 夜雨聆风
夜雨聆风
今天的大语言模型很强,但它们有一个根本问题:它们几乎不会在部署之后真正学习。
它们可以对话,可以检索,可以调用工具,可以阅读长文档,也可以根据上下文临时调整回答方式。但这些变化大多停留在外部系统里,并没有真正写进模型自己的大脑。
换句话说,很多 AI 看起来在学习,其实只是在查资料。
这正是 a16z 文章《Why We Need Continual Learning》提出的核心问题:如果模型不能在部署之后持续压缩经验、更新能力,那么它就会像电影《记忆碎片》里的主角一样,永远困在一个永恒的当下.

一、今天的 AI,像一个失去长期记忆的人
在诺兰的电影《记忆碎片》中,主角莱昂纳多因为无法形成新的长期记忆,只能依靠照片、纸条、纹身来维持行动。

这些外部记录让他还能完成任务,但他无法真正成长。
今天的大语言模型也有类似困境。
模型在预训练阶段吸收了海量文本,形成了强大的基础能力。但一旦部署上线,它的核心参数基本被冻结。无论它和用户聊了多少次,无论它完成了多少任务,模型本体通常并不会因此变得更聪明。
我们现在常用的 RAG、长上下文、聊天记录、系统提示词,本质上都是外部辅助。
它们像便利贴,也像文件夹。
它们可以帮模型临时找到信息,却无法保证模型真正理解、吸收并形成新的能力。
这就是当前 AI 的记忆碎片问题:它能调用过去,却不能真正消化过去。
二、文件柜再大,也不等于智能
很多人会以为,只要给模型接上足够大的知识库,它就拥有了记忆。
这是一种误解。
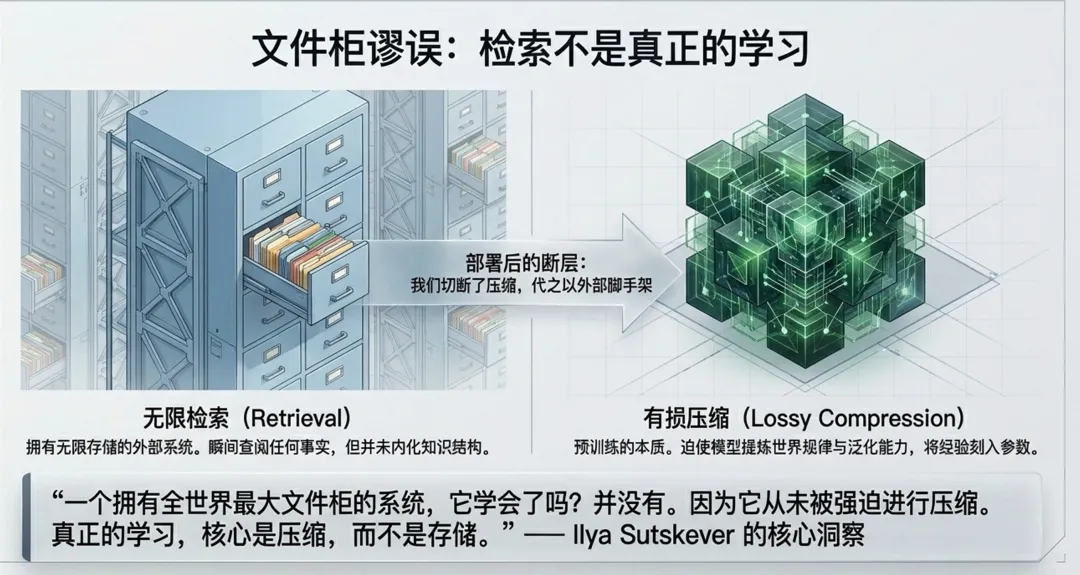
一个无限大的文件柜,可以保存所有事实,也可以瞬间检索。但它仍然只是文件柜,不是智能体。
真正的学习,不是把信息存起来,而是把信息压缩成结构。
大语言模型之所以强大,不是因为它机械记住了互联网,而是因为它在训练过程中被迫把海量数据压缩进有限参数里。这个过程会迫使模型发现规律、提取模式、形成泛化能力。
这才是学习。
RAG 可以告诉模型某个事实在哪里。 长上下文可以让模型临时看到更多内容。 但持续学习要解决的是另一个问题:模型能不能把新经验真正内化为自己的能力?
a16z 的文章把这个问题称为持续学习的核心:真实学习需要压缩,而不仅是检索。
三、为什么长上下文不能解决一切?
