 夜雨聆风
夜雨聆风nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
这是「Nano-vLLM 源码解读」第 2 讲,承接 L1 的全景导论。这一讲只盯一个类——engine/sequence.py 里的 Sequence。它是 nano-vllm 里被传得最频繁的对象,也是理解后续 KV Cache、调度、抢占等所有章节的前提。
读完这一讲,你能:
• 说出 Sequence在系统里同时承担的三重身份• 解释 num_tokens/num_cached_tokens/num_scheduled_tokens之间的核心不变式• 画出包含 WAITING → RUNNING → FINISHED主线和抢占回退的完整状态机• 跟着一条具体请求把 Sequence 的字段变化逐步追完
1. Sequence 的三重身份
Sequence 本身只是一个普通的 Python 类,但系统里有三个完全不同的模块都会拿到同一个 Sequence 对象,每个模块只关心其中一部分字段。所以同一个对象,在不同模块眼里其实是在扮演不同的角色。这就是所谓"三重身份"。
seq_idtoken_ids, num_prompt_tokens, temperature 等采样参数 | ||
statusnum_scheduled_tokens, is_prefill | ||
block_tablenum_cached_tokens |
把这三个身份拆开看,很多乍一看"奇怪"的设计就能讲清楚了。
举个例子:num_cached_tokens 为什么不一定等于 num_tokens?
• num_tokens服务的是"用户请求载体"身份——这条序列目前一共有多少个 token(prompt + 已生成)。• num_cached_tokens服务的是"KV 块持有者"身份——在这些 token 里,已经有多少个的 KV 被写进显存里的 Cache 块了。
两者描述的是同一条序列的不同侧面:前者是"逻辑上序列有多长",后者是"物理上 KV Cache 算到哪一步了"。它们本来就不必相等,也不该混为一谈。
2. 字段一览
按身份分组:
classSequence: block_size = 256# 类变量,由 LLMEngine 启动时根据 Config 改写 counter = count() # 自增 seq_id 来源# —— 用户请求载体 —— seq_id: int# 全局唯一编号 token_ids: list[int] # 完整的 token 序列(prompt + 已生成) last_token: int# token_ids[-1] 的缓存,decode 路径会高频访问 num_prompt_tokens: int# 原始 prompt 长度,永不变 temperature: float# 来自 SamplingParams max_tokens: int ignore_eos: bool# —— 调度最小单位 —— status: SequenceStatus # WAITING / RUNNING / FINISHED num_scheduled_tokens: int# 当前 step 计划计算的 token 数;非 step 期间 = 0 is_prefill: bool# 当前是否在 prefill 阶段# —— KV 块持有者 —— block_table: list[int] # 物理 KV 块号列表,长度 = ceil(num_tokens / block_size) num_cached_tokens: int# 已写入 KV Cache 的 token 数 num_tokens: int# token_ids 的长度,便于 O(1) 读取外加几个派生量:
@propertydefnum_blocks(self): # 当前需要多少物理块return (self.num_tokens + self.block_size - 1) // self.block_size@propertydeflast_block_num_tokens(self): # 最后一块里实际用了多少 slotreturnself.num_tokens - (self.num_blocks - 1) * self.block_size@propertydefnum_completion_tokens(self): # 已经生成的(非 prompt)token 数returnself.num_tokens - self.num_prompt_tokensdefblock(self, i): # 取第 i 个物理块对应的 token 列表(用于 hashing)returnself.token_ids[i * self.block_size : (i + 1) * self.block_size]block(i) 是 BlockManager 计算 prefix-cache hash 时调的关键接口——把"逻辑 token 序列"切成"物理块大小的窗口"。这里只需要记一个直觉:BlockManager 会给每个写满的物理块算一个 hash,目的是让后续请求直接复用前缀已经算好的 KV,跳过这部分的 prefill。具体怎么链式 hash、怎么防碰撞、怎么挂回收,留到 L4 展开。
聚焦 num_scheduled_tokens
