究者在 2023 年测试了「生成一个完整的 CRUD 应用」任务:单智能体平均耗时 47 分钟且成功率仅 23%,而 3-Agent 协作系统耗时 12 分钟、成功率达到 71%。任务越复杂,Multi-Agent 的优势越明显。
📊 图一:单智能体五大瓶颈分析
二、演化历程:从 ChatDev 到 300 个并行 Agent

📊 图二:Multi-Agent 演化时间线
AutoGPT(2023.03)—— 单智能体时代的开山鼻祖
AutoGPT 的出现第一次让普通人看到了「AI 自主行动」的可能:给它一个目标,它会自己分解任务、搜索信息、写代码、反思结果。2023 年 3 月发布后 48 小时内 GitHub Star 数突破 2 万,成为当时增长最快的开源项目之一。
但 AutoGPT 的失败与它的成功一样有名——它经常在复杂任务中「迷失」:不断给自己创建子任务,陷入循环,或者在某一步工具调用失败后完全停顿。这些失败为 Multi-Agent 时代埋下了伏笔:问题不是模型不够强,而是架构不对。
ChatDev(2023.08)—— 最早证明 AI 团队协作可行
清华大学发布的 ChatDev 是第一个让多个 AI 角色(CEO、CTO、程序员、测试员)分工协作的系统,核心机制是「通信式代理(Communicative Agents)」:
每两个角色之间进行双向对话,直到达成共识 引入「思维指导(Thought Instruction)」防止角色偏离职责 通过**记忆流(Memory Stream)**让每个 Agent 能回顾历史对话 采用「批评-修正」循环:每次输出都由另一个 Agent 审查,减少幻觉
ChatDev 惊人成果(2023 年论文数据):
平均只需 7 分钟完成一个小型软件项目 平均花费不到 $1(约 0.74 美元) 完整输出:需求文档、设计图、代码、测试报告、用户手册 在 70 个真实需求测试中,代码可运行率达到 86.66%
ChatDev 的核心洞察在于:把人类软件工程中的「角色协作」直接迁移到 AI 系统,不需要单个模型无所不能,每个 Agent 只需在自己的专业领域表现优秀。
MetaGPT(2023.09)—— 把公司 SOP 编码进系统
MetaGPT 最独特的设计是把 SOP(标准作业程序)编码到系统中,并通过发布/订阅模式防止「级联幻觉」—— 每个角色只接收与自己职责相关的消息:
classProductManager(Role): name = "Alice" goal = "创建一个成功的产品" skills = ["需求分析", "用户调研", "PRD 写作"]classArchitect(Role): name = "Bob" goal = "设计优雅且实用的系统架构" skills = ["系统设计", "技术选型", "架构图绘制"]MetaGPT 的另一个创新是结构化输出:每个 Agent 不是输出纯文字,而是输出 JSON Schema 定义的结构化数据(PRD 文档、API 设计、代码文件等),下游 Agent 读取的是结构化产物而非对话文本,这大幅减少了信息在传递过程中的损耗。
MetaGPT 后来被扩展为 Data Interpreter 版本,专注数据科学任务,在 SciCode 基准上的表现超过了 GPT-4。