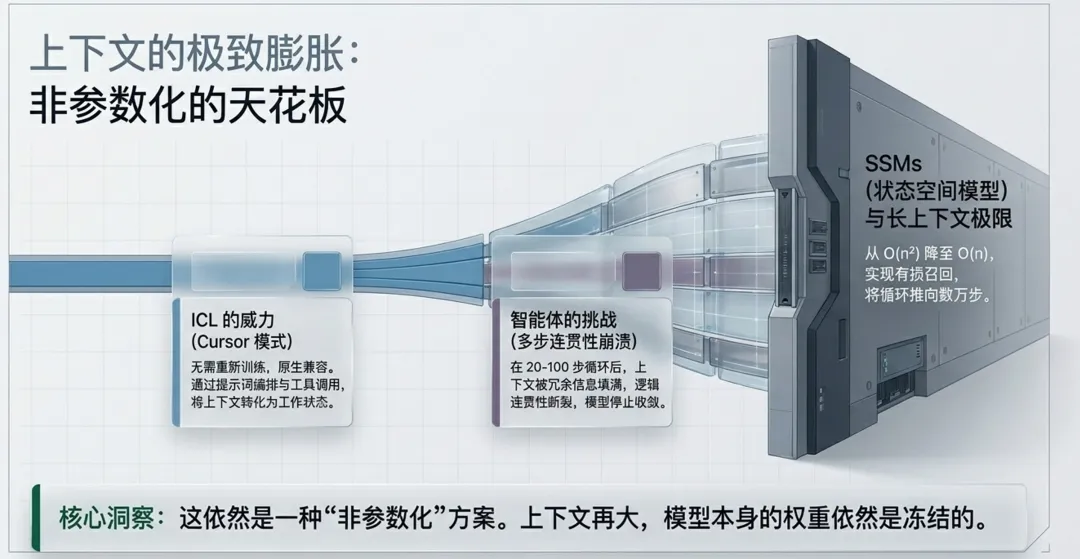
现在行业有一种倾向:既然模型记不住,那就把上下文窗口做得越来越长。
这当然有价值。
长上下文能让模型处理更长的文档,维持更复杂的任务状态,也能支撑更长时间的 Agent 工作流。a16z 文章中也承认,基于上下文的方案非常有效,而且还会继续发展。
但长上下文不是终点。
原因有两个。
第一,上下文是临时工作台,不是大脑。
把一堆资料塞进上下文,就像考试时允许开卷。开卷考试可以帮你解决很多问题,但它不代表你真正掌握了知识。
第二,很多知识根本无法被语言完整描述。
比如医生看影像时判断肿瘤的微妙纹理,语音专家识别一个人的独特节奏,程序员判断一套系统架构是否稳定,这些经验很多都不是几句话能表达清楚的。
它们更像一种内化后的判断力。
这种能力很难只靠 Prompt 传进去,它必须存在于模型的隐空间和参数表征中。
所以,持续学习真正要解决的不是记忆容量问题,而是能力沉淀问题。
四、AI 的学习方式,可以分成三条路线
当前围绕持续学习,大致有三类技术路线。
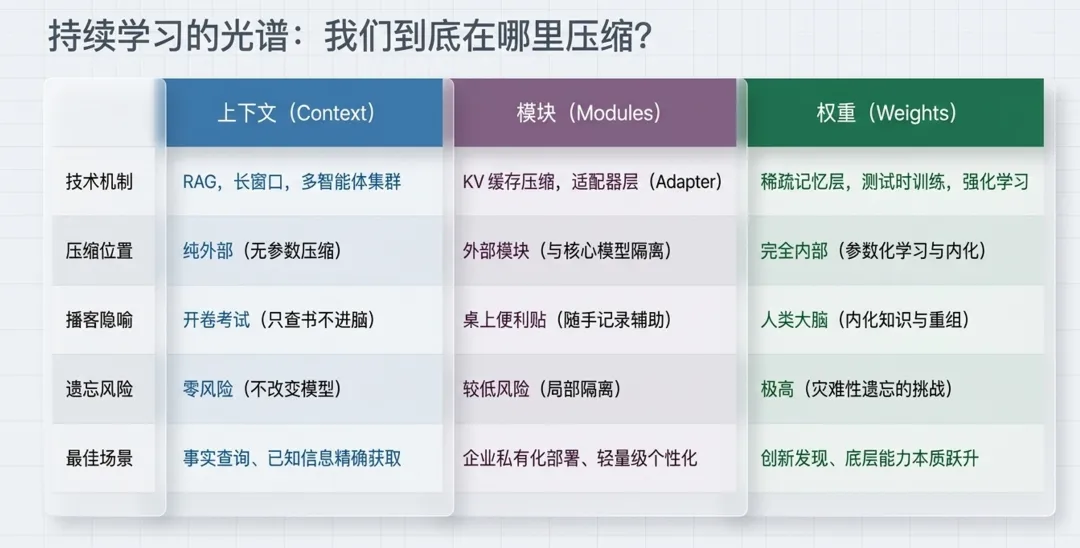
1. 上下文路线:开卷考试
这是今天最成熟的路线。
包括 RAG、长上下文、工具调用、多智能体协作、上下文压缩等。
它的优点是安全、可控、工程上容易落地。模型权重不动,系统只需要管理好外部信息,把正确内容在正确时间送进上下文。
