 夜雨聆风
夜雨聆风【导读】开发者 Mass 在 X 上发帖称 Mac Studio 是本地 AI 的"陷阱"——大统一内存在纸面上很诱人,但真到 24/7 工具调用、生产级推理场景,缺少 CUDA 生态就是死穴。帖子获得 254 个赞、3.6 万次浏览,评论区迅速分成两派。但事情远比"Mac vs GPU"复杂:vLLM 和 SGLang 都已经有了 Apple Silicon 的实验性支持路线,而 Mac Studio 在特定场景里的价值确实存在。关键在于——你到底要解决什么问题?
"像拥有一辆最高时速 100 公里的保时捷"
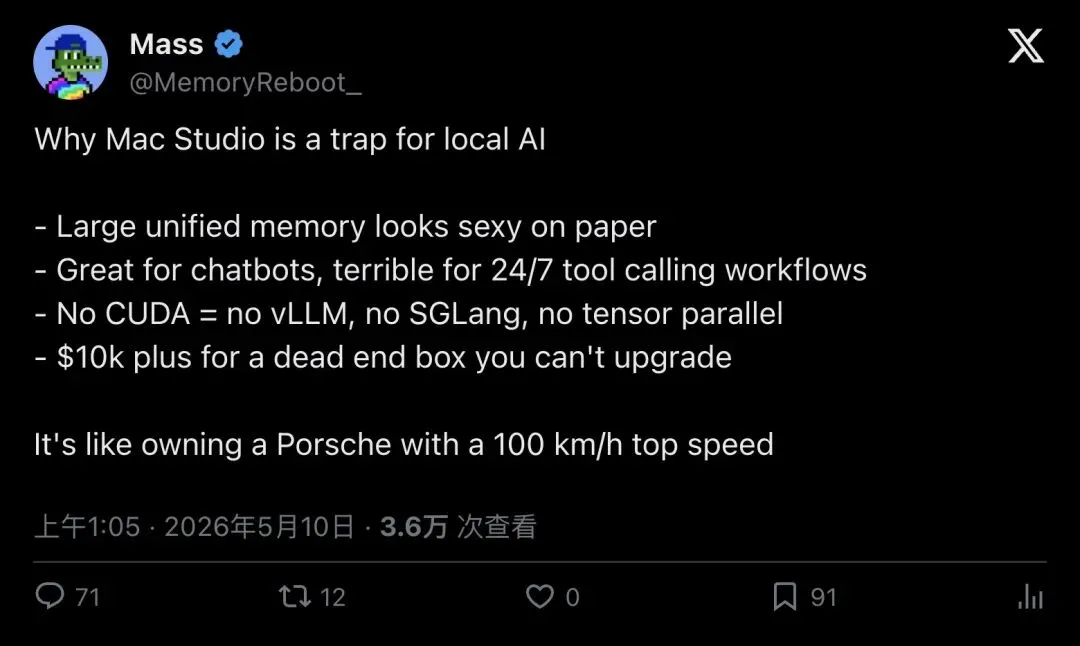
5 月 10 日,X 用户 Mass(@MemoryReboot_)发了一条帖子,标题直白到刺眼:
"Why Mac Studio is a trap for local AI"
「为什么 Mac Studio 是本地 AI 的陷阱。」
他列了四条理由:
- Large unified memory looks sexy on paper
- Great for chatbots, terrible for 24/7 tool calling workflows
- No CUDA = no vLLM, no SGLang, no tensor parallel
- $10k plus for a dead end box you can't upgrade
「大统一内存在纸面上很性感;做聊天机器人还行,24/7 工具调用工作流很糟;没有 CUDA 就没有 vLLM、SGLang、tensor parallel;花一万多美元买一台不能升级的死胡同机器。」
最后一句杀伤力最大:
"It's like owning a Porsche with a 100 km/h top speed."
「像拥有一辆最高时速 100 公里的保时捷。」
帖子发出后迅速发酵,评论区的开发者分成了两个阵营。
▲ Mass(@MemoryReboot_)的原帖,引发开发者社区激烈争论
Mac Studio 凭什么让人上头?
