 夜雨聆风
夜雨聆风昨天
我领导里发了一条 30 分钟的 B 站长视频,让我"挑重点告诉他",我说"等一会我就搞"......
你是不是也有类似的情况?
YouTube 收藏夹堆了 50 个 tech talk,每个都点进去想"等会再看",半年没动一个。
看完一个教程视频想做笔记,反复倒带、截图、打字——30 分钟视频做完笔记花了 90 分钟。
抖音刷到一个看似有点东西的方法论想存下来——直接收藏 = 算法茧房继续投喂;想转文字 = 要么手抄要么开 Premiere 提音轨。
但你打开 Claude Code,把视频链接丢给它——它两手一摊:"对不起,我读不了视频。"
是的,Claude Code 原生不支持分析视频。这是它目前的硬限制:能读文字、能看图、能跑 bash 脚本,但视频它两眼一抹黑——你扔一个 YouTube 链接进去,它只会回"我打不开这个 URL";你扔一个本地 .mp4 进去,它会说"我没法处理视频文件"。
我想让 Claude 也能看视频——既是为了我自己(不再手动倒带、截图、打字),也算是给 Claude 解锁一份"多模态的快乐":让它能像看图一样看视频,逐帧理解 + 听懂音轨,再把信息塞回它擅长的文字侧。
于是有了这条「观影」咒语——本质是给 Claude 装一只"眼睛"和一对"耳朵",让原本看不见视频的它,也能站到视频笔记的工位上来。
5 秒结论
装一个 MCP 插件让 Claude 替我看视频。YouTube 链接直读字幕(零 API 消耗);B 站、X、小红书、微博 走 yt-dlp 下载到本地,再 ffmpeg 抽帧 + Gemini 2.5 Flash-Lite 转录
01
看视频写笔记的痛在三个不同的地方
YouTube / B 站 / 抖音的"看视频做笔记"痛点其实分三档,技术成本完全不一样。
第一档·YouTube:原生有 caption tracks(auto + 人工),yt-dlp 抽字幕几乎零成本。技术上是最简单的——但你还是要手动操作:找视频 → 打开开发者工具 → 拷字幕 → 喂给 LLM。一个动作 10 步,懒。
第二档·B 站 / X / 小红书 / 微博 / TikTok:字幕轨道要么没有,要么是私有 API 不公开。这一档要走 yt-dlp 下载视频本体 → ffmpeg 抽帧 + 抽音轨 → 把音轨喂 ASR 模型转文字 → 把帧 + 字幕一起送进 LLM。流程比 YouTube 多 3 步,但工具链都是开源现成的。
第三档·抖音:完全是另一回事——限制太严,先放一放
02
三档分流:dispatch 一段决定走哪条路
观影咒语的核心其实是一段约 20 行的 dispatch 逻辑:根据 URL host 判断走哪条路。下面这张表是规约本身:
本地 .mp4 / .mov / .mkv / .webm
→ 直传 plugin · 仅 Gemini ASR 一次开销
YouTube 5 域名(youtube.com / www / m / music / youtu.be)
→ plugin 内部 yt-dlp 抽字幕,字幕优先 fallback · 有字幕时 RPD = 0;无字幕走 Gemini ASR
Bilibili / TikTok / X / Weibo / 小红书
→ yt-dlp 下到 ~/.claude-video-vision/downloads/ · ffmpeg 抽帧 + Gemini ASR
关键工具链是 yt-dlp + ffmpeg + Gemini 2.5 Flash-Lite。yt-dlp 解 URL 拿原始视频,ffmpeg 在本地抽帧 + 抽音轨,Gemini 把音轨转文字。Gemini 2.5 Flash-Lite 是免费层(每天次数限制,可以建立不同的项目换key),日常看 5-10 个长视频不成问题。
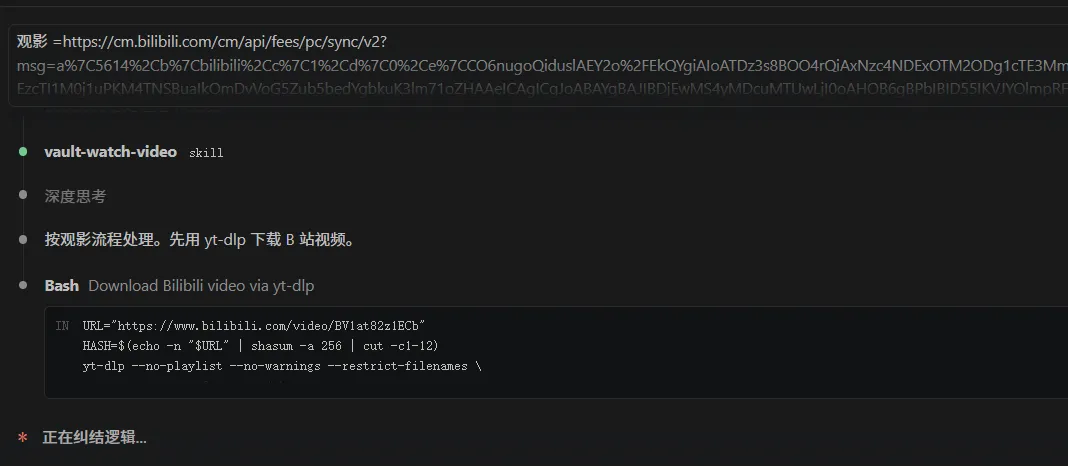
非 YouTube 平台下载的命令是写在咒语里自动跑的,长这样:
URL="<full-url>"HASH=$(echo -n "$URL" | shasum -a 256 | cut -c1-12)yt-dlp --no-playlist --no-warnings --restrict-filenames \ --merge-output-format mp4 \ -f "bv*[ext=mp4]+ba[ext=m4a]/b[ext=mp4]/bv*+ba/b" \ --paths ~/.claude-video-vision/downloads \ -o "${HASH}-%(id)s.%(ext)s" \ "$URL"
下载缓存有 7 天 TTL,过期自动清;同一个视频反复看不重复下载(hash 命中)。
03
长视频别一次抽帧 + ASR:会烧爆免费配额
这是观影咒语最容易被忽略的设计点:视频时长 ≥ 30 秒走两步,< 30 秒走一步。这条规则不写进 dispatch,免费配额一个晚上就能耗尽。
短视频 < 30 秒
video_watch path=<...> fps=auto
抽帧 + 调 Gemini api一起跑,一次调用搞定。
长视频 ≥ 30 秒
1. video_analyze path=<...> filters={transcription:true, scene_changes:true}2. video_watch path=<...> view_sample=12 skip_audio=true
skip_audio=true 是关键——transcription 在 step 1 已拿到;step 2 单纯抽帧就好,不要再调 Gemini ASR 一次。
这个 pattern 我踩过坑。第一版 SKILL.md 里没分两步,看一个 15 分钟视频要烧 6-7 次 ASR 调用(视频被切片,每切一次都重新转录)。免费配额一个晚上就用完。改成两步之后,一个长视频固定 1 次 ASR + 1 次帧采样 = 2 次 API 调用。
04
装机依赖一张表 + 第一次跑
观影咒语自身是一份 SKILL.md(约 170 行),但跑起来要 6 件东西就位:
1. claude-video-vision MCP plugin · 装到 ~/.claude/plugins/ · 提供 video_info / video_analyze / video_watch 三个 MCP 工具
2. ffmpeg · brew install ffmpeg · 抽帧 + 抽音轨
3. yt-dlp · brew install yt-dlp · 解 URL + 下视频
4. Gemini API key · Google AI Studio 申请(免费层 = 2.5 Flash-Lite)
5. Claude Code · 注册 plugin 用
6. ~/.claude.json · 在 mcpServers."claude-video-vision".env 块里写 GEMINI_API_KEY(不是 zshrc)
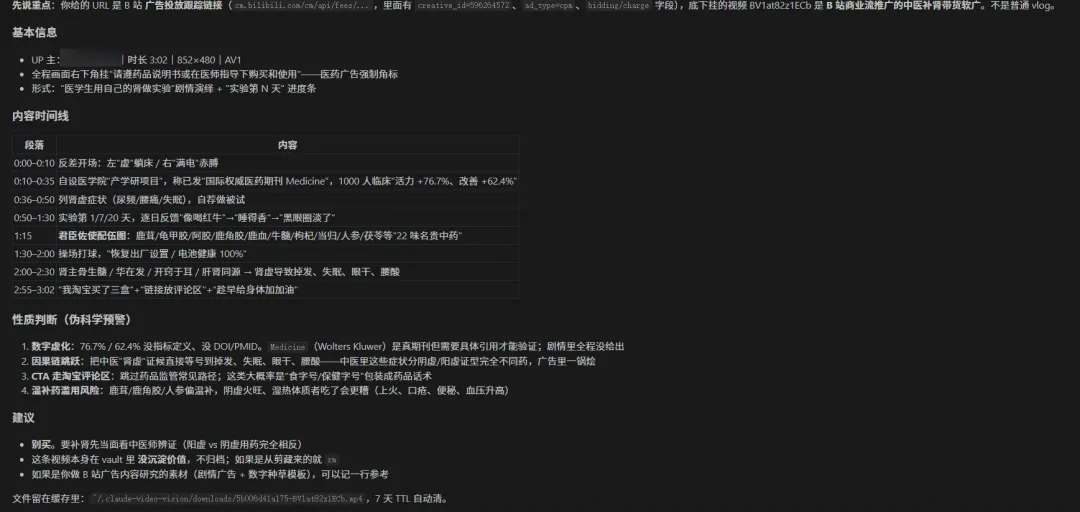
第一次跑(B 站为例):
你:观影 https://www.bilibili.com/video/BV1xxxxxxxxClaude:· 解析 URL → bilibili.com → 走 yt-dlp 下载分支· 下到 ~/.claude-video-vision/downloads/abc123-BV1xxx.mp4· video_info → 18 分 32 秒(长视频)· video_analyze(拿 transcription 全文)· video_watch view_sample=12 skip_audio=true(抽 12 帧)· 输出:标题 + UP 主 + 时长 + 帧描述 + transcription 段落
整个过程约 90 秒(受网络 + 视频长度影响)。一次 ASR + 一次帧采样,免费配额扣 2 次。
三个子命令(运维):
· 观影 升级 —— git pull plugin + npm rebuild(plugin 自身有迭代)
· 观影 清理 —— 清空下载缓存(7 天 TTL 之前手动清)
· 观影 换 key <newkey> —— 配额烧完换备用 key(自动备份 ~/.claude.json.bak)
免费配额耗尽?Gemini 2.5 Flash-Lite 日配额次日 16:00 北京时间重置(Google US Pacific 16:00 = UTC+8 16:00)。日内换 key 也行:再去 AI Studio 开个新 project 申请新 key,跑「观影 换 key <新 key>」切上。我备了 3 个 key 轮着用,没出现断档。
05
三句话回看
第一,看视频写笔记的工具链不止一条;YouTube 一档(字幕直读,零成本)、B 站等一档(yt-dlp + ffmpeg + Gemini)、抖音一档(绕路)——dispatch 写好就一行 SKILL.md 的事。
第二,长视频两步走,避免重复 ASR 烧爆免费配额——这个 detail 比"装好插件"重要。免费层不是无限喂的;省着用能撑久。
第三,别为单一平台养一只独立工具链;上游不修就先绕,等修好再续。把判断力留给我,把流水线留给 yt-dlp——这是工具链选型的根。
🎁 关注公众号 脉路 ,了解更多AI赋能姿势~。
