夜雨聆风
夜雨聆风
2025 年 6 月的 Confluent Current 大会上,OpenAI 的实时基础设施团队连续做了两场分享,完整披露了他们如何在一年内将 Apache Kafka 吞吐量提升 20 倍、可用性从不到 3 个 9 拉到 5 个 9(来源:OpenAI at Confluent Current 2025)。更值得拆解的是他们为此放弃了什么:排序、事务、分区处理,这些 Kafka 最核心的语义。
2024 年上半年,OpenAI 的流处理平台已经被几乎所有产品团队采用,数据摄入、异步处理、服务间通信,ChatGPT 的后端链路上到处都是 Kafka。但平台本身的状态用"混乱"来形容并不过分。
当时 OpenAI 内部有超过 30 个独立的 Kafka 集群,大多数是各产品团队在不同时期临时自建的。这些集群配置互不兼容,部分甚至运行在不同的 Kafka 兼容引擎上。一个新加入的工程师面对的第一个问题不是"怎么用 Kafka",而是"我的 topic 在哪个集群上"。产品团队接入 Kafka 要花数天甚至数周,本来几小时就该搞定。
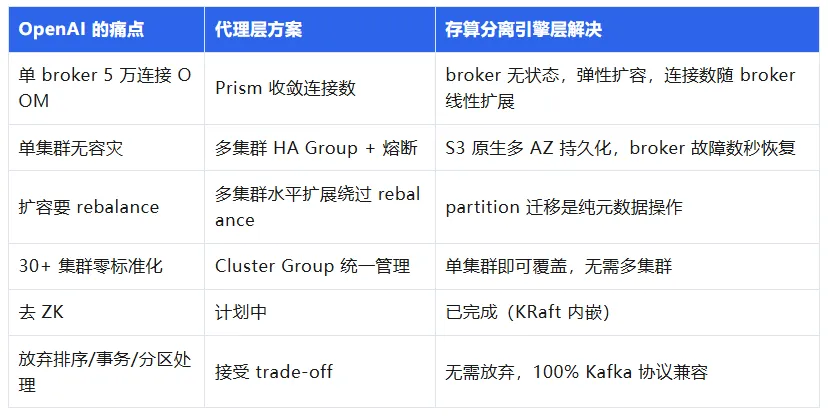
扩展性问题更为严峻。OpenAI 的外部服务有大量副本来承载 ChatGPT 的流量,每个副本都独立连接 Kafka 集群。更棘手的是,OpenAI 主要使用 Python,而 Python 的 GIL 限制意味着单个 pod 内需要运行多达 50 个独立进程来榨取并行性能,每个进程都会建立自己的 Kafka 连接。结果是某个集群的单个 broker 承受了 50,000 个并发连接,JVM 内存直接打满,连接不断被丢弃。这不是连接风暴,而是稳态下的常态过载。
可用性方面,Kafka 集群是许多内部服务的单点故障。一次区域故障或集群崩溃就意味着面向外部的产品硬停机或数据丢失。整个平台连 3 个 9 都撑不住,对于支撑 ChatGPT 的基础设施来说,这是不可接受的。
这些问题都还能忍。真正卡死他们的是基础设施团队根本动不了:产品服务与具体的 Kafka 集群紧耦合,想做集群迁移、版本升级、甚至只是调整配置,都需要协调大量产品团队。
要打破这种耦合,OpenAI 选择了一个经典的架构手段:在客户端和 Kafka 集群之间加一层代理,让所有服务都通过代理交互,而不是直连集群。
首先要解决的是连接数爆炸。他们构建了 Prism,一个极简的 gRPC 服务,只暴露一个 ProduceBatch 端点。生产者把消息和目标 topic 发给 Prism,由 Prism 负责路由到正确的底层 Kafka 集群。用户不再需要知道哪个集群承载哪个 topic,也不需要配置集群凭证和防火墙规则。他们甚至开发了一个叫 Photon 的客户端库,让接入简化到"import 库,调用一个函数"的程度。单个 Prism pod 服务多个客户端 pod,Kafka broker 的直连数大幅收敛。
连接数收敛了,但集群耦合还在。Prism 真正强大的地方在于多集群路由:同一个 topic 可以由多个 Kafka 集群服务,Prism 负责在这些集群之间做负载均衡。如果某个集群的发布请求失败,Prism 会透明地重试到另一个集群;如果某个集群长时间降级,熔断器会将其标记为不可用,自动绕过。配合 Cluster Group 的概念(一组包含相同 topic 的 Kafka 集群集合),高可用 Cluster Group 将多个集群部署在不同区域,Prism 写入任意一个健康的集群。所有这些对生产者完全不可见。
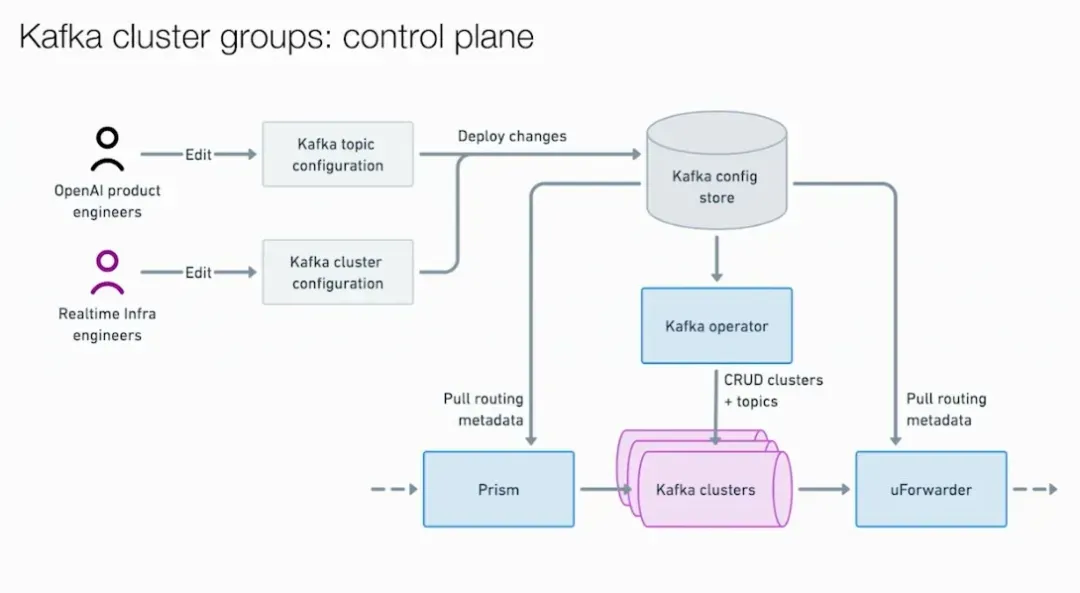
openai prism for kafka生产者侧解耦了,消费者侧同样需要脱离对 Kafka 客户端的直接依赖。OpenAI 采用了 Uber 开源的 UForwarder,并将其定制为内部的 Kafka Forwarder。这是一个推送模型的消费平台:UForwarder 从 Kafka 拉取消息,通过 gRPC 推送给消费者服务。消费者只需要暴露一个处理消息的 gRPC 端点,不需要接触 Kafka 客户端、不需要管理 offset、不需要配置凭证。UForwarder 还内置了重试、死信队列等生产级能力,并且支持超越 partition 数量的并行度。
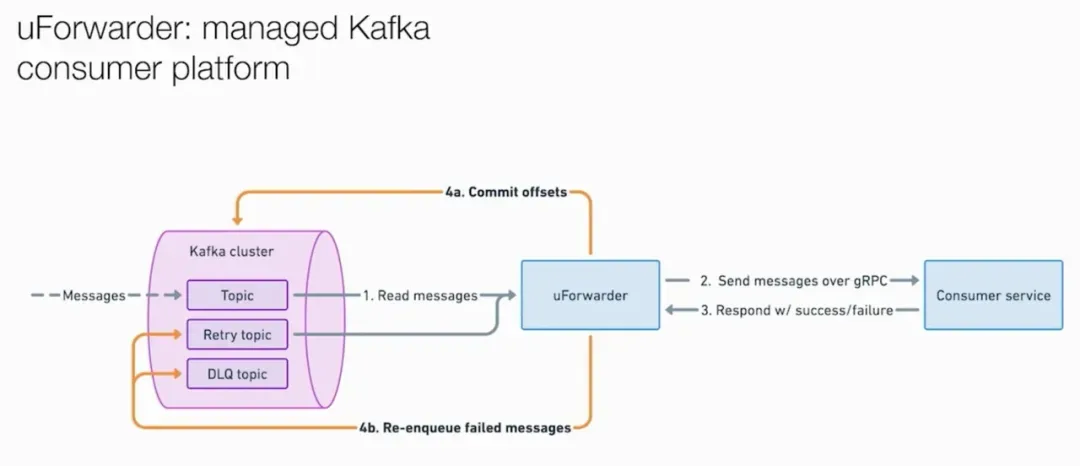
uber UForwarder for kafka迁移过程本身设计得很巧妙:在新集群上创建 topic,UForwarder 同时从新旧集群消费,Prism 逐步将写入切换到新集群,旧集群数据过期后下线。单次迁移约 30 分钟完成流量切换,对用户完全透明。最终成果:
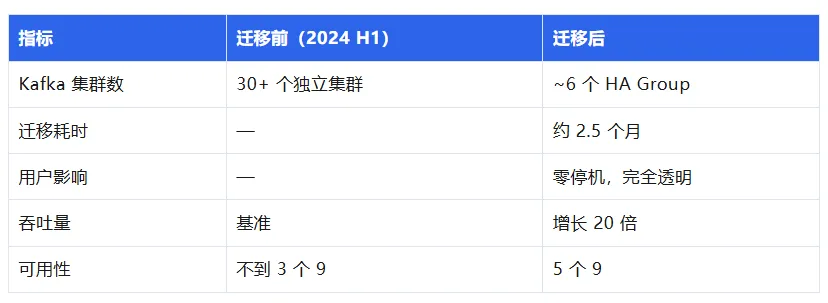
OpenAI 的工程师在演讲中非常坦诚地承认了一件事:这套架构要求他们放弃 Kafka 的几项核心语义。

这不是边缘功能的取舍。排序、事务、分区,这些是 Kafka 区别于普通消息队列的核心能力,是很多流处理场景的基础假设。OpenAI 的哲学是"Simple things should be simple, complex things should be possible",他们为少数需要这些能力的用例保留了直连 Kafka 的逃生通道,但绝大多数用例被引导到了代理层。
OpenAI 的工程师说,经验上用户确实不太在意这些限制,采用率反而因为简化而快速增长。这在 OpenAI 的语境下可能是对的,他们的 Kafka 用例以异步处理和数据摄入为主,对排序和事务的需求确实不高。但对于更广泛的 Kafka 用户群体来说,这个 trade-off 暴露了一个根本性的问题:如果获得云级别的弹性和可用性,必须以放弃核心语义为代价,那说明问题不在应用层的 trade-off 决策,而在 Kafka 引擎层本身。
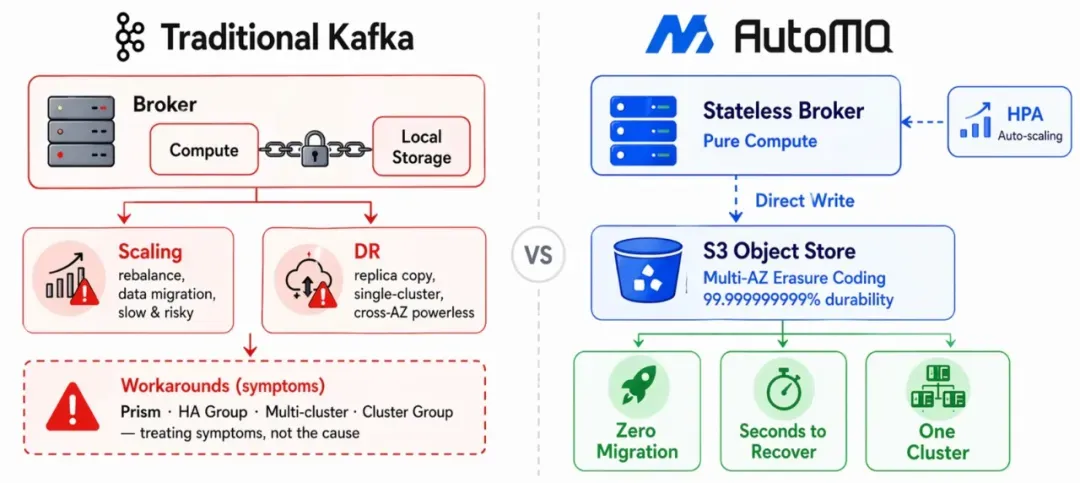
OpenAI 用代理层绕过的每一个问题,根因都一样:broker 既管计算又管存储,状态和节点绑死。如果这个根因在引擎层被解决,broker 变成无状态的,数据持久化到共享对象存储,这些绕行方案就失去了存在的前提。
回到 OpenAI 那个 5 万连接打满 JVM 的场景。他们用 Prism 收敛连接数,本质上是因为不能随意增加 broker,每加一个 broker 就要做数据 rebalance,搬迁大量分区副本,过程缓慢且影响在线流量。如果 broker 是无状态的,扩容就是加一个计算节点的事情,连接容量随 broker 数量线性扩展,甚至可以用 Kubernetes HPA 自动伸缩。
扩容的故事也类似。OpenAI 选择"加新集群"而非"给现有集群加 broker"来做水平扩展,就是因为后者的 rebalance 太危险。当 partition 的数据不在 broker 本地而是在共享存储上时,partition 迁移变成纯元数据操作:更新一下"这个 partition 由哪个 broker 服务"的映射关系就行,不搬一个字节的数据。弹性问题从根源上消失了。
再看 OpenAI 花了最大工程量的部分:多集群 HA Group、Prism 熔断器、跨集群重试,这整套故障转移体系。传统 Kafka 的多副本复制提供了 broker 级别的容错,但面对区域故障或整个集群不可用的场景,副本复制无能为力,因为副本都在同一个集群内。
如果数据直接写入 S3 等对象存储,持久化天然是多 AZ 的(S3 通过纠删码提供 11 个 9 的持久性),broker 故障时任何存活节点都可以接管分区并在数秒内恢复服务。S3 的多 AZ 纠删码已经做了这件事,OpenAI 在应用层又做了一遍。