先说前提:Mac Studio 的吸引力确实扎实。
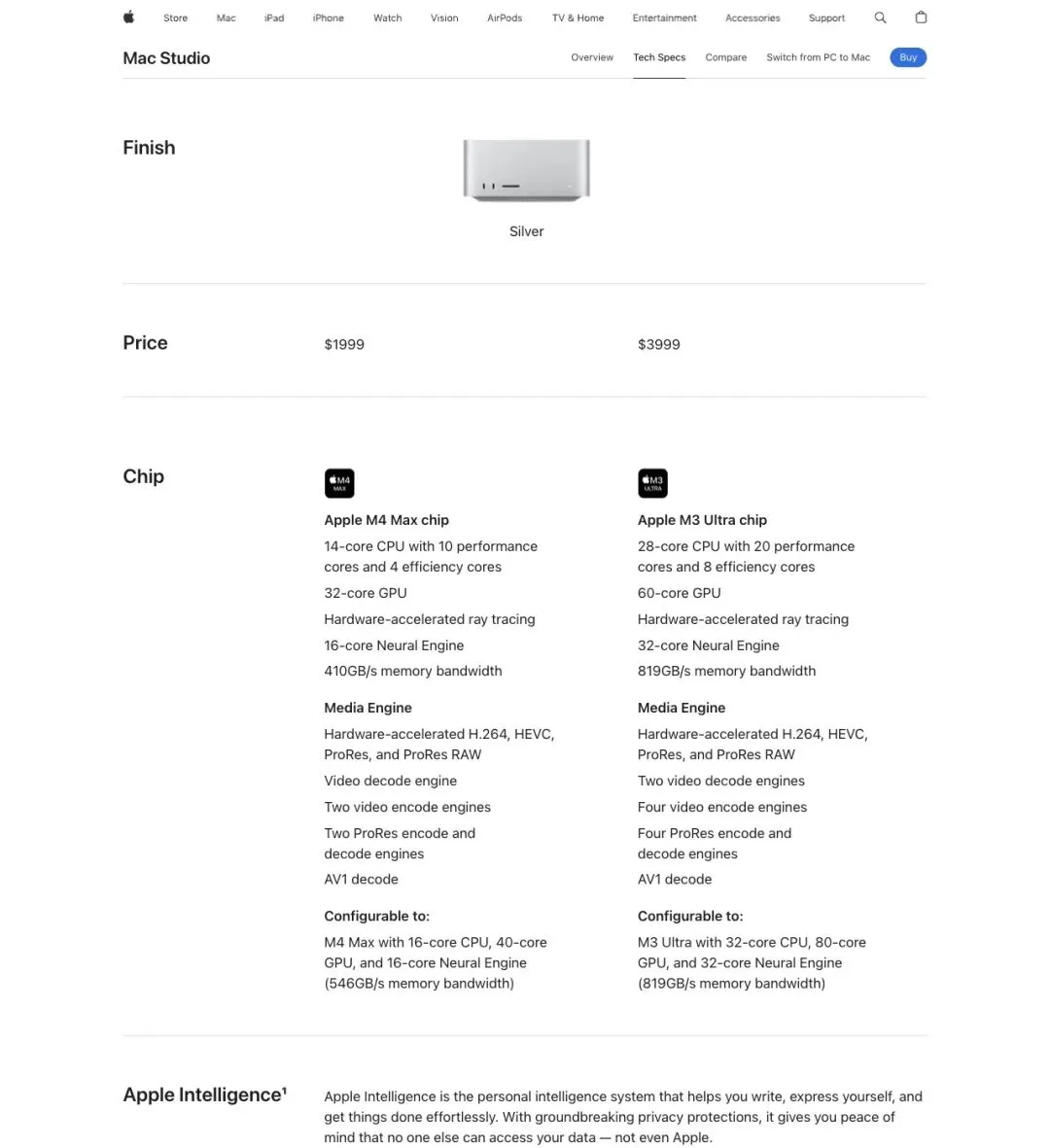
Apple 官方规格页显示,M4 Max 版本起价 $1999,M3 Ultra 版本起价 $3999。顶配 M3 Ultra 的内存带宽可以拉到819GB/s,GPU 最多 80 核。
▲ Apple 官方 Mac Studio 技术规格页,M4 Max 起价 $1999,M3 Ultