 夜雨聆风
夜雨聆风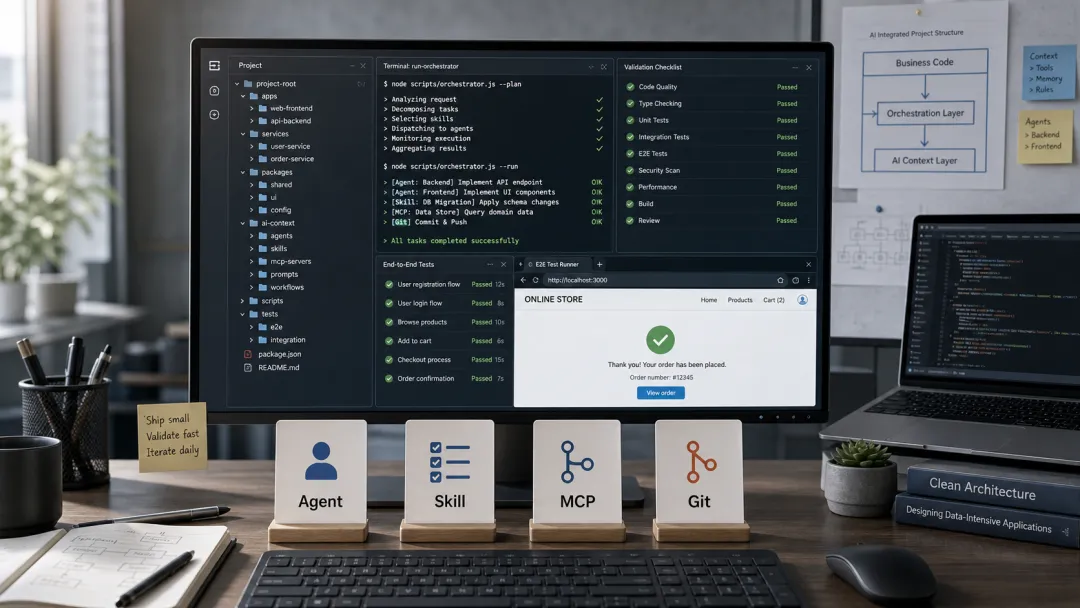
去年开始,越来越多的团队把 AI 接入日常开发流程。一开始大家都很兴奋:装一个插件,开一个聊天面板,AI 就能帮忙写代码、修 bug、生成文档。
但真正跑了一段时间之后,问题来了。
同一个 AI,在别人项目里像高级工程师,在你的项目里却像个刚入职的实习生:乱改目录、猜错启动命令、前后端脱节、审查形同虚设。更让人头疼的是,你很难稳定复现它的“聪明时刻”。
为什么?
答案其实不复杂:决定 AI 落地效果的,不是模型本身,而是项目结构、流程、规则、上下文和验证链路。
换句话说,AI 不是多一个聊天窗口,而是进入项目结构、流程、仓库、规范和验证链路里。
这篇文章,我们就用团队内部的 finance-system 项目,把这件事彻底讲透:AI 时代,一个项目到底该怎么组织,Agent 才能稳定干活。
一、AI 时代项目结构不只是代码结构
过去我们理解“项目结构”,通常只看这几个目录:
·前端目录
·后端目录
·配置目录
·Docker 部署目录
但在 AI 真正参与工程执行之后,一个可持续的项目至少包含五层结构。
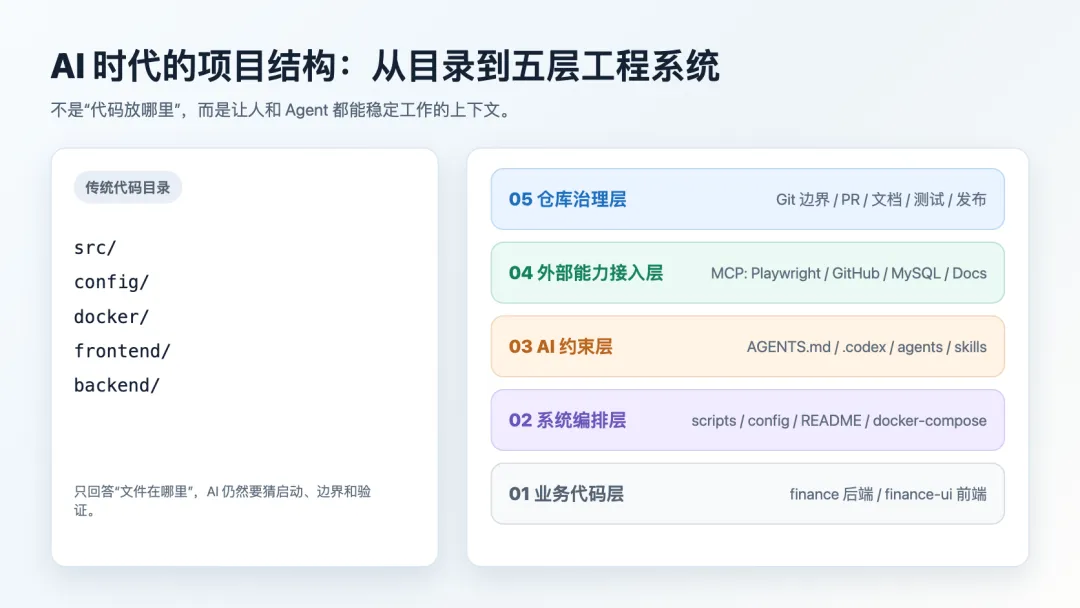
第一层:业务代码层就是 finance/ 后端和 finance-ui/ 前端。这一层解决的是“业务逻辑在哪里”。
第二层:系统编排层根目录下的 scripts/、config/、README.md。这一层解决的是“项目怎么启动、怎么部署、怎么联调”。
第三层:AI 约束层AGENTS.md、.codex/config.toml、.codex/agents/*、.codex/skills/*。这一层解决的是“AI 能做什么、不能做什么、按什么流程做”。
第四层:外部能力接入层MCP(如 Playwright、GitHub、MySQL、Docs)。这一层解决的是“AI 能调用哪些外部系统”。
第五层:仓库治理层Git 仓库边界、分支与 PR 规范、文档、契约、测试、发布流程。这一层解决的是“团队和 AI 长期协作的规则”。
一句话总结:
AI 时代,项目结构 = 代码结构 + 流程结构 + AI 上下文结构。
如果只有代码结构,AI 就只能“猜”。猜启动命令、猜依赖关系、猜前后端边界、猜验证步骤。猜得越多,出错概率越大。
二、用 finance-system 拆解 AI 工程化
finance-system 的项目结构长这样:
finance-system/├─ .codex/│├─ config.toml│├─ agents/│└─ skills/├─ AGENTS.md├─ README.md├─ config/│├─ .env│├─ .env.prod│├─ docker-compose.yaml│└─ nginx/├─ scripts/│├─ common.sh│├─ dev.sh│└─ docker.sh├─ finance/# 后端└─ finance-ui/# 前端
这个结构天然包含了四个层次,非常适合拿来解释 AI 工程化。
第一层:业务系统分层
finance/ 是后端,finance-ui/ 是前端。目录边界已经告诉 AI:谁是前端,谁是后端。AI 不需要在一个混乱目录里“自由发挥”,它的修改范围天然被约束。
第二层:根目录统一编排
scripts/dev.sh 负责本地联调启动,scripts/docker.sh 负责 Docker 编排,config/docker-compose.yaml 负责部署结构。
这意味着:AI 不应该自己猜怎么启动项目。 项目提供了统一入口,人和 AI 都能复用。否则 AI 可能会用错命令、搞错依赖顺序,甚至直接跑不起来。
第三层:AI 协作定义
根目录 AGENTS.md、.codex/agents/*.toml、.codex/skills/*/SKILL.md 已经把 AI 的职责、边界、流程写成了工程规则。AI 的行为不再是“玄学”,而是可配置、可审查、可优化的。
第四层:跨端协同意识
AGENTS.md 里明确写了:contract change 必须触发 contract-sync,跨端任务结束要执行 e2e-check,所有代码改动要执行 code-review。这已经很接近“AI 时代的项目治理”了。
三、四个核心概念,一次讲清楚
很多团队对 Agent、Skill、MCP、Git 的理解还停留在名词层面。我们用 finance-system 把它们落到工程里。
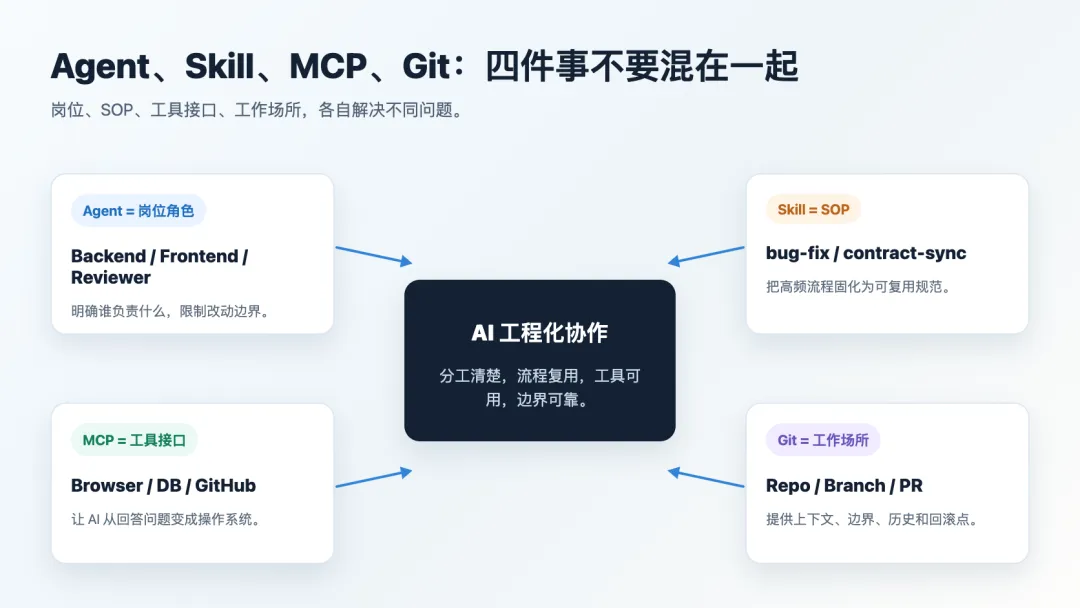
1. Agent:不是更强的提示词,而是岗位角色
Agent = 带职责、边界、工具权限、输出规范的 AI 执行角色。
在 finance-system 里,有四个 Agent:
·scheduler:调度 Agent,负责任务拆分和流程编排
·backend:后端 Agent,只改 finance/
·frontend:前端 Agent,只改 finance-ui/
·reviewer:审查 Agent,做结构化验收
没有 Agent 的时候,一个 AI 既要懂后端,又要懂前端,又要做审查,又要做联调。结果是边界不清,容易漏改,容易瞎猜。
有了 Agent 之后,scheduler 先拆任务,backend 只改后端,frontend 只改前端,reviewer 最后验收。
所以:
Agent 的本质不是让 AI 更像人,而是让 AI 更像团队中的岗位。
2. Skill:不是一句提示词,而是 SOP
Skill = 可复用的任务处理模板 / 工作流规范。
在 finance-system 里,有 api-design、bug-fix、code-review、contract-sync、e2e-check、incident-report 等 Skill。
Agent 解决的是“谁来做”,Skill 解决的是“这类事要怎么做”。
比如 contract-sync 是改接口时的标准流程,e2e-check 是跨端完成后的验证流程。团队把经验固化成了 Skill,AI 每次执行都走同一套 SOP,质量才稳定。
Agent 解决分工问题,Skill 解决重复问题。
3. MCP:让 AI 从“会说”变成“会操作”
MCP = AI 调用外部系统能力的标准接口。
没有 MCP,AI 只能看代码、写代码、回答问题。有了 MCP,AI 可以调浏览器做 E2E 测试(Playwright MCP),访问 GitHub 查 PR,查询数据库,读取文档中心。
finance-system 的 .codex/config.toml 里已经配置了 Playwright MCP,这就是让 AI 真正“动手”的关键一步。
MCP 让 AI 从“会说”变成“会操作”。
4. Git 仓库:AI 的长期工作场所
过去 Git 主要用于版本管理、协作合并、回滚。AI 时代,Git 多了两个作用:
·给 AI 清晰边界:仓库边界越清晰,AI 越不容易乱改。
·给 AI 提供可靠上下文:AI 会读目录、文档、规则、脚本、测试命令。如果仓库结构混乱,AI 也会混乱。
所以 Git 仓库不只是存代码,而是:
AI 的长期工作场所。
四、根目录不是杂物间,而是系统编排层
finance-system 的根目录放了 config/、scripts/、README.md、AGENTS.md、.codex/。这恰好说明一个重要观点:
根目录不应该堆业务代码,而应该承载“系统级规则与编排”。
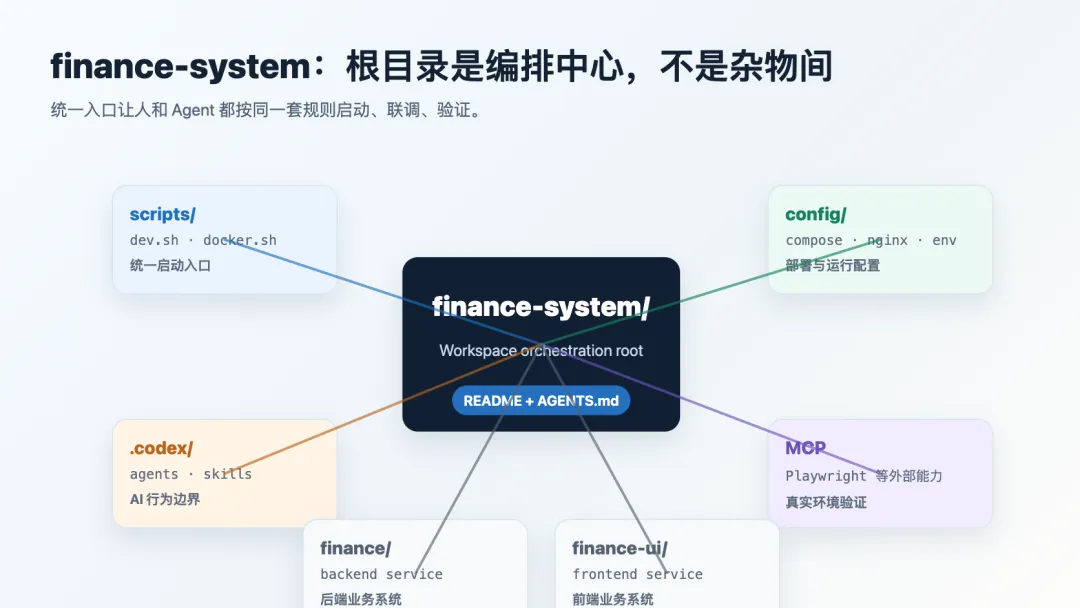
我们可以把项目分成三层来看:
·Workspace / 系统层(根目录):Docker Compose、启动脚本、AI 配置、跨仓库规范、部署配置
·服务层:finance/、finance-ui/
·运行层:MySQL、Nginx、文件上传目录、构建产物
这样分层之后,AI 进入项目,首先读到的是编排规则和约束,而不是一堆业务代码。它知道怎么启动、怎么联调、怎么验证,而不是从零开始猜。
finance-system 已经有了“AI 友好结构”的雏形:
·统一启动入口:bash scripts/dev.sh start,bash scripts/docker.sh prod up
·角色化 Agent:scheduler / backend / frontend / reviewer
·任务化 Skill:code-review / bug-fix / contract-sync / e2e-check
·跨端联动意识:contract change 先同步,任务结束做 E2E
这些都是让 AI 稳定执行的基础。
五、从样板走向规范:六个下一步优化
finance-system 已经不错了,但要从“样板”变成“规范”,还有六个地方可以优化。
1. 明确仓库边界
根目录目前像一个 workspace / orchestration repo。建议明确三种模式之一:
·三个独立仓库:finance-system-workspace、finance、finance-ui,适合团队边界清晰、独立发版
·根仓库 + submodule:根仓库负责编排,finance 和 finance-ui 作为 Git submodule
·单体 monorepo:适合小团队、前后端频繁协同、统一 CI/CD
对于当前项目,最自然的是“根编排仓 + 两个业务仓”。但不管选哪种,先定义仓库边界,再写 .gitignore,不要让 .gitignore 决定项目结构。
2. 重新设计 .gitignore
如果根目录是正式仓库,就不能把 finance 和 finance-ui 整体忽略掉,除非它们确实是外部子仓且不纳入版本管理。
3. 消灭本机绝对路径
README 中出现了 /Users/... 这类绝对路径。它只能在作者机器上成立,AI 会误当成通用路径,团队成员复制后经常失效。应该统一使用相对路径、仓库路径、命令示例和环境变量。
4. 敏感配置不要长期落仓
config/.env、config/.env.prod 在演示环境可以,但正式规范里应改为:仓库只放 .env.example,真实 secrets 交给部署环境 / CI / 密钥平台。
AI 时代配置要分为“可提交配置”和“不可提交秘密”。
5. 前后端 contract 自动化
当前已有 contract-sync Skill 和类型意识,下一步建议:
·后端 OpenAPI / Pydantic schema 成为单一事实源
·前端类型从 contract 自动生成,而不是手写镜像接口
·每次 contract 变更自动触发检查
前后端不要各写一份真相,要让一份 contract 成为真相。
6. 补一套 OpenCode 对齐配置
如果团队同时使用 OpenCode,建议增加 .opencode/ 目录,包含 agents、commands、tools 和 opencode.json。这样 .codex/ 面向 Codex,.opencode/ 面向 OpenCode,AGENTS.md 作为公共规则,形成双平台协作。
六、一个真实任务流转案例
案例:新增“工资已发放 released”状态。
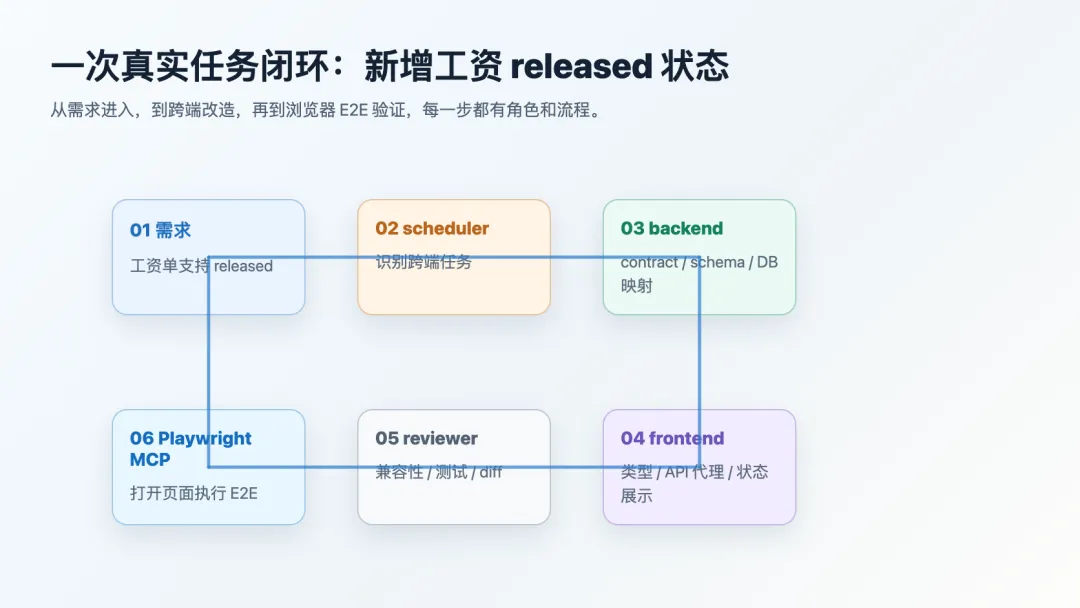
Step 1:需求进入业务希望工资单支持“已发放”状态。
Step 2:scheduler 判断这是跨端任务,触发 api-design,触发 contract-sync,完成后触发 e2e-check,最后触发 code-review。
Step 3:backend 处理修改 Pydantic contract,修改 HTTP 返回 schema,修改数据库状态映射,输出 contract diff。
Step 4:frontend 处理更新类型定义,更新 API 代理,更新状态展示文案/颜色/筛选。
Step 5:reviewer 处理检查 breaking change,检查前端是否遗漏旧状态兼容,检查是否补了验证步骤。
Step 6:Playwright MCP 验证打开工资页面,查询状态,执行发放动作,检查列表状态变化。
这就是 AI 时代的一个完整任务闭环:从需求到调度、后端、前端、审查、E2E 验证,每一步都有明确的角色、流程和工具。
七、给团队的落地建议
最后,用五句话收尾:
1.先整理项目结构,再上 AI。 结构不清晰,AI 只会放大混乱。
2.先定义岗位边界,再定义 Agent。 不要让一个 AI 做所有事。
3.先把高频工作写成 Skill,再交给 AI。 经验不固化,质量不可控。
4.先把外部系统做成 MCP 接口,再让 AI 使用。 让 AI 真正能操作,而不只是能聊天。
5.先让仓库、脚本、文档可读,再要求 AI 稳定执行。 AI 的上下文质量,决定了它的执行质量。
finance-system 已经不是单纯的“前后端项目”,而是一个具备工作区编排、AI 角色分工、Skill 流程化、MCP 扩展能力的雏形。接下来要做的,不是推翻重来,而是把仓库边界、配置管理、contract 自动化、OpenCode 对齐配置进一步标准化。
AI 工程化的关键,从来不是炫技,而是标准化。