AutoGen 2.0(2024.06)—— 事件驱动的异步革命
AutoGen 2.0 放弃旧版同步对话模式,改为完全事件驱动的异步架构:
每个 Agent 是独立的事件处理器(Event Handler) 支持 gRPC 跨进程、跨机器部署 内置 Docker 容器隔离,代码执行安全 内置 Magentic-One 模块:一个通用 Web 任务智能体,可操控浏览器和文件系统 目前最适合生产环境大规模部署的 Multi-Agent 框架
微软内部已将 AutoGen 用于多个企业级场景,包括 GitHub Copilot 的部分后台任务链和 Azure AI Studio 的工作流自动化。
三、里程碑:Devin 的工作原理
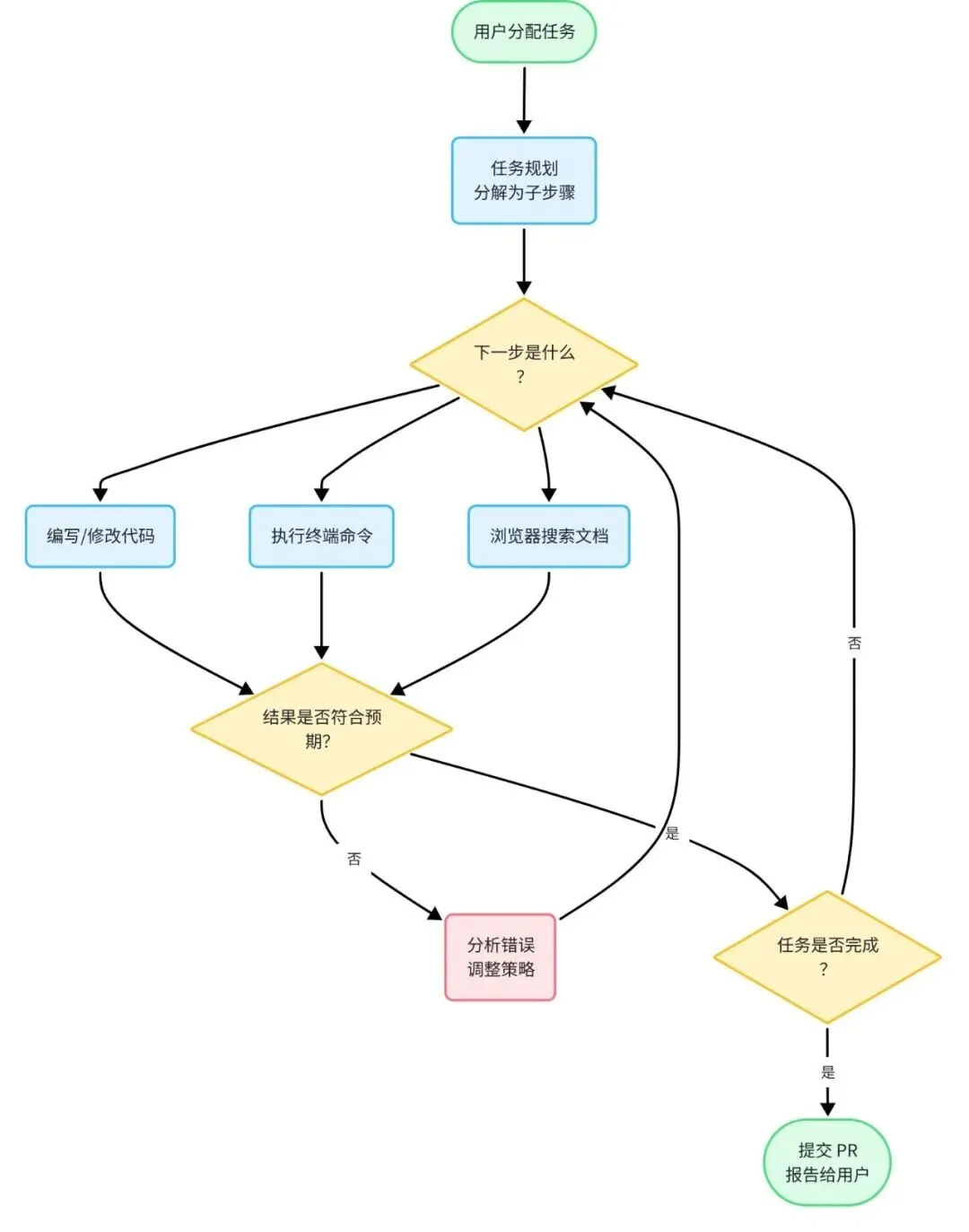
Devin 是 Cognition AI 于 2024 年 3 月发布的全自主 AI 软件工程师,首次在 SWE-bench 上突破 13% 准确率(此前最高 4.8%),震惊业界。
Devin 的核心与其说是「更强的模型」,不如说是更完整的工具集成和更长的任务执行能力。它拥有一个和真实程序员几乎相同的工作环境:代码编辑器、终端、浏览器、Git,并且能在数小时内持续运行而不需要人工干预。
Devin 的四大核心能力:
长期规划:把「开发一个完整 Web 应用」分解成数百步,遇到错误会绕过或修复,而非放弃。Devin 的「规划器」会随着任务推进动态调整计划,这和 AutoGPT 一开始固化计划的做法截然不同。 自主学习:遇到陌生技术会主动搜索文档、阅读 README、在沙箱中测试。有案例记录 Devin 在完成任务中途自学了一个它之前从未接触过的 Rust crate,整个过程无人干预。 端到端部署:不只生成代码,还能创建 GitHub 仓库、配置 CI/CD、部署到 Vercel/AWS。这是真正意义上的「从 0 到上线」,而不只是「从 0 到代码文件」。 主动协作:主动报告进度、遇到模糊需求主动提问、发现潜在风险主动提醒。Devin 会在完成任务后发送一份简洁的执行摘要,说明做了什么、遇到了什么问题以及如何解决的。
Devin 之后的竞争者:
Devin 发布后,SWE-bench 迅速成为 AI 编程能力的「战场」。OpenDevin(开源版本 Devin)在社区推动下迅速追上,Google 的 AlphaCode 2 和微软的 CodeAct 也相继发布。Devin 最重要的意义不在于它的准确率数字,而在于它证明了「全自主 AI 工程师」不是科幻,而是工程问题。
Devin 的实际局限:
对需要深度领域知识的任务(如复杂量化金融算法)表现一般 超长任务(超过 100 步)容易「迷失方向」,需要人工在关键节点介入 每次完整任务可能消耗数十美元的 API 费用 对需要视觉感知的 UI 调试任务(如「这个按钮看起来不对」)支持有限
📊 图三:Devin 内部工作循环
四、三大架构模式
📊 图四:三大架构模式对比

分层协作(Hierarchical)深度解析
分层协作是目前最主流的架构,本质上是「Orchestrator-Worker 模式」。Orchestrator(协调者)负责:
任务分解(Task Decomposition):把用户需求拆成若干可独立执行的子任务 Worker 选择:根据子任务类型选择合适的 Worker Agent(前端专家 vs 后端专家 vs 安全审计员) 结果整合:收集各 Worker 的输出,检查一致性,合并成最终结果 冲突解决:当两个 Worker 的输出互相矛盾时(如前端假设 API 返回格式 A,后端实际返回格式 B),由 Orchestrator 仲裁
实战案例:Claude Code 的 Agent Teams 功能就是典型的分层架构——当你执行一个大型重构任务时,Claude Code 会启动多个子 Agent 并行处理不同的模块,最后由主 Agent 合并变更、解决冲突。
管道流水线(Pipeline)深度解析
Pipeline 架构适合有明确阶段顺序的任务,每个阶段的输出是下一个阶段的输入,就像工厂的流水线。它的核心优势是每个阶段可以独立优化和替换——如果测试阶段发现问题,只需要回退到编码阶段,而不需要重新进行需求分析。
MetaGPT 和 ChatDev 都是典型的 Pipeline 架构:需求 → PRD → 架构设计 → 代码 → 测试 → 文档,每一步都有专门的 Agent,每一步的产出都是结构化的文档或代码。
去中心化(Decentralized)深度解析
去中心化架构中,没有中央协调者,所有 Agent 通过读写共享状态来协调——最常见的共享状态就是 Git 仓库。每个 Agent 看到仓库的当前状态,自主决定下一步做什么。
这个架构的灵感来自自然界的群体智能(蚁群、蜂群),每个个体只遵循简单规则,整体却能完成复杂任务。Kimi K2.6 的 300 并行 Agent 本质上就是去中心化架构——每个 Agent 从任务队列取任务、提交到共享仓库,不需要中央协调者逐一指挥。
如何选择合适的架构?
任务是否有明确的阶段划分? ├── 是 → 管道流水线(Pipeline) └── 否 → 任务是否需要全局协调? ├── 是 → 分层协作(Hierarchical) └── 否 → 去中心化(Decentralized)实际项目中,三种架构往往混合使用:外层是分层协作(一个 Orchestrator 调度多个专家 Agent),内层某些专家 Agent 之间是 Pipeline(设计 → 实现 → 测试),在大规模任务中底层又会用去中心化的并行策略。
五、主流框架横向对比
| LangGraph | |||
| AutoGen | |||
| CrewAI | |||
| MetaGPT | |||
| OpenAI Agents SDK | |||
| Claude Code |
框架选型实战指南
LangGraph 是目前控制粒度最细的框架。它的核心概念是「状态图(State Graph)」—— 你把整个工作流定义为有向图,每个节点是一个处理函数,边上可以有条件判断(「如果测试失败,回到编码节点」)。适合需要复杂分支逻辑和状态持久化的场景。缺点是学习曲线较陡,对新手不友好。
from langgraph.graph import StateGraphgraph = StateGraph(AgentState)graph.add_node("planner", plan_step)graph.add_node("coder", code_step)graph.add_node("tester", test_step)graph.add_conditional_edges("tester", should_retry, {"retry": "coder", "done": END})CrewAI 是上手最快的框架,5 分钟能跑起第一个 Multi-Agent 系统。它用「Crew + Role + Task」三个概念抽象掉底层细节,适合快速验证想法和不需要精细控制的场景。生产环境下的灵活性不如 LangGraph。
OpenAI Agents SDK 的独特之处在于 Handoff(任务转交) 机制:Agent A 处理任务途中可以把整个上下文转交给更合适的 Agent B,类似人工客服的「转接」操作。与 GPT-4o 的工具调用深度集成,如果你的技术栈全在 OpenAI 生态里,这是最顺畅的选择。
SWE-bench 军备竞赛
SWE-bench 是普林斯顿大学发布的 AI 编程能力评测基准,包含来自 12 个真实 GitHub 仓库的 2294 个真实 Issue(Django、Flask、NumPy、Matplotlib、Sympy 等)。评测方式:给 AI 看 Issue 描述和代码库,让它生成代码修复方案,用原始测试套件验证。
SWE-bench 的难点在于它不只考察「写代码的能力」,而是考察「在真实大型代码库中定位问题、理解上下文、生成可合并的 PR」的全流程能力。这些真实 Issue 平均每个涉及 23 个文件的改动,代码库平均超过 10 万行。
准确率数字在快速提升,但这个「军备竞赛」也引发了一些反思:SWE-bench 本身有没有被「刷榜」的问题?部分研究者指出,一些系统可能针对基准的特定题目做了优化,真实场景下的泛化能力未必与排行榜数字一致。更全面的评测体系(如 SWE-bench Verified、Aider Polyglot Benchmark)正在被提出。
Kimi K2.6 的 PARL 训练机制
Moonshot AI 的突破在于用强化学习训练 Agent 的并行协作能力,这套机制被称为 PARL(Parallel-Agent Reinforcement Learning):
环境构造:给模型一个真实的 Git 仓库 + Issue,让它自主决定是否启动子 Agent、启动多少个、分配什么子任务 奖励设计:根据最终任务完成质量(测试通过率、代码可读性评分)给予奖励,而不是对中间步骤打分 并行策略学习:模型逐渐学会「什么时候值得并行、如何分配任务最高效、并行 Agent 之间如何避免冲突」 规模效应:从 8 个并行 Agent 训练到 300 个并行 Agent,模型的协调策略随规模同步优化
K2.6 的并行能力是内化在权重里的,而非代码写死的逻辑,能根据任务复杂度动态调整并行策略。这与「用 LangGraph 硬编码工作流」有本质区别——K2.6 自己能决定「这个任务需要 5 个 Agent 还是 50 个」。
在一次公开的性能测试中,K2.6 用 300 个并行 Agent 完成了一个撮合引擎的全面重构,整体吞吐量提升 185%,全程 13 小时,无需人工干预。
六、Agent 间通信协议演化
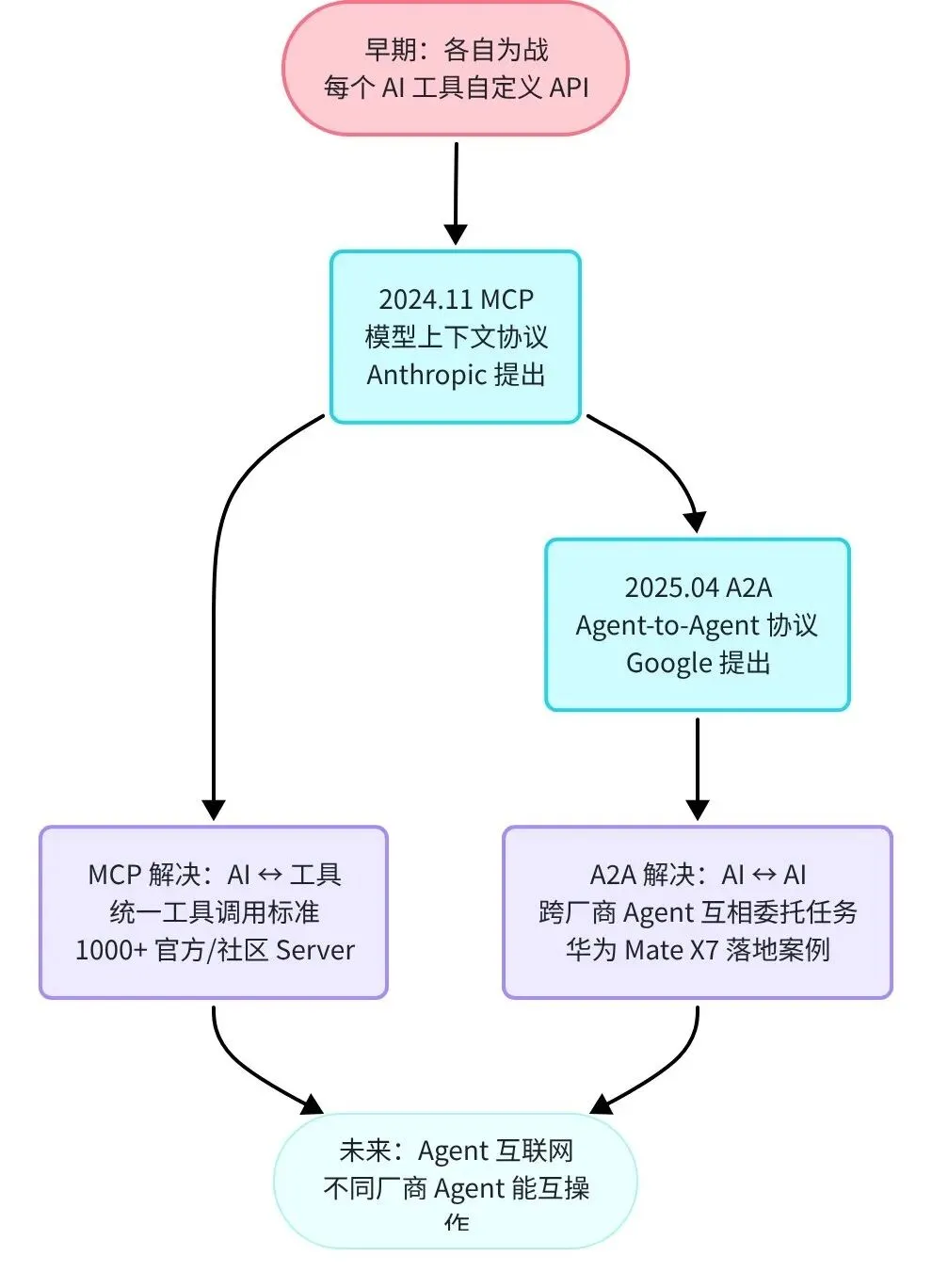