三个 num_* 字段里,num_scheduled_tokens 最容易被忽略,却是把整个引擎"步进"起来的那个字段。它的含义是:这一个 step,调度器决定要为这条序列计算多少个 token。
它的生命周期被严格夹在一个 step 内部:
Scheduler.schedule() → 写入 num_scheduled_tokensModelRunner.run() → 按这个值做 forward + 写 KVScheduler.postprocess()→ 累加到 num_cached_tokens,再清回 0非 step 期间恒等于 0。这就是为什么下一节会把"它是瞬态字段"放在第一条不变式:所有读它的代码都隐含假设"现在正处于一个 step 内"。
它在不同场景下的取值,对应了引擎里几条不同的执行路径:
num_scheduled_tokens | |
1(每步只解一个新 token) | |
num_tokens - num_cached_tokens | |
0 |
下游谁会读它:
• BlockManager:用 num_cached_tokens + num_scheduled_tokens算出本步要写到哪几个 KV 块、哪些 slot。• ModelRunner:把它当作每条序列的 seqlen_q,告诉 FlashAttention 本步 query 长度。• Scheduler 自己:判断 num_cached_tokens + num_scheduled_tokens == num_tokens是否成立,来决定本步是不是把 prefill 一次性吃完,可以挪到 RUNNING 队列。• 吞吐统计:把 batch 里所有序列的这个值加起来,作为本 step 处理的 token 总量。
一句话:num_tokens 和 num_cached_tokens 描述的是"序列到目前为止长什么样"(持久状态),而 num_scheduled_tokens 描述的是"这一步调度器要做多少活"(瞬态指令)。理解这个区别,下一节的不变式就只是这个区别的形式化表达。
3. 字段不变式
这是 L2 最核心的一节。三个数 num_tokens、num_cached_tokens、num_scheduled_tokens 之间的关系,决定了调度器和 KV 写入的所有判断逻辑。把它们的关系理清楚,后面 4 讲都会顺很多。
第一条:num_scheduled_tokens 是瞬态字段。 只有在一个 step 的"已 schedule、还没 postprocess"窗口里才非零,其它时间恒等于 0。
第二条:num_cached_tokens ≤ num_tokens,永远成立。 含义:KV Cache 里写入的 token 数不可能超过逻辑序列长度。
第三条:随 step 进展的语义切换。
围绕这套不变式,scheduler 在一个 step 的开头和结尾各埋了一个判断点。
第一个判断在 schedule(),决定"本步之后还要不要留在 WAITING":
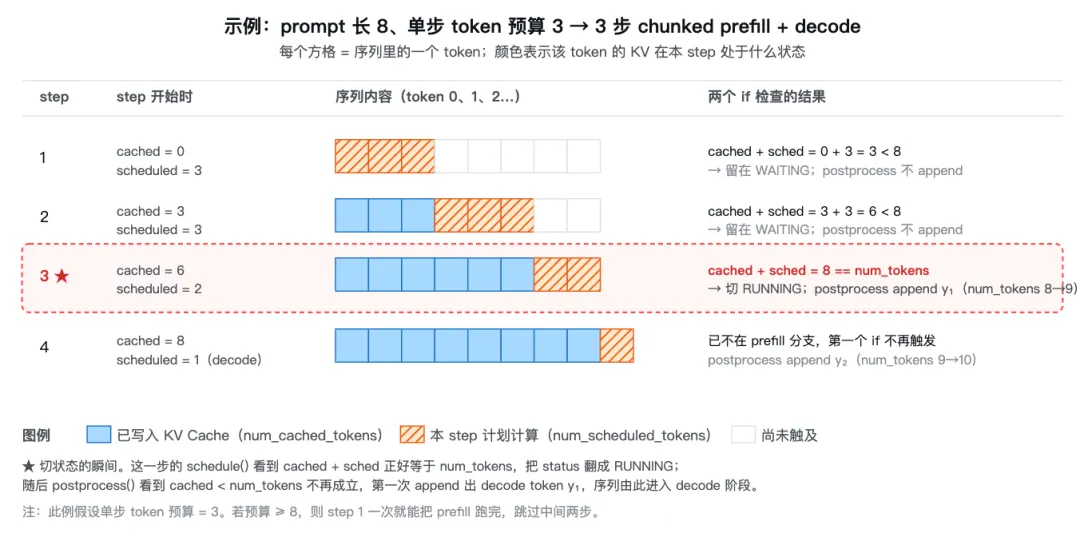
if seq.num_cached_tokens + seq.num_scheduled_tokens == seq.num_tokens: seq.status = SequenceStatus.RUNNING # 切到 decode 队列self.waiting.popleft()self.running.append(seq)num_cached + num_scheduled == num_tokens 这个等式怎么读?
• num_cached_tokens:进入本 step 之前,已经写入 KV Cache 的 token 数。• num_scheduled_tokens:本 step 打算计算 KV 的 token 数。• 两者相加 = 本 step 跑完后 KV Cache 里会有多少 token 的 KV。 • prefill 阶段 num_tokens就是 prompt 长度(还没 append 过任何 decode token)。
所以这个等式的物理含义是:"本步刚好把 prompt 剩下的部分全部 prefill 掉"。如果成立,说明这是 prefill 的最后一步,可以把 status 翻成 RUNNING,下一步开始 decode;如果不成立(小于),说明这是 chunked prefill 的中间步,本步只啃了一块,后面还要继续。
第二个判断在 postprocess(),决定"这一步要不要 append 一个新生成的 token":
if is_prefill and seq.num_cached_tokens < seq.num_tokens:continue# 还在 chunked prefill 中,本步不 appendseq.append_token(token_id)注意此时 num_cached_tokens 已经在前一行加上了 num_scheduled_tokens(也就是上面等式的左边)。条件 num_cached < num_tokens 等价于"上面那个等式不成立",意思是:prompt 还没 prefill 完,本步算出的 logits 不该当作"用户的下一个 token"接到序列尾巴上——否则就会在 prompt 还没读完时凭空冒出一个生成 token,把序列搞乱。等到最后一步 chunk 跑完,等式成立,这个 if 不再 continue,第一个 decode token 才被正式 append 进去。
