 夜雨聆风
夜雨聆风一个业务同事兴冲冲地跑来说:“我用 AI 半小时做了个内部查询页,能不能先发给客户试用?”
页面能打开,表格也能查,甚至还有导出按钮。
如果只看演示,它已经挺像一回事。
但我现在第一反应不会先夸它快,而是会问五个问题:
谁能访问这个页面?
查到的数据从哪里来?
有没有客户、订单、手机号、账号这类敏感信息?
上线前谁验收?
出了问题怎么关停、怎么回退、怎么查日志?
我的判断很直接:AI 编码的下半场,不是继续问它能不能写,而是问它写完能不能安全上线。
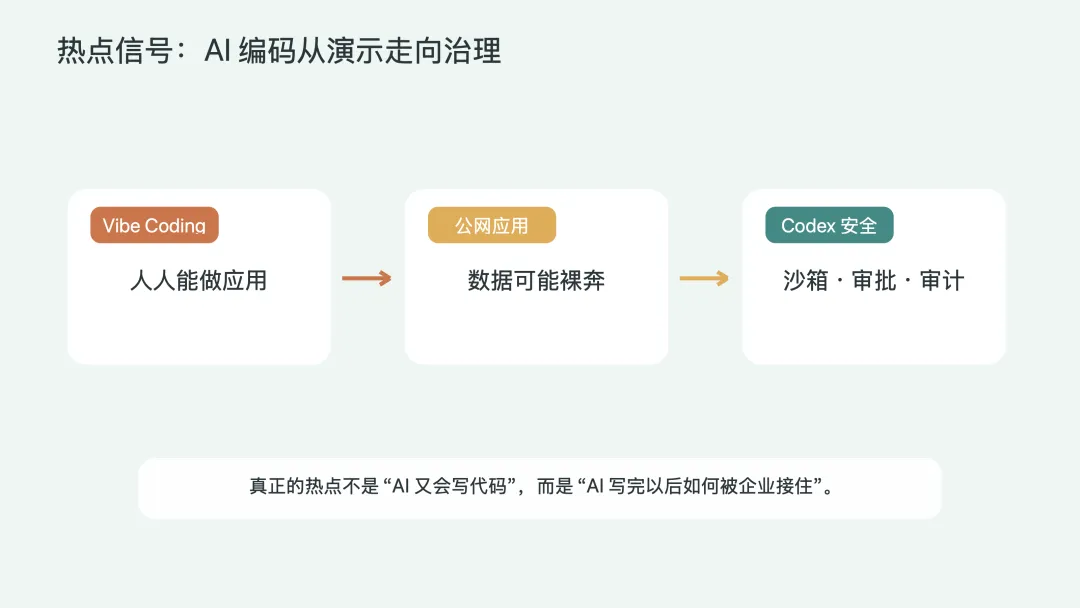
热点真正提醒了什么
最近几条新闻放在一起看,信号已经很清楚。
一边,OpenAI 公开讲 Codex 在内部如何安全运行:沙箱、审批、网络策略、日志、OpenTelemetry、合规审计。听起来不像热点词,但这正是 coding agent 能不能进真实仓库的关键。
另一边,WIRED 和 Axios 报道了大量 AI 编码工具生成的 Web 应用暴露在公网。有些应用缺少基本认证,甚至可能涉及医疗、金融、企业内部材料和客户对话记录。
这不是一句“用户配置不当”就能带过的问题。
真正值得技术负责人警惕的是:当 AI 让非工程人员也能快速做应用,企业内部会突然多出一批“看起来能用、实际上没人治理”的小系统。
这些小系统不一定有复杂 bug。
更麻烦的是,它们可能根本没有权限、没有审计、没有数据隔离、没有下线机制。
能生成不等于能上线。
这句话以前像常识,现在要重新写进企业 AI 试点的第一条。
真实业务系统,最怕“能跑就发”
我做过旅游线上预订,也做过教育招生录取保障,后来又接触交通行业软件和平台化重构。
真实业务系统有一个共同特点:它们从来不是页面能点开就结束。
旅游系统背后是订单、库存、渠道、支付、客服。
教育系统背后是时间窗口、并发压力、录取准确性和责任边界。
交通系统背后是车辆、地图、视频、实时链路、权限范围和运维保障。
这些系统一旦接入真实数据,就不再是“做得快不快”的问题,而是“出了事谁负责”的问题。
老板嘴上问的是:AI 能不能提高效率?
但他心里真正担心的是:花了钱以后,团队是不是更乱了?客户数据会不会出问题?系统上线后是不是没人兜底?
技术负责人怕的也不是 AI 抢工作。
真正怕的是:AI 写得太快,团队还没来得及建立边界,系统债务就已经翻倍。
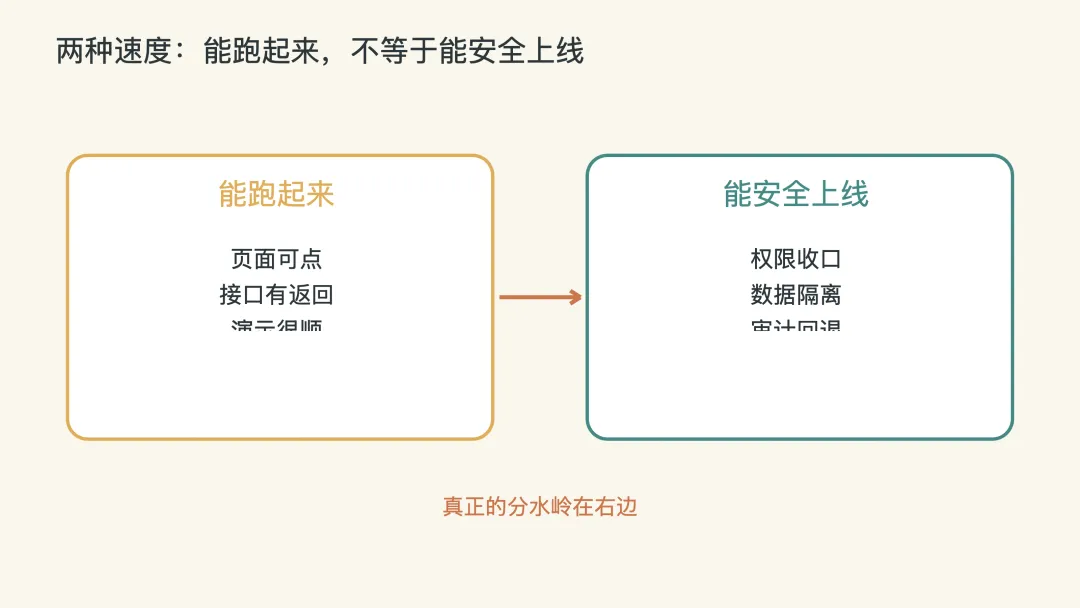
我现在更倾向于把 AI 编码分成两层看。
第一层是个人提效:查代码、补测试、写接口、整理文档。
第二层是组织能力:权限怎么管,数据怎么隔离,变更怎么审,失败怎么回退,结果怎么验收。
很多团队现在卡住,是因为只买了第一层,却以为自己已经拥有第二层。
这就是危险的地方。
上线门禁五问
我不会阻止团队用 AI。
相反,我认为技术团队必须尽快把 AI 用起来。但越是要用,越不能只靠热情。
我会先给每个 AI 生成应用补一张上线门禁表。
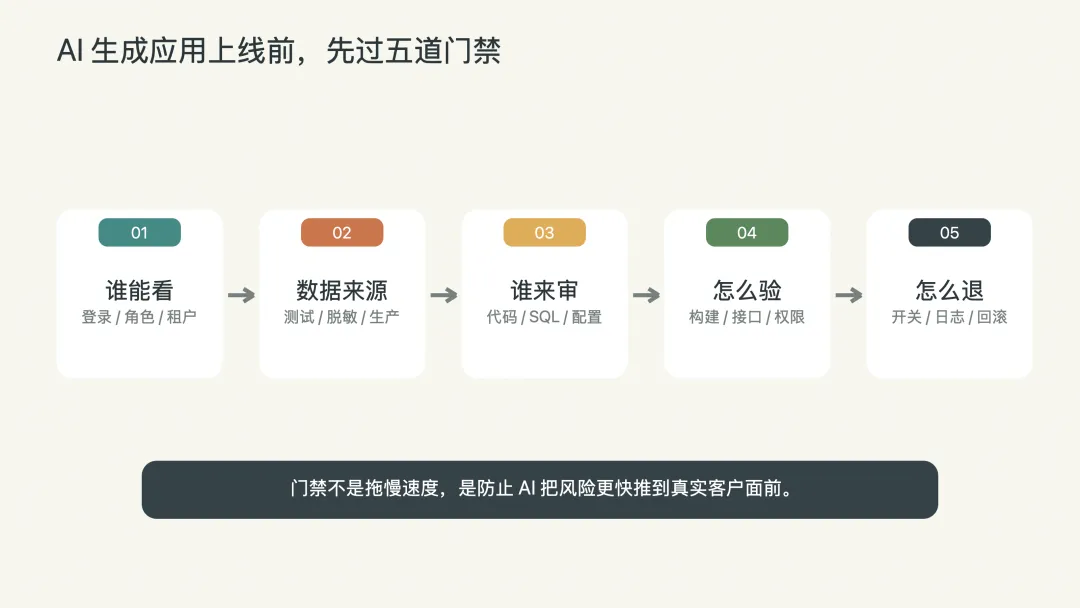
第一问:谁能看?页面有没有登录?有没有角色权限?有没有租户或部门范围?如果只是一个链接就能打开,那它就不能碰真实业务数据。
第二问:数据从哪来?是测试数据、脱敏数据,还是生产数据?如果接生产库,读的是哪张表,哪张表才是真源,查询是否会越权?
第三问:改动谁审?AI 生成的接口、SQL、权限策略、配置文件,不能因为“看起来简单”就绕过代码审查。
第四问:怎么验收?不是页面能打开就算完成。至少要有构建结果、关键接口返回、权限验证、异常场景、日志路径和截图证据。
第五问:怎么回退?出了问题能不能关开关?能不能撤配置?能不能停访问?能不能查到是谁在什么时间放出去的?
这五问不复杂,但足够把很多“裸奔”的 AI 小应用挡在上线前。
我踩过的坑是:很多系统出问题,不是因为技术点多难,而是因为上线前没人把责任链写清楚。
AI 只是让这个问题来得更快。

从个人提效到团队治理
AI 编码最容易产生一个错觉:一个人越会用 AI,团队就越快。
短期看确实如此。
一个有架构判断、懂业务边界、会验收的人,用 Codex、Claude Code 或其他 coding agent,效率会非常夸张。
但团队长期能力不是这样建立的。
如果只有一个人在前面狂奔,其他人只会复制提示词,不会判断输出,不会看变更半径,不会做权限核查,不会写验收证据,那 AI 最后会变成新的黑盒。
我的判断是:AI 编码不是替代工程体系,而是放大工程体系。
原来团队边界清楚、测试扎实、代码审查认真、权限治理规范,AI 会把它放大。
原来团队需求不清、接口乱补、权限散落、上线靠人盯,AI 也会把它放大。
所以技术负责人现在要做的,不是简单要求大家“多用 AI”,而是把 AI 使用变成团队标准动作。
1. 每个 AI 任务必须有任务范围。
2. 每次写入前必须说明允许修改哪些文件。
3. 涉及外部账号、生产配置、迁移脚本,必须人工确认。
4. 完成后必须提交验证结果,而不是只说“已修复”。
5. 复盘时更新团队规则,把踩坑变成下一次的边界。