当单集群就能通过弹性伸缩应对流量变化、通过对象存储保证跨 AZ 持久性时,OpenAI 维护 37 个集群的前提就不存在了。集群数量自然收敛,ZooKeeper 的瓶颈也随之消失,存算分离架构天然适配 KRaft,无需外部协调组件。而最关键的是,OpenAI 放弃排序、exactly-once semantics、分区处理,根本原因是多集群路由破坏了 key 到 partition 的映射关系。在存算分离架构下,单集群就能提供足够的弹性和可用性,不需要多集群路由这个前提,自然也就不需要放弃这些语义。100% 的 Kafka 协议兼容意味着所有现有的 Kafka 客户端、Kafka Connect、Kafka Streams 都可以无缝使用,不需要改一行代码。
AutoMQ 就是沿着这个方向构建的存算分离 Kafka 实现。把 OpenAI 的每个痛点、他们的代理层方案、以及引擎层的直接解法放在一起:
当然,把数据写到 S3 不是没有代价。对象存储的 API 调用延迟高于本地磁盘,尾延迟(p99/p999)需要额外优化;高频小批量写入场景下 S3 API 调用本身的成本也不能忽略。这是一个不同的工程权衡点,不是银弹。
存储成本方面,传统 Kafka 的三副本复制叠加 EBS(Elastic Block Store)自身的冗余复制,实际存储冗余度远高于对象存储的纠删码方案。存算分离架构消除了 broker 间的副本复制,数据直接写入 S3,由对象存储的纠删码保证持久性,存储成本显著降低。具体的成本对比数据可参考 AutoMQ 官方 benchmark。
在 2025 年 6 月 Confluent Current 的 Q&A 环节,有人问 OpenAI 的工程师怎么看 Diskless Kafka,回答是"非常积极地在思考和探索"。当你已经为绕过传统 Kafka 的限制付出了这么大的工程代价,引擎层的根本性演进自然是最有吸引力的下一步。OpenAI 证明了即使放弃排序和事务也能让 Kafka 在超大规模下工作,但这个代价本身就是最好的论据:引擎层的演进已经不是可选项。对于正在规划下一代流处理基础设施的团队来说,问题只是现在就在引擎层解决,还是先建一层代理再说。
如果你也正在为各种 Kafka 挑战而烦恼,可以立即通过 AutoMQ 官网或者 Github 体验和尝试我们的产品。
Chrome 开了一个危险的头:偷偷给数亿电脑塞 4GB Gemini 模型,占硬盘、耗算力、删了自动重下
智能体=新型攻击入口?模型上线前,OpenAI内部到底审什么?董事会成员首次详解
从0到10万Star只需一个周末:开源项目的信任危机,也许是那群“以为自己会写代码”的资本大佬造成的