MCP 和 A2A 的出现,标志着 Multi-Agent 生态正从「各自为战」走向「互联互通」。就像 HTTP 协议统一了 Web 世界的通信方式,MCP 和 A2A 正在成为 AI Agent 世界的「基础设施」。
📊 图五:Agent 通信协议演化
MCP(Model Context Protocol)详解
为什么需要 MCP? 在 MCP 出现之前,每接入一个外部工具(GitHub、Jira、数据库),开发者都需要写一套专门的集成代码,格式不统一,维护成本极高。MCP 提供统一标准,就像 USB 接口统一了外设连接方式。
MCP 的核心三要素:
Tools:Agent 可调用的函数(如执行 SQL、搜索代码库、发送邮件) Resources:Agent 可读取的数据(如文件、数据库行、API 响应) Prompts:预设的提示模板(如「代码审查模式」「安全扫描模式」)
一个 MCP Server 的最小实现示例:
from mcp import MCPServer, toolserver = MCPServer("my-db-server")@server.tool()defquery_database(sql: str) -> list[dict]:"""执行 SQL 查询并返回结果""" conn = get_db_connection()return conn.execute(sql).fetchall()if __name__ == "__main__": server.run()配置到 Claude Desktop 的 claude_desktop_config.json 后,Claude 就能直接调用 query_database 工具,就像调用内置工具一样自然。
目前 MCP 已有超过 1000+ 个官方和社区 Server,覆盖:GitHub、Google Drive、数据库(PostgreSQL、MySQL、SQLite)、浏览器控制(Puppeteer)、Slack、Jira、Linear、AWS、Kubernetes 等几乎所有主流工具。
A2A(Agent-to-Agent Protocol)详解
Google 于 2025 年提出的 A2A 协议,解决不同 AI 系统之间如何互相委托任务的问题。MCP 是「AI 如何使用工具」,A2A 是「AI 如何委托给另一个 AI」:
Agent A(Claude)可以委托任务给 Agent B(Gemini),B 完成后返回结果 双方不需要知道对方的内部实现 类似微服务架构中的服务发现和远程调用 支持长时间异步任务:Agent B 可以花数分钟完成任务,完成后回调通知 Agent A
A2A 的真实落地案例:华为 Mate X7 搭载的跨模型 Agent 协作系统,本地端侧 Agent(小模型)处理日常任务,遇到复杂问题时通过 A2A 委托给云端大模型 Agent,完成后结果回传。这让手机 AI 既有实时响应(本地小模型),又有高质量输出(云端大模型),而用户感知到的是一个统一的 AI 助手。
MCP vs A2A 的分工
两者不是竞争关系,而是互补:一个完整的 Multi-Agent 系统往往同时用 MCP(连接外部工具)和 A2A(Agent 之间协作)。
七、AgentOS:Multi-Agent 的操作系统
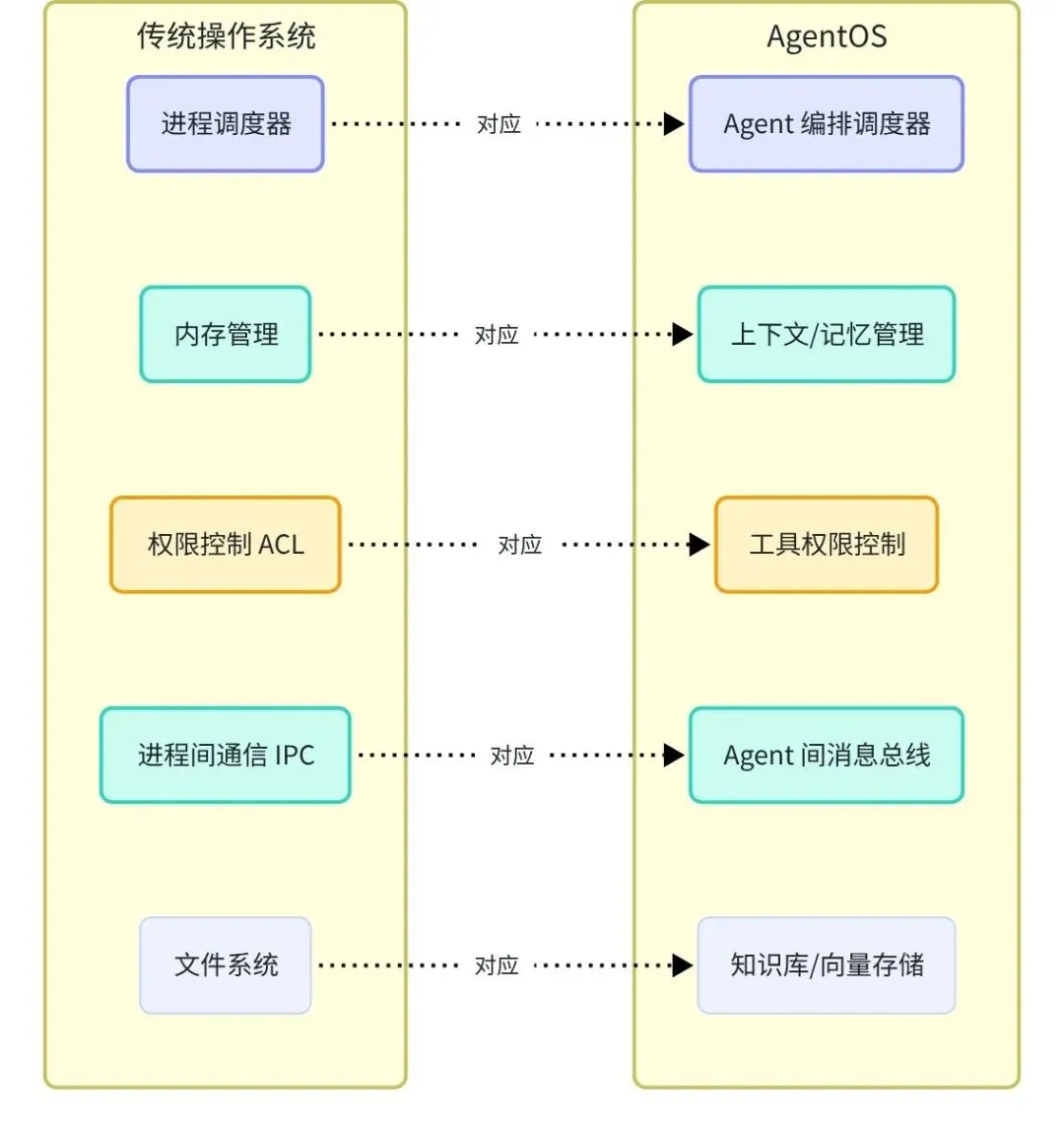
AgentOS 是一个类比概念——就像操作系统管理进程,AgentOS 管理多个 AI Agent 的生命周期、权限和协作。这个概念在 2025-2026 年间迅速从学术讨论变为工业落地,各大云厂商都在构建自己的 AgentOS 层。
📊 图六:AgentOS vs 传统 OS 类比
AgentOS 的五大核心功能
① Agent 编排调度器:决定何时启动哪些 Agent、分配多少算力资源、任务优先级排序。类似 Linux 的进程调度器,但需要额外处理「Agent 能力匹配」—— 选择最适合特定任务的 Agent,而不只是「有空的」Agent。
② 上下文/记忆管理:解决「Agent 如何记住之前发生的事」的问题。短期记忆(当前任务上下文)存在 in-context,长期记忆(历史经验、用户偏好)存在向量数据库。AgentOS 负责在两者之间做智能检索和注入。
③ 工具权限控制:每个 Agent 只能访问被明确授权的工具。一个前端 Agent 不应该能直接执行数据库删除操作,一个文档整理 Agent 不应该能向外部 API 发送请求。细粒度的权限控制是企业级 AgentOS 的核心安全基础。
④ Agent 间消息总线:提供异步的 Agent 间通信机制。Agent A 完成任务后把结果发布到消息总线,Agent B 订阅感兴趣的消息类型,自动触发。这比「A 直接调用 B」更解耦,更容易扩展。
⑤ 知识库/向量存储:企业知识(内部文档、代码库、历史决策)的统一存储和检索接口。所有 Agent 通过同一个知识库接口获取背景知识,保证一致性,避免不同 Agent「各说各话」。
真实的 AgentOS 实现(2026 年)
Anthropic Claude.ai Teams:
组织级 Agent 管理面板,支持创建「AI 员工」并分配职责 细粒度工具权限控制(哪个 Agent 能访问哪些 MCP Server) Agent 执行历史追踪和审计日志,满足企业合规要求 高风险操作(发送外部邮件、修改生产数据库)需要人类管理员确认
微软 Azure AI Foundry:
企业级 Agent 部署和监控平台,与 Azure Active Directory 权限体系深度集成 支持 Agent 的自动扩缩容(任务高峰期自动增加 Agent 实例) 内置成本管理:每个 Agent 任务的 Token 消耗和费用实时可见 与 Microsoft 365 深度集成,Agent 可直接操作 Teams、Outlook、SharePoint
OpenAI Operator 模式:
Agent 获得浏览器控制权,替用户完成网页操作(订票、填表、购物) 内置「危险操作确认」机制,金额超过阈值或操作不可逆时强制暂停询问用户 完整操作审计链,每一步操作都有截图记录
AWS Bedrock Multi-Agent:
支持跨 AWS 服务的 Agent 工作流(S3、RDS、Lambda、SageMaker 全链路打通) 原生支持 Claude、Titan、Llama 等多个模型作为不同 Agent 的底座 与 AWS IAM 集成,Agent 的权限管理与现有 AWS 资源权限体系无缝衔接
八、开发者角色的重构
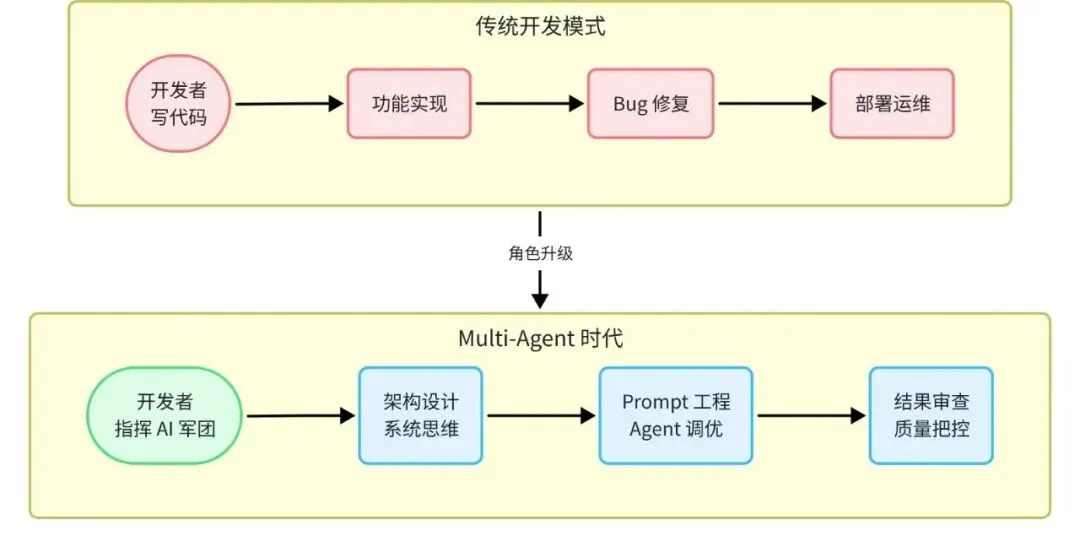
📊 图七:开发者角色演进
角色转变的本质
这不是「程序员被替代」,而是「程序员的工作层级上移」。类比一下:CAD 软件没有让建筑师消失,而是让建筑师不再需要手工绘制每一条线——建筑师把时间用在更有价值的创意设计和系统思考上。
Multi-Agent 时代的程序员,越来越像软件架构师 + 技术产品经理 + AI 训练师的综合体:
架构师视角:决定整个系统用什么 Agent 组合、什么协作模式、数据如何在 Agent 间流转 产品经理视角:把模糊的业务需求翻译成 Agent 能理解的精确指令 AI 训练师视角:通过观察 Agent 的输出,调整 Prompt、工具配置、奖励信号,让系统越来越准确
现在就该学的技能
基础层:理解 Agent 工作原理
Prompt Engineering 进阶:学会给 Agent 写清晰的角色描述(Role)、目标(Goal)、背景(Context)和约束(Constraints)。「你是一个后端工程师」的 Prompt 和「你是一个专注 Python 性能优化的后端工程师,不修改任何 API 接口定义,每次修改都必须附上性能测试数据」的 Prompt,效果天壤之别。 理解 RAG:检索增强生成(Retrieval-Augmented Generation)是给 Agent 提供长期记忆的核心技术,理解向量嵌入、相似度检索、上下文注入的工作原理。
工具层:掌握主流框架3. LangGraph / LangChain:掌握有状态工作流的构建方法,学会定义 State、Node、Edge,理解 checkpointing(状态快照)机制4. MCP 开发:学会开发自己的 MCP Server,把公司内部工具(内部 API、数据库、文档系统)接入 AI 生态,这是当前最高 ROI 的 AI 工程技能之一
工程层:确保系统可靠5. 可观测性工具:LangSmith、Langfuse、Phoenix(Arize)等 Agent 追踪和调试工具——Multi-Agent 系统出了问题很难靠 print 调试,需要专业的 Trace 工具来追踪每个 Agent 的输入输出和调用链6. 评估框架设计:如何自动化评测 Multi-Agent 系统的输出质量?这是区分「Demo 能跑」和「生产可用」的关键
行业真实数据
九、安全与治理
随着 Agent 获得越来越多的工具权限(读写文件、执行代码、访问网络、发送邮件),安全问题变得前所未有地重要。2025 年已经出现了多起因 Agent 权限失控导致的数据泄露和意外操作事故,迫使业界重新审视 Agent 的安全边界。
主要风险与防御方案
治理最佳实践
预算控制层面:
为每个 Agent 任务设置费用上限(超出自动停止并通知用户) 区分「低成本工具」(文本处理)和「高成本工具」(大模型 API 调用),后者需要额外授权 建立 Agent 费用的实时监控仪表盘,异常消耗立即告警
操作安全层面:
高风险操作(删除文件、发送邮件、执行 SQL 写操作、调用付费 API)设置人工审批门槛 实现「沙箱先行」:Agent 在沙箱环境验证方案可行后,再在生产环境执行 为所有 Agent 操作提供回滚机制,尤其是文件修改和数据库操作
审计与合规层面:
完整记录执行链追踪(Trace),包括每个 Agent 的输入、输出、使用的工具、消耗的 Token 出问题能快速定位:哪个 Agent 在哪一步做了什么 定期审查 Agent 权限配置,及时清理不再需要的工具授权(同等 API Key 的管理规范)
组织流程层面:
建立「Agent 上线评审」流程,新的 Agent 系统在开发测试环境充分验证后才能在生产部署 明确 Agent 操作的「责任人」:当 Agent 做出错误决策时,谁来负责 针对业务关键场景(财务处理、合同生成、用户数据操作)制定专门的 Agent 使用规范
十、当前挑战与未来展望
尚未解决的核心挑战
| 协调复杂性 | ||
| 错误传播 | ||
| 上下文管理 | ||
| 成本控制 | ||
| 可观测性 | ||
| 结果验证 | ||
| 上下文一致性 |
技术演进路线(2026-2028 年)
近期(0-12 个月):
Agent 市场/商店:类似 App Store,开发者上传专用 Agent,企业按需订阅使用 「公司级 Agent」权限模型:细粒度控制谁能调哪个工具、读哪块数据,与企业 SSO/IAM 深度集成 MCP/A2A 标准化普及:不同厂商的 Agent 能互操作,初步形成「Agent 互联网」
中期(12-24 个月):
端侧 Agent 普及:轻量模型+本地推理,Agent 像 iOS 快捷指令一样出现在每个人的手机里 Agent-Native SaaS:工具(Notion、Figma、Linear)直接内嵌可编排的 Agent 工作流,而不只是「AI 生成建议」 自进化系统:Agent 通过强化学习持续优化自己的工具调用策略,系统越用越「聪明」
远期(24+ 个月):
全自动软件工厂:给出需求文档,24 小时内输出经过测试的可部署代码,全程无人工干预 AI-to-AI 经济:Agent 之间相互付费服务(用 API Credit 或 Token 计价),形成自主的 AI 服务市场 认知外包常态化:企业把标准化的脑力工作(代码审查、报告生成、数据分析)全部外包给 Agent 集群,人类专注战略判断
开发者的行动建议
现在是布局 Multi-Agent 技能最好的时机——既足够早(竞争还不激烈),又足够晚(工具链已经成熟可用):
立刻动手:选一个 CrewAI 或 LangGraph 教程,在这周内跑起第一个多 Agent 系统 找一个痛点场景:在你的工作中找一个重复的、费时的任务,试着用 Agent 自动化它 开发一个 MCP Server:把你最常用的内部工具封装成 MCP Server,这是当前性价比最高的 AI 工程技能投资 关注可观测性:从一开始就接入 LangSmith 或 Langfuse,养成追踪 Agent 执行链的习惯 保持架构视野:不要只会用框架,要理解背后的设计模式(Orchestrator-Worker、Pipeline、Event-Driven),这才是跨框架的持久竞争力
如果 2023 年是大模型元年,2024 年是 Agent 元年,那么 2026 年就是 Multi-Agent 的工业革命元年 —— AI 从「个人助手」进化为「AI 研发团队」,程序员从「写代码的人」变成了「指挥 AI 军团的人」。
历史上每一次工具革命都重新定义了「专家」的标准:蒸汽机时代,懂如何驾驭机器的人成为专家;互联网时代,懂如何构建数字产品的人成为专家;Multi-Agent 时代,懂如何指挥和治理 AI 团队的人,将是下一个时代的技术专家。