这才是从个人提效走向团队治理。
先跑一个 30 天小闭环
如果一个团队现在刚开始上 AI 编码,我不建议一上来就喊“全面 AI 化”。
这话听着有气势,落地很容易变成一地碎片。
可以先用 30 天跑一个小闭环。
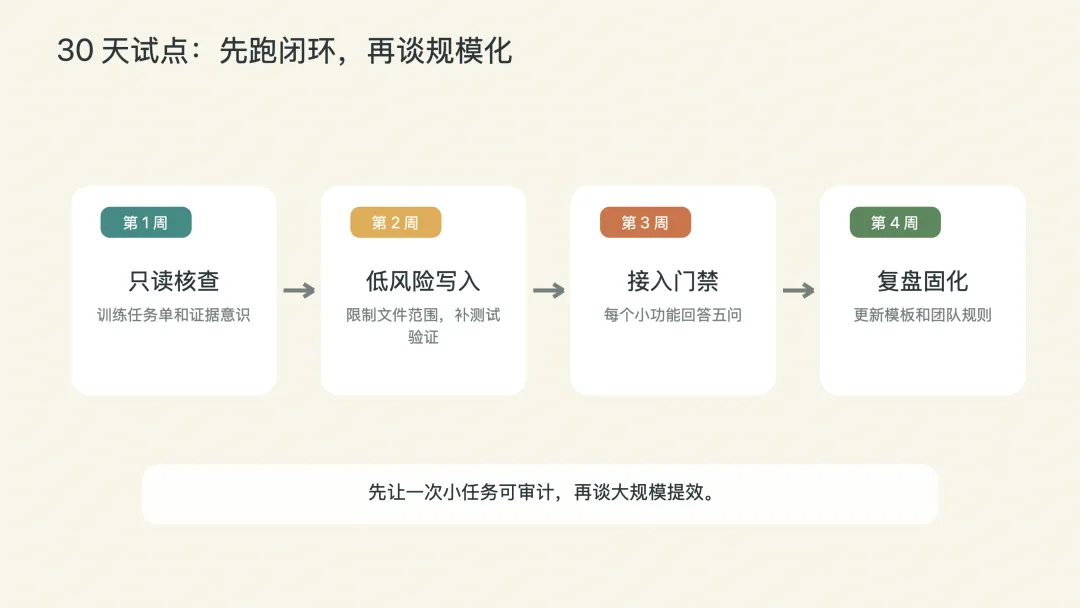
第一周,只做只读核查。
让 AI 查代码、找链路、写影响范围,不允许直接改生产相关文件。目标是训练团队怎么提任务、怎么看证据。
第二周,允许低风险写入。
比如补测试、修文案、改一个明确 bug,但必须限制文件范围,并要求给出 build/test 结果。
第三周,接入上线门禁。
每个 AI 生成的小功能,都必须回答五问:谁能看、数据从哪来、谁审、怎么验、怎么回退。
第四周,做一次复盘。
不要只统计节省了多少时间,而要看三件事:哪类任务最适合 AI?哪类任务最容易失控?哪些规则应该沉淀成团队模板?
到这里,团队才算真正摸到了 AI 编码的门。
不是因为工具多强,而是因为团队开始有了驾驭工具的规则。
最后给技术负责人的一句话
AI 编码会继续变强,生成代码会越来越便宜。
但企业系统真正稀缺的,不是生成速度,而是上线能力。
能不能守住权限,能不能管住数据,能不能留下审计,能不能证明验收,能不能及时回退。
这些事不热闹,却决定 AI 能不能进入真实业务。
所以这轮热点,我更愿意把它看成一次提醒:
不要让 AI 编码停在演示的兴奋里。先给它一套上线门禁,再让它往前跑。