适合解决事实查询、文档问答、流程自动化、企业知识库等问题。
但它的上限也很清楚:模型没有真正改变,只是在更聪明地使用外部材料。
2. 模块路线:外挂记忆与技能包
第二条路线,是在模型外部增加一些可插拔模块。
比如 Adapter、压缩后的 KV Cache、外部记忆模块、领域专用知识模块等。
它比单纯 RAG 更进一步,因为它不只是查资料,而是在某种程度上把知识压缩成可复用结构。
它的价值在于:不必直接改动大模型主干权重,却能让模型在特定领域变得更专业。
这对于企业私有知识、垂直行业模型、个人化助手来说,很有现实意义。
它像是在大脑旁边放了一个专业辅助脑。
3. 权重更新路线:真正改变大脑
第三条路线最激进,也最接近真正意义上的持续学习。
它希望模型在部署之后,仍然能够通过新经验更新自己的参数。
这包括测试时训练、元学习、强化学习反馈、自蒸馏、稀疏参数更新等方向。a16z 文章将这类方案视为最深层、也最难部署的持续学习路径。
如果这条路走通,模型就不只是会查资料,而是会从每一次任务、每一次失败、每一次反馈中积累经验。
这才更接近人类的学习方式。
一个刚毕业的医生,不是靠查资料成为专家的,而是在长期诊断、反馈、纠错中形成判断力。
一个程序员也不是背完文档就会架构设计,而是在真实项目中不断踩坑、修正、抽象,最后形成工程直觉。
AI 也一样。
没有持续学习,就没有经验复利。
五、为什么直接更新模型参数很危险?
问题是,让模型部署后继续更新参数,并不是简单打开一个开关。
它会带来一系列严重风险。
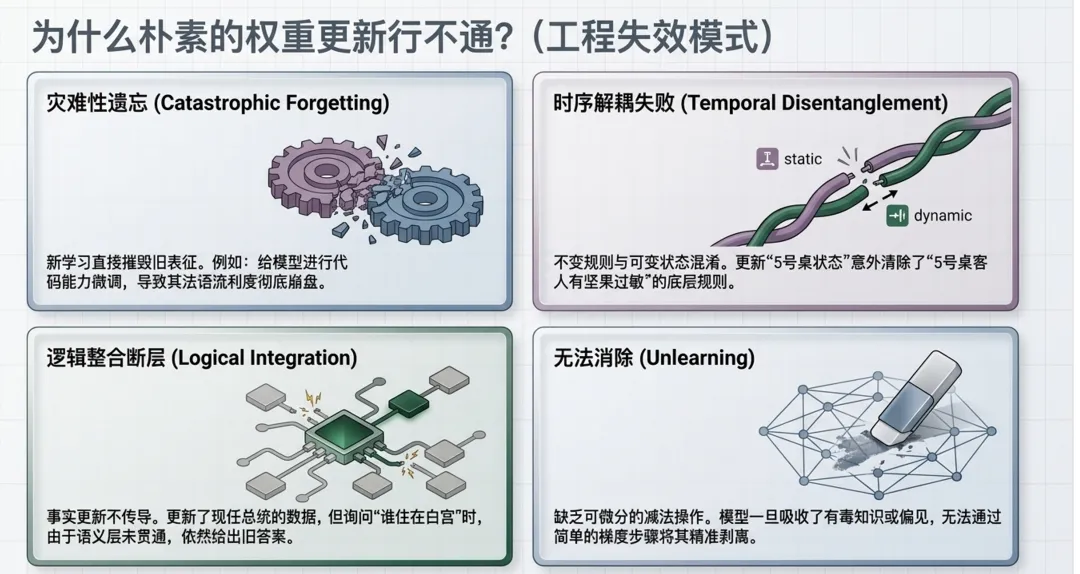
1. 灾难性遗忘
模型学习新知识时,可能破坏旧能力。
这就像一个人学会了新规则,却忘掉了原来的基本常识。
对大模型来说,这尤其危险。因为它的知识不是整齐地存放在某个文件夹里,而是分布在海量参数中。
2. 稳定知识和变化事实混在一起
数学规律是稳定的。 现任总统、公司 CEO、产品价格是变化的。
但在模型权重中,这些信息可能被压缩在同一套参数结构里。
如果模型为了更新一个变化事实而调整参数,就可能误伤稳定能力。
这就是持续学习中的时序解耦问题。
3. 错误知识很难删除
外部知识库里有错,可以删除一条记录。
但如果错误知识已经写入模型权重,删除就非常困难。
目前的模型还没有真正可靠的手术刀式遗忘能力。
这意味着,一旦模型把错误、有害或被投毒的信息内化进去,后果可能是长期的。
4. 安全审计会变得困难
今天我们可以说:某个模型版本经过测试,可以上线。
但如果模型每天都在根据用户交互更新自己,那么它就不再是一个固定版本。
每个部署环境里的模型都可能逐渐进化成不同个体。
这会带来新的治理问题:
谁来审计? 如何回滚? 如何证明它没有被污染? 如果它做出错误决策,责任属于谁?
这也是持续学习最难的地方:它不仅是技术问题,也是安全、治理和责任问题。
六、真正的 AGI,可能不是一个固定模型
过去我们习惯把模型理解为一个文件。
下载一个模型,部署一个模型,调用一个模型。
但如果持续学习成为主流,未来的模型可能不再是一个固定文件,而是一个动态系统。
它至少包括三部分:
第一,基础能力。 第二,记忆机制。 第三,更新算法。
也就是说,未来的 AI 不只是一个会回答问题的模型,而是一个能够管理经验、筛选信号、抽象规律、更新自身的系统。
这才是从工具走向智能体的关键一步。
a16z 文章最后也指出,未来的路径很可能不是单点突破,而是分层系统:上下文学习负责短期适应,模块机制负责领域特化,而参数级学习则负责真正困难的问题,比如发现、创新、对抗性适应和隐性知识内化。
七、结语:AI 真正缺的不是记忆,而是成长
今天的 AI 已经很会检索,也很会表达。
但它仍然缺少一种更关键的能力:从经验中成长。
如果一个模型每次对话之后都回到原点,它就像一个能力很强但无法积累经验的人。它可以完成任务,却无法形成复利。
这就是持续学习的重要性。
AI 通往 AGI 的道路,可能并不只是更大的模型、更长的上下文、更强的工具调用。
更关键的问题是:
模型能不能把经历过的事情,压缩成自己的能力?
文件柜可以无限变大,但文件柜终究不是大脑。
真正的智能,不只是能找到答案,而是能在一次次经验中改变自己。

当 AI 走出永恒当下,开始拥有经验复利,它才可能从一个高效的信息处理系统,进化为真正意义上的智能体。
留给读者的一个问题
如果未来每一个 AI 都能在部署后持续学习,那么它们会不会逐渐变成不同的个体?
到那时,我们该如何定义一个 AI 的版本、边界与责任? 当模型不再固定,安全治理也必须重新开始。

