 夜雨聆风
夜雨聆风OpenAI 正式推出 GPT-5.5,官方定位为「迄今最智能、最直观、最适配真实工作流」的旗舰模型,主打 Agent 原生能力、更少 Token 消耗、更强长任务自主性,是 GPT-5 系列发布以来的最大一次升级。
核心定位:从 “会对话” 到 “会干活” 的原生 Agent
官方口号:用更少的指令,干更难的活(Do more with less guidance)。
核心进化:面向模糊需求,能自主理解意图、拆解多步骤、调用工具、自查结果并闭环推进,无需用户精细指导每一步。
适用场景:代码工程、数据分析、科研计算、跨工具办公、长文档处理、复杂命令行操作等。
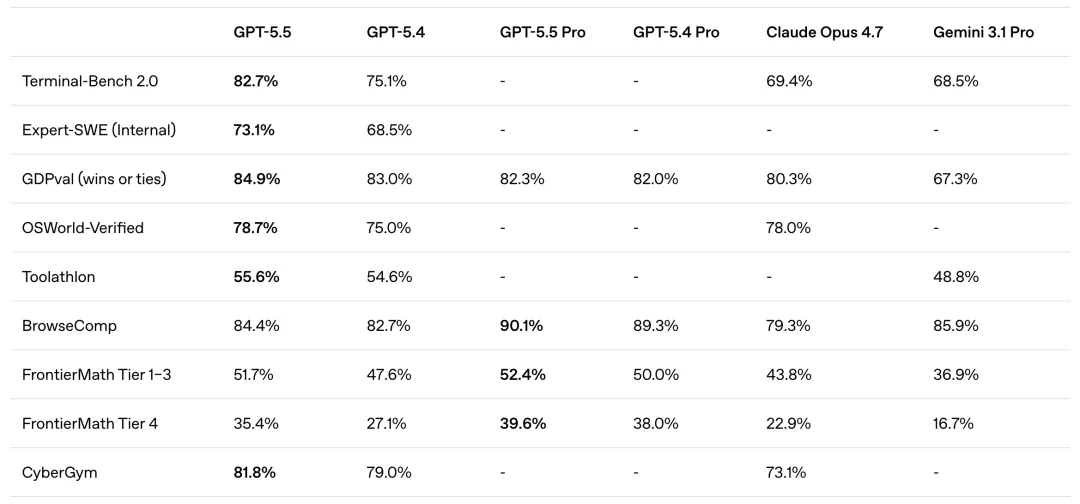
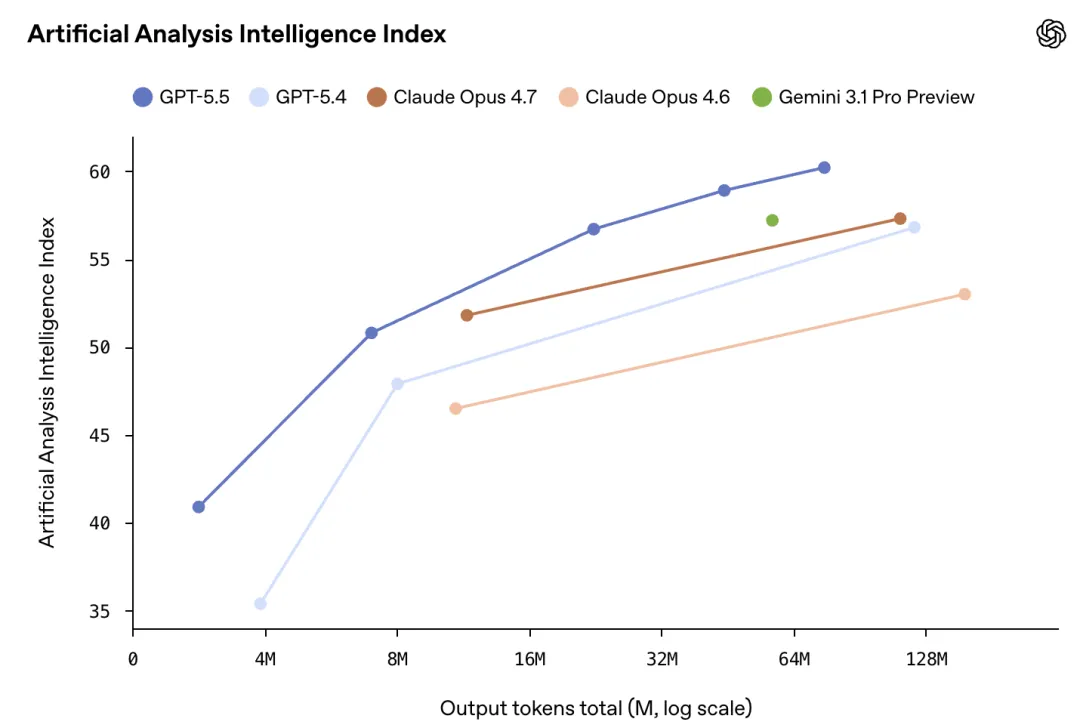
关键能力跃升:基准测试全面领先
1. Agent 与编程(最强项)
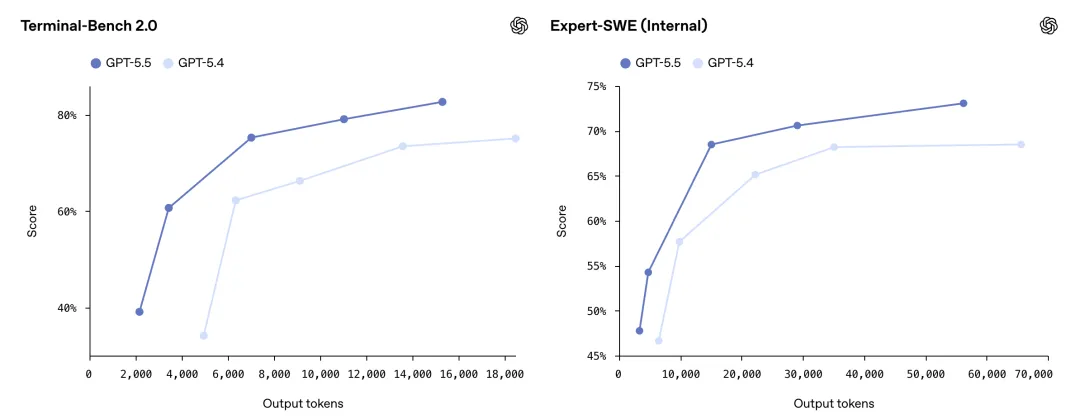
Terminal-Bench 2.0(复杂命令行):82.7%(GPT-5.4 75.1%,Claude Opus 4.7 69.4%)。