下面这张图把上面这套逻辑跑了一遍:一条 prompt 长度 8、单步预算 3 的序列,要经过 3 步 chunked prefill 才会触发那个等式:
第四条:block_table 长度 = num_blocks,仅在序列被 deallocate 时清空。 preempt 也会清空(因为内部就是 deallocate)。
4. 状态机
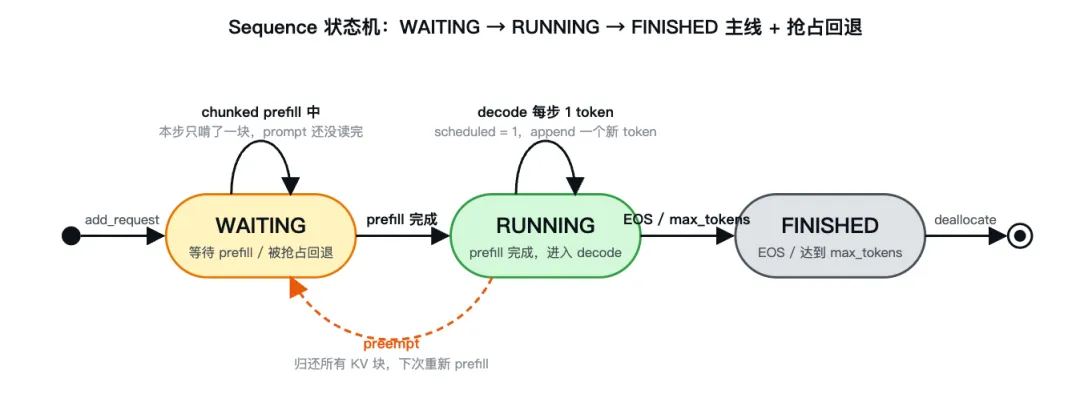
图里把第 3 节那条等式翻译成了边的触发条件:cached + scheduled == num_tokens 成立时,序列从 WAITING 跨到 RUNNING;不成立时(小于)就停在 WAITING 自循环里继续 chunked prefill。橙色虚线箭头是抢占回退——RUNNING 的序列被踢回 WAITING,KV 块全部归还,下一轮重新走 prefill 流程。
完整的合法转换列在下表(包括停留在同一状态的两类自循环):
[*] → WAITING | LLMEngine.add_request | seq = Sequence(prompt, sp); scheduler.add(seq) |
WAITING → WAITING | Scheduler.schedule | num_cached + num_scheduled < num_tokens 时不切状态 |
WAITING → RUNNING | Scheduler.schedule | seq.status = RUNNING; waiting.popleft(); running.append(seq) |
RUNNING → RUNNING | Scheduler.schedule | seq.num_scheduled_tokens = 1; seq.is_prefill = False |
RUNNING → WAITING | Scheduler.preempt | seq.status = WAITING; block_manager.deallocate(seq); waiting.appendleft(seq) |
RUNNING → FINISHED | Scheduler.postprocess | seq.status = FINISHED; block_manager.deallocate(seq); running.remove(seq) |
注意两件事:
• 抢占回退是 appendleft,不是append。 被抢占的序列下一轮优先恢复,避免长尾。• 抢占等同于全 deallocate 后重做 prefill。 重做的代价不小——但 prefix cache 多半能救一部分(L5 详谈)。
5. 一条请求的字段时序
具体跑一条:prompt = [1, 2, 3],block_size = 4,max_tokens = 3,假设 EOS = 2 且 ignore_eos = False。
add_request | [] | ||||||
schedule | [7] | ||||||
run | [7] | ||||||
postprocess | [7] | ||||||
schedule | [7] | ||||||
run | [7] | ||||||
postprocess | [7] | ||||||
schedule | [7,9] | ||||||
run | [7,9] | ||||||
postprocess | [] |
几个值得停一下的点:
• t1 步长 3 而不是 1。 prefill 是 chunked-only-on-head 的,能一口吃就一口吃;和 decode 的固定 1 token 形成强烈对比。 • block #7 的 hash 在 t2.p 才出现。 因为 t1 结束时 block 还没满(只有 3 个 token),等 t2 把 token 42 写进去后块满了, hash_blocks才会真正计算并注册到hash_to_block_id,给后续 prefix cache 复用。• t3.s 的"5%4=1"判断。 BlockManager.may_append用这个简单条件判断"刚好溢出一格、需要新块",详见 L4。• deallocate 把 block_table清空,num_cached_tokens归 0。 但token_ids保留,因为用户还要拿来 decode 输出。
6. 下一讲
到这一讲为止,你已经看完了 nano-vllm 里"用户请求"和"调度对象"这两层抽象。接下来进入这门课最核心的部分——KV Cache 与内存管理。
下一讲:PagedAttention 设计动机与块化布局。我们会回答这些问题:
• 为什么 vLLM 系列要把 KV Cache 切成固定大小的块,而不是按序列连续分配? • 物理块号、 block_table、token 在 cache 里的 slot 这三层映射到底怎么对上?• prepare_prefill里那串cu_seqlens_q、slot_mapping、block_tables元数据各自从哪儿来、给谁用?
带着 L2 这一讲对 block_table 和 num_cached_tokens 的认识进入 L3,会把 PagedAttention 的设计动机看得更深。
