 夜雨聆风
夜雨聆风
一、开篇:你的评测,是手动跑还是自动化?
在前三期,我们讨论了测什么(指标体系)和怎么定义(指标理论)。但这一切的前提是:评测能够有序地、高效地跑起来。
然而,现实中大多数团队的评测场景是这样的:
上午 10:00:项目经理说「我们需要评测新版本的模型」
上午 10:30:一个工程师手动启动 Python 脚本
中午 12:00:脚本仍在运行,但没人知道进度
下午 2:00:脚本因为某个网络波动失败了,需要重跑
下午 6:00:才看到评测结果
晚上 8:00:发现某个样本的输出异常,怀疑是数据问题,再跑一遍
这不是评测,这是「手工作坊式的试验」。
真正的评测系统,需要 Pipeline——一个自动化的、可扩展的、可靠的评测执行引擎。
本期我们深入讨论如何从「手动脚本」升级到「自动化Pipeline」,包括三个核心部分:任务编排、资源管理、以及失败重试机制。这将是你从「一次性评测」升级到「持续化评测」的关键转折。
二、问题定义:为什么手动评测成本这么高
2.1 三种常见的「我的评测挂掉了」
我们观察了 50+ 个团队的评测实践,发现手动评测的问题有多严重:
❌ 现象1:评测中途失败,没有自动恢复
启动了一个 10 万条样本的评测
跑到 50% 时,某个 API 超时了
整个流程卡住,必须手动重启
损失:4 小时的计算资源 + 1 小时的人工排查
根本原因:没有重试机制,没有断点续传
❌ 现象2:资源分配不合理,导致效率低下
一个评测任务占用了所有 GPU
其他任务排队等待
没有优先级控制,也没有资源隔离
结果:某个紧急评测等了 8 小时
根本原因:没有任务队列,没有资源调度
❌ 现象3:样本分布不均匀,某个环节成为瓶颈
10 万条样本分配给 4 个 Worker
其中 3 个 Worker 快速完成,1 个却很慢
最终整个评测的速度由最慢的 Worker 决定
结果:总耗时 2 倍于最优情况
根本原因:没有动态负载均衡
2.2 根本原因:评测系统缺乏工业级设计
在软件工程中,Pipeline(流水线)是标准的解决方案:
Netflix 的 Spinnaker 管理持续部署
Airflow 调度数据处理任务
Kubernetes 编排容器化应用
但在 AI 评测领域:
❌ 大多数人用 Python 脚本 + Bash 命令手动运行
❌ 「反正就是跑一遍评测,不需要 Pipeline」
❌ 「出错了就重跑,反正只是计算时间」
这是致命的思维差异。
评测 Pipeline 本质上也是一个分布式系统——有任务分解、资源分配、故障恢复、进度监控。它同样需要工业级的设计。
2.3 禅云智量·Zenit 的核心观点
评测 Pipeline = 将评测任务转化为可自动执行、可扩展、可恢复的工作流。
这包括三个层次:
层级 | 核心问题 | 时间尺度 |
任务编排 | 如何将 10 万条样本拆分成 1000 个小任务?任务间的依赖关系是什么? | 秒级 ~ 分钟级 |
资源管理 | 如何分配 CPU / GPU / 内存,确保不浪费也不过载? | 分钟级 ~ 小时级 |
故障恢复 | 如果某个任务失败,如何自动重试?如何不重复计算已完成的部分? | 秒级响应 |
三、方案拆解:评测 Pipeline 的 3 大支柱
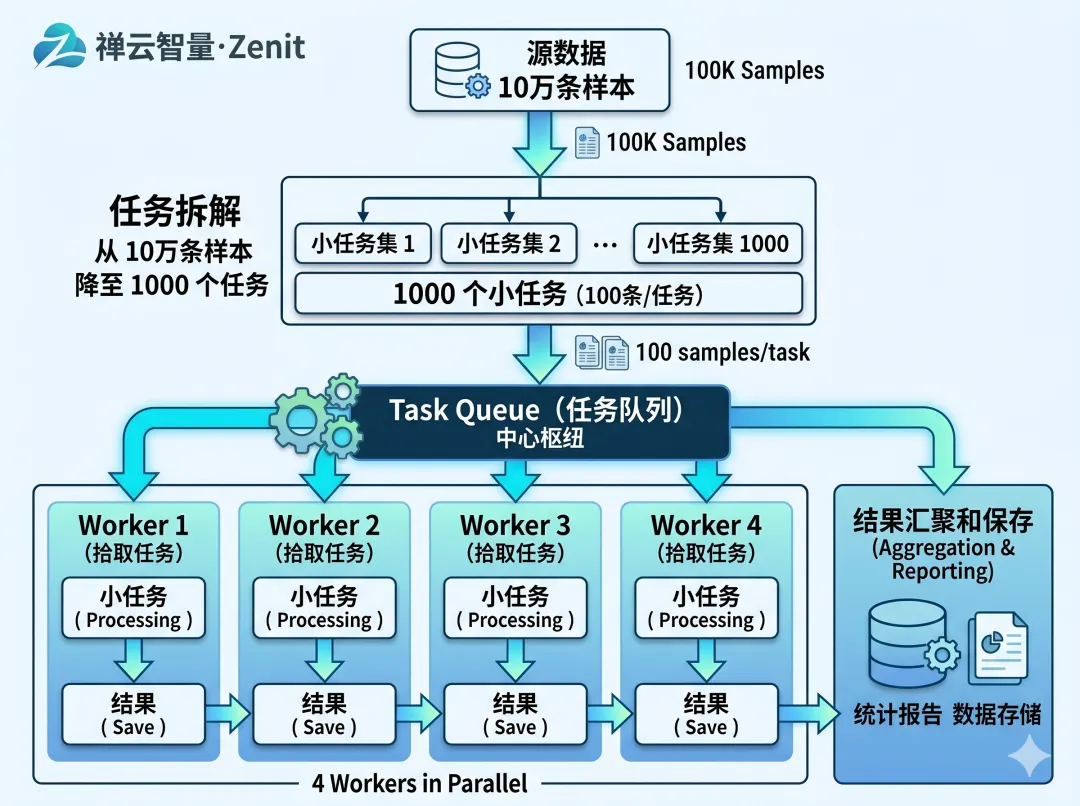
支柱一:任务编排——将 10 万变成 1000
评测的第一步是任务分解。不能一口气处理 10 万条样本,必须拆成可管理的小任务。
1.1 分解策略(三种常见方式)
【策略1:按样本数分片】
原始:10 万条样本 → 1 个大任务(容易失败)
优化:10 万条样本 → 1000 个任务(每个 100 条)
优点:简单,容易并行化
缺点:如果样本复杂度差异大,某些任务会很慢
【策略2:按样本特征分片】
将样本按类型分组:
• 短文本(1-10 字) → 50 个任务
• 长文本(1000+ 字) → 100 个任务
• 多轮对话 → 200 个任务
优点:任务复杂度均衡,整体耗时更优
缺点:需要预处理和特征提取
【策略3:按优先级动态分片】
核心样本优先评测:
• 第一阶段:1000 条关键样本(优先级高)
• 第二阶段:99000 条常规样本(优先级低)
优点:重要结果能快速出来,不用等所有样本完成
缺点:复杂度高,需要样本优先级标注
1.2 任务调度的技术实现
最简单的是基于队列的调度:
# 伪代码from queue import Queueimport threading# 1. 生产者:生成任务task_queue = Queue()for i in range(0, 100000, 100): # 每 100 条样本一个任务task = {'task_id': f'task_{i}','samples': samples[i:i+100],'priority': 'normal'}task_queue.put(task)# 2. 消费者:执行任务class Worker(threading.Thread):def run(self):while True:task = task_queue.get() # 从队列取任务try:result = evaluate_samples(task['samples'])save_result(task['task_id'], result)print(f"✓ {task['task_id']} completed")except Exception as e:print(f"✗ {task['task_id']} failed: {e}")# 失败重试逻辑(后面讲)task_queue.task_done()# 3. 启动多个 Workerfor i in range(4): # 4 个并行 Workerworker = Worker(daemon=True)worker.start()# 4. 等待所有任务完成task_queue.join()print("All tasks completed!")
这样做的好处是:
✅ 自动并行化:4 个 Worker 同时工作
✅ 任务隔离:某个 Worker 失败不影响其他
✅ 简单可靠:不需要复杂的分布式框架
支柱二:资源管理——不让 GPU 空闲,也不让它过载
有了任务队列,下一步是合理分配资源。
2.1 资源类型和约束
【CPU 资源】
• 样本预处理:需要 CPU
• 推荐:4-8 核,取决于样本复杂度
【GPU 资源】
• 模型推理:需要 GPU
• 约束:显存有限(如 24GB)
• 决策:batch_size 多大?并行多少个样本?
【内存资源】
• 模型加载:需要内存
• 缓冲区:存放中间结果
• 约束:不能超过机器总内存
【网络资源】
• API 调用的带宽和并发数限制
• 约束:不能超过 API 的 RPS(Request Per Second)
2.2 资源配置的最佳实践
# 伪代码:动态调整 batch_sizedef estimate_batch_size(model, gpu_memory=24): """根据 GPU 显存估计最大 batch_size""" # 1. 测量模型的显存占用 test_batch = 1 while True: try: dummy_input = torch.randn(test_batch, 512).to('cuda') output = model(dummy_input) torch.cuda.empty_cache() test_batch *= 2 except RuntimeError as e: # OOM test_batch //= 2 break # 2. 留出 20% 的buffer,避免峰值 OOM safe_batch = int(test_batch * 0.8) # 3. 根据吞吐量和延迟的平衡调整 # 更大的 batch_size → 更高的吞吐,但延迟也高 # 推荐:batch_size = min(safe_batch, 32) return min(safe_batch, 32)# 使用optimal_batch = estimate_batch_size(model)print(f"Optimal batch size: {optimal_batch}")
关键决策:
✅ 监控 GPU 利用率:目标 80-90%(不要 100%,容易 OOM)
✅ 动态调整并发度:如果 GPU 空闲,增加 Worker 数;如果过载,减少
✅ 预留缓冲:总是留出 10-20% 的资源给突发请求
支柱三:故障恢复——自动重试和断点续传
评测 Pipeline 最容易卡在的地方是网络波动或API 故障。
3.1 失败重试的 3 个策略
【策略1:立即重试】
if request_failed: retry_count = 0 while retry_count < 3: try: result = api_call() break except Exception: retry_count += 1 time.sleep(1) # 等待 1 秒再试
优点:简单,适合临时网络波动
缺点:如果 API 故障,立即重试可能导致雪崩
【策略2:指数退避重试】
retry_count = 0while retry_count < 5: try: result = api_call() break except Exception: wait_time = 2 ** retry_count # 1s, 2s, 4s, 8s, 16s print(f"Retry after {wait_time}s") time.sleep(wait_time) retry_count += 1
优点:避免雪崩,给 API 时间恢复
缺点:总等待时间长(最多 31 秒)
【策略3:断点续传】
checkpoint_file = 'eval_progress.json'completed_tasks = load_checkpoint(checkpoint_file)for task in all_tasks: if task['task_id'] in completed_tasks: continue # 跳过已完成的任务 try: result = evaluate(task) completed_tasks.add(task['task_id']) save_checkpoint(checkpoint_file, completed_tasks) except Exception: # 下次重启时会从这个 task 开始,不会重复计算 pass
优点:失败后可以继续,不浪费已做的工作
缺点:需要维护 checkpoint,加重磁盘 I/O
3.2 完整的故障恢复框架
# 伪代码:生产级的故障恢复class RobustEvaluationPipeline: def __init__(self, checkpoint_path='eval_progress.json'): self.checkpoint_path = checkpoint_path self.completed = self.load_checkpoint() def evaluate_with_retry(self, task): """带重试和日志的评测函数""" task_id = task['task_id'] # 检查是否已完成 if task_id in self.completed: return self.completed[task_id] # 重试逻辑 for attempt in range(5): try: result = self.evaluate(task) # 成功:保存进度 self.completed[task_id] = result self.save_checkpoint() return result except TemporaryError as e: # 临时错误:重试 wait_time = 2 ** attempt print(f"[{task_id}] Attempt {attempt+1} failed, retrying in {wait_time}s") time.sleep(wait_time) except PermanentError as e: # 永久错误:放弃 print(f"[{task_id}] Permanent error: {e}") self.completed[task_id] = {'error': str(e)} self.save_checkpoint() return None # 5 次都失败:记录失败 print(f"[{task_id}] Failed after 5 attempts") self.completed[task_id] = {'error': 'Max retries exceeded'} self.save_checkpoint() return None def load_checkpoint(self): """从磁盘恢复已完成的任务""" try: with open(self.checkpoint_path) as f: return json.load(f) except: return {} def save_checkpoint(self): """定期保存进度""" with open(self.checkpoint_path, 'w') as f: json.dump(self.completed, f)
这样做的好处是:
✅ 自动恢复:中断后可以从断点继续
✅ 智能重试:区分临时错误和永久错误
✅ 完整日志:每个失败都有记录
四、实践要点:如何落地一个真正的 Pipeline
4.1 五个关键决策
决策 | 选项 | 推荐 | 原因 |
并发度 | 4, 8, 16, 32 Worker | 根据 GPU 数量:每个 GPU 配 1-2 个 Worker | 避免资源竞争 |
Batch 大小 | 1, 8, 16, 32, 64 | 根据模型和显存:目标 80-90% GPU 利用率 | 平衡吞吐和延迟 |
任务粒度 | 100, 1000, 10000 样本/任务 | 100-1000 | 太小导致开销大,太大容易失败 |
重试次数 | 1, 3, 5, 10 次 | 3-5 次 | 超过 5 次通常是永久故障 |
Checkpoint 频率 | 每个任务、每 10 个任务、每小时 | 每个任务完成后 | 丢失的计算最少 |
4.2 实施流程(3 天内上线)
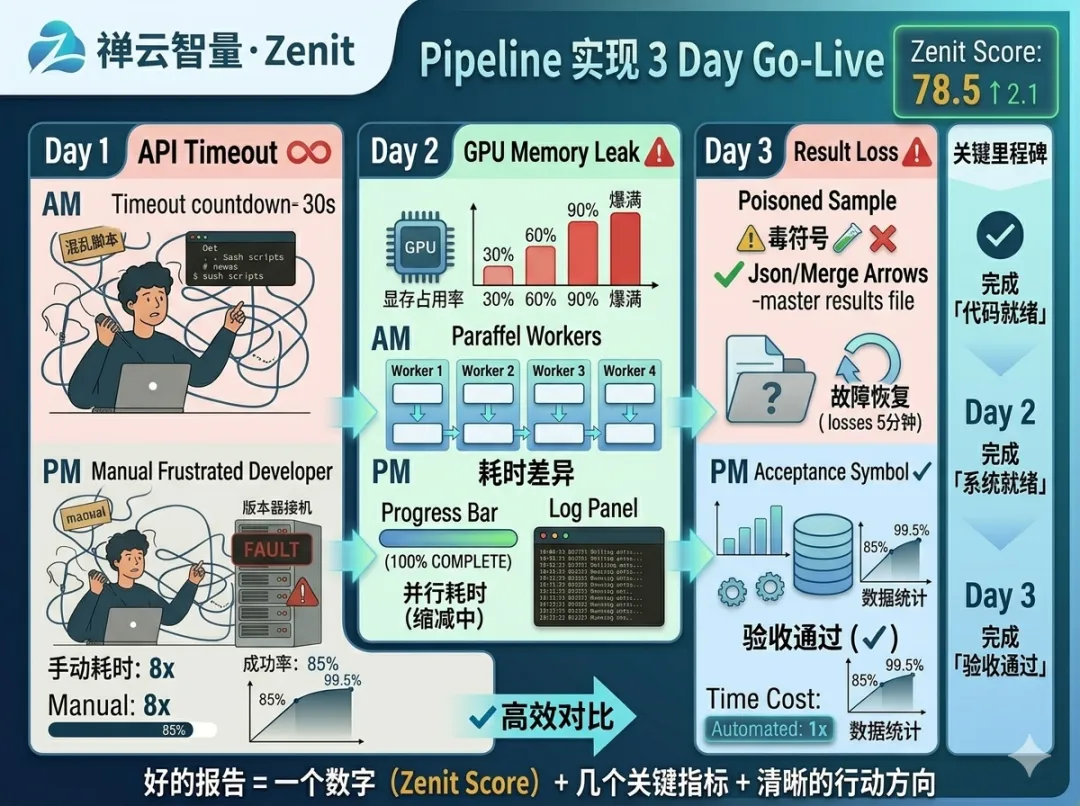
Day 1:设计和测试
上午:梳理现有的评测代码
• 哪些是「输入」(样本)?
• 哪些是「计算」(模型推理)?
• 哪些是「输出」(结果保存)?
下午:用单个 Worker 测试整个流程
• 确保代码能完整跑一遍
• 记录平均耗时(用于估算总时间)
Day 2:并行化和监控
上午:实现任务队列和多 Worker
• 启动 4 个 Worker,并行处理 1000 条样本
• 验证结果正确性
下午:添加进度监控和日志
• 每分钟输出进度(已完成 / 总数 / ETA)
• 每个失败都记录时间和原因
Day 3:故障恢复和验收
上午:实现 Checkpoint 和重试机制
• 故意 kill 一个 Worker,验证不会丢失工作
• 故意 block 一个 API 调用,验证自动重试
下午:全量测试
• 用 10 万条真实样本运行完整 Pipeline
• 验证最终结果的正确性
4.3 常见的坑和规避方法
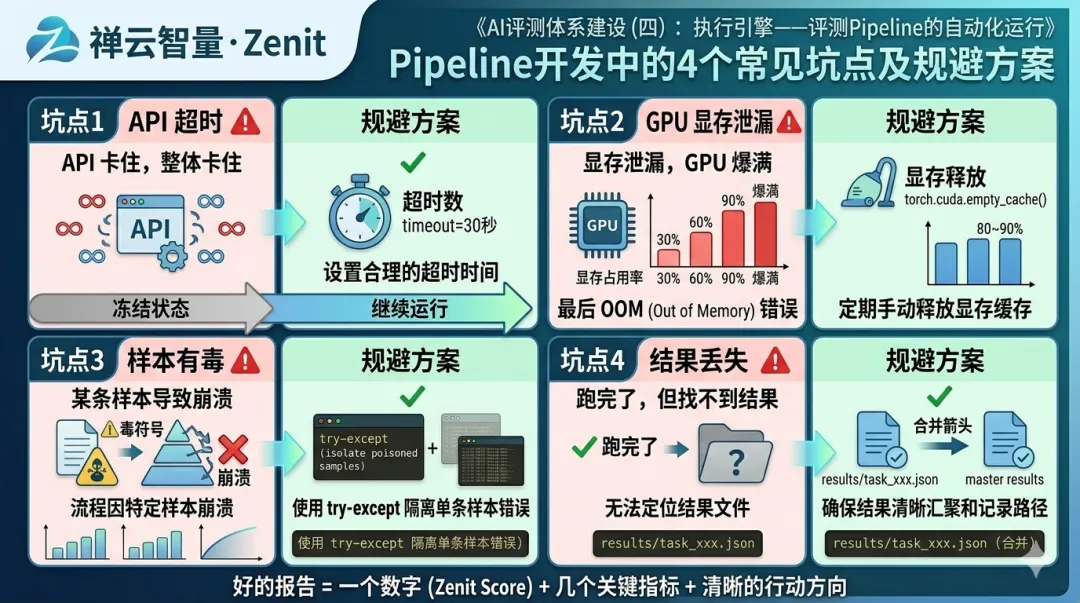
❌ 坑1:没有超时设置,API 卡住导致整个 Pipeline 卡住
✅ 规避:为每个 API 调用设置 timeout
response = requests.get(url, timeout=30) # 30 秒超时 if not response: raise TimeoutError("API response timeout")
❌ 坑2:显存泄漏,跑着跑着 GPU 内存爆满
✅ 规避:每个任务后手动释放
with torch.no_grad(): output = model(input) del output, input torch.cuda.empty_cache()
❌ 坑3:样本有毒,某个特定样本导致评测崩溃
✅ 规避:用 try-except 隔离样本级别的错误
for sample in batch: try: result = evaluate(sample) except Exception as e: result = {'error': str(e), 'sample_id': sample['id']}
❌ 坑4:结果保存有问题,跑完了但找不到结果
✅ 规避:每个任务保存到独立文件,最后合并
result_file = f'results/task_{task_id}.json' with open(result_file, 'w') as f: json.dump(result, f) # 最后:merge all result files
五、收尾
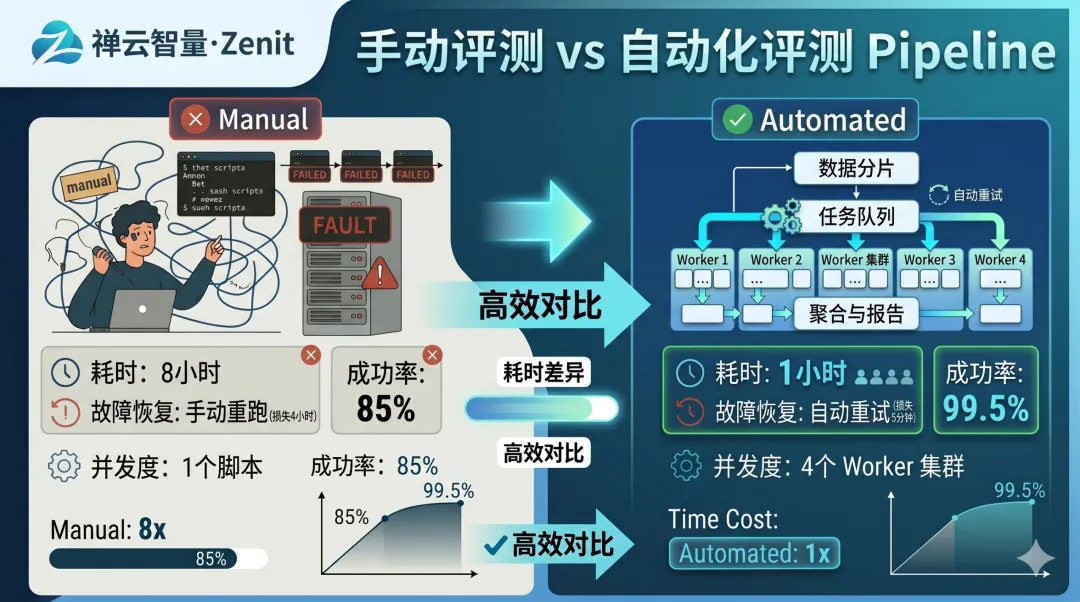
从手动脚本到自动化 Pipeline,你获得的不仅是速度的提升,更是可靠性和可扩展性的质变。
10 万条样本,从 8 小时手动跑,到 1 小时 Pipeline 自动完成。故障从「整个重跑」变成「续传 5 分钟」。这就是工业级评测系统应该有的样子。
下一步的关键是什么?当 Pipeline 跑起来后,你需要知道 Pipeline 每一刻在做什么——这正是第 5 期要讨论的评测观测系统。
不仅要能自动跑,还要能实时看到运行状态、及时发现问题。这才是真正的评测工程化。
