 夜雨聆风
夜雨聆风某股份制银行分行在内部试点智能问数系统。上线第一个月,分管行长问了一句“各支行上季度个贷不良率”,系统给出了3.2%。风控部一看这个数字就觉得不对——他们每月手工报送的数据是2.1%。排查了一整天,问题不在SQL,不在大模型,在“不良率”三个字。风控部定义的不良率分母是“五级分类后三类贷款余额”,而系统默认取的数据库视图用的是“逾期超90天贷款余额”。同一栋大楼里,“不良率”有两个定义,系统选了错的那个。
几乎同一时间,一家汽车零部件供应商也给车间主管开通了智能问数权限。主管用他日常说话的方式问了一句“B线昨晚夜班跑得怎么样?”系统返回了空结果。换了三种问法,都不行。主管的评价很直接:“这东西还没Excel好用。”实际上,这个问题的标准答案是存在的——就在生产MES系统里,查询“B产线 晚班 当日完工产量 合格率”即可。但“跑得怎么样”这四个字,没有任何一张表、任何一个字段里出现过。
这两个现场都不是技术故障。SQL没有语法错误,数据库没有宕机,大模型输出也没有幻觉。行业公开数据显示,某金融企业在采用传统NL2SQL方案时,复杂查询的准确率不足65%。而这65%的失分项里,真正因为SQL语法写错而翻车的比例,远低于因为理解错了业务术语而翻车的比例。

Gartner在2025年数据与分析峰会上明确指出:超过一半的AI项目从未进入生产环境,近40%因数据散落、质量差、可访问性有限或治理不透明而失败。Gartner进一步预测:到2027年,在AI就绪数据中优先考虑语义的组织,其生成式AI模型准确率将提升高达80%,成本降低高达60%。
这个宏大预测的背后,是一个被反复验证的技术事实:业务语境的缺失,是智能问数系统从“Demo可用”到“生产可信”之间最大的一道坎。
劳埃德银行的实践数据精确地量化了这一点:他们在NL2SQL系统的数据库Schema中添加了同义词、行业缩写和已验证的示例查询之后,准确率从80%提升到了86.1%。BlazesQL在2026年NL2SQL技术指南中引用这项实践时,下了一个耐人寻味的判断——“这一项调整带来的提升,甚至超过了直接换用更新版本的大模型”。他们由此总结了一条更根本的原则:一个普通模型配上高度富化的语义层,会轻易地超越一个在真空中运行的顶尖模型。
翻译成企业决策者听得懂的话:如果不在系统里提前建立一套“业务语言→数据语言”的翻译机制,再好的大模型也听不懂你的人到底在说什么。