Expert-SWE(20 小时长周期软件工程):73.1%(GPT-5.4 68.5%),接近资深工程师水平。
SWE-Bench Pro(GitHub 真实问题):58.6%。
Coding Agent Index:成本为竞品一半,开源 + 闭源第一。
2. 效率革命:更少 Token,更低成本
Token 消耗:同任务比 GPT-5.4 减少 30%–50%,部分场景降至 1/35。
速度:单 Token 延迟与 GPT-5.4 持平,更快出结果、更少输入。
定价(API):输入 $5 / 百万 Token、输出 $30 / 百万 Token(较 GPT-5.4 翻倍)。
更广泛的应用场景:
GPT-5.5 聚焦企业级智能体、编码、知识工作及高阶数学科研等场景,能够承担从市场调研、会议纪要整理、财务分析,到编程协作、客服自动化和知识管理等大量重复性任务。
OpenAI 正推进 ChatGPT、Codex 与 AI 浏览器一体化整合,旨在打造用户与世界交互的统一入口,进一步提升企业运营效率。
安全性和可靠性的提升:
GPT-5.5 采用了更系统的对齐训练和分层安全机制,在危险内容识别、欺诈信息生成防范、生物安全风险控制以及未成年人保护方面进行了强化。
模型在面对高风险请求时,能够更准确地区分合法用途与滥用意图,减少误判与漏判。