你的企业里,有多少种“黑话”
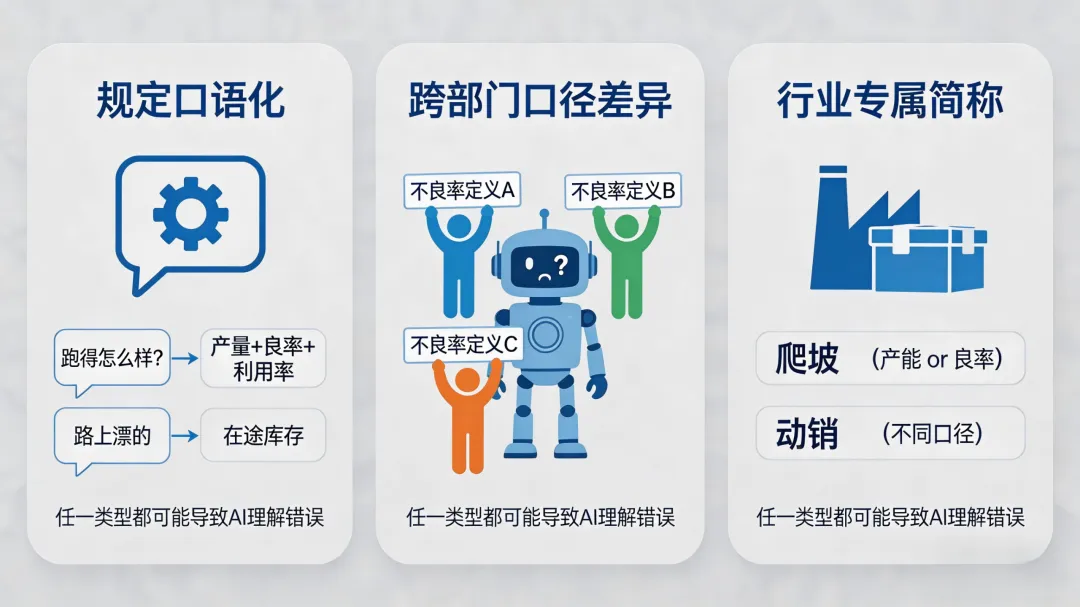
企业内部的业务术语混乱,通常表现为三种类型。每一种单独拿出来似乎都不是大事,但当它们集中出现在智能问数系统面前时,就成了让正确率断崖式下跌的合力。
第一类:规定口语化——话都是对的,但AI接不住。
车间主任说“跑得怎么样”,他要的其实是“良品率+日产量+设备利用率”三个指标的组合。采购员说“路上漂的还有多少”,他问的是“已发货未入库的在途库存”。财务说“这个月钱回来得怎么样”,他要的是“本月回款率”。
这些口语是完全正确的企业内部交流语言,在自己的团队里沟通效率极高。但对AI来说,要理解它们,唯一的办法是提前教会它这些词等价于什么。而这恰恰是大多数智能问数项目在上线前跳过的步骤。
第二类:跨部门口径差异——同一个词,三个部门三个定义。
银行案例里,风控部、业务部、计划财务部对“不良率”各有自己的算法。一家车企的案例同样具有代表性:同一个“准时交付率”,采购部按订单承诺日计算,生产部按产线完工日计算,物流部按客户签收日计算。AI系统默认选择其中一个定义时,必然被另外两个部门视为“算错了”。
口径的差异不会在Demo中暴露——Demo用的是干净数据,问的是标准问题。但一旦进入生产环境,口径不一致就是导致业务部门“用不起来”的头号原因。
第三类:行业专属简称——默认词典里根本没有这些词。
制造业的“爬坡”可能指良率爬坡,也可能指产能爬坡,还可能指新品导入期的生产爬坡。快消行业的“动销”在不同的语境下对应不同的数据口径——有时指单店单周售出数量,有时指分销商进货后的售出比例。某个地区或某个师傅口头传下来的缩略语,有时连本公司的IT部门都不知道,更不用说通用大模型。
不是加几个同义词,是建一套翻译机制
解决术语混乱问题,最容易想到的思路是“加词典”——把行业黑话的同义词手动录进去。这件事确实有效,劳埃德银行的+6.1%就是明证。但光靠加词典,有三件事做不到。
第一,一次性手工录入覆盖面无法穷举,词典需要持续维护——每天都有新同事在某个角落喊着新词,静态词典很快就开始失效。第二,同一个口语在不同上下文里指向的是不同的数据指标——“爬坡”到底是产能爬坡还是良率爬坡,单靠同义词映射判定不了。第三,当多张表被同一个口语化的表达关联上时,到底应该听哪张表的,词典本身给不出答案。
这解释了为什么行业共识正在从“静态词典”走向语义层——一套将业务术语与数据库之间建立确定性映射关系的工程化机制。它不是简单地加几个同义词,而是在业务语言和数据Schema之间架起一座真正的桥梁。
学术前沿印证了这一方向。面向企业级中文数据库的Text-to-SQL基准测试Falcon显示,在真实的企业兼容SQL环境下,600道中文查询问题覆盖28个数据库,77%的查询需要多表推理,超过半数查询涉及四张表以上。在这个数量级的复杂度下,单靠静态词典已经不可能覆盖所有术语映射需求——你不可能靠人手工维护四张表之间的全部业务黑话对应关系。
工程实践也给出了验证。Snowflake的研究表明,通过智能体驱动的语义模型自动改进——连接业务术语到数据库表、列、主键和外键——可以显著提升Text-to-SQL准确率,语义模型驱动的自动化迭代就将准确率平均提升了5%以上。IBM的研究则从Schema Linking切入,通过分治策略将复杂问题分解为子问题,先精准定位每个子问题对应的表和列,召回率提升了25.1%,执行准确率提升了8.2%。

评估系统时,多问一个“翻译”问题
下次评估智能问数系统时,除了看Demo里单表单次查询跑得多快、多准,建议把Demo放在一边,先做一个测试:让业务部门派一个代表,用平时跟同事交代任务的日常表达方式,对着系统问一个包含行业术语的跨表问题。然后观察三件事:
第一,系统能不能识别出“路上漂的”等于“在途库存”?第二,跨部门之间“准时交付率”的不同定义在系统里如何被区分和处理?第三,那些从来没有出现在任何计算字段或数据库注释里的口语化表达——车间里口口相传的“跑得怎么样”、采购部日常挂嘴边的“调拨”——系统是怎么承接的?
这件事光靠一次Demo问不出来,但只要用企业内部真正使用的那套语言去追问系统,马上就能看清它的真实成色。
我们的技术团队在实际部署中反复验证过一个结论:大模型能理解标准SQL,但听不懂车间主任说的“爬坡”、采购员嘴里的“调拨”、财务部的“回款”。智能问数系统能不能被业务部门真正用起来,往往不取决于SQL生成得有多快,而取决于它对业务语言的翻译能力有多强。
如果你的企业在引入智能问数系统后,也遇到过“技术跑通了但业务不买账”的情况——系统生成的SQL没问题,但业务部门就是觉得“它听不懂我”——欢迎找我们聊聊这个问题的解法。不推产品,只做技术交流。

《企业智能问数落地实战》——只写能落地的企业智能问数
下期预告:我们聊聊另一个被企业普遍忽视的问题:大多数企业在引入AI问数时,只关注“查得快不快”,却忽略了“查得对不对”背后的可追溯与可审计机制——当AI给出的数据与业务预期不一致时,能不能顺藤摸瓜找到断在哪一步?

光棱智瞳技术团队
我们是一支专注于企业智能问数落地的技术团队。无论是车间班组长还是财务经理,他们口中一个顺口的行业黑话、一次下意识的多表关联提问,都是AI系统理解业务的线索。我们日常做的,就是把这些表达梳理清晰,让每一次查询都有据可循,让系统真正“入乡随俗”。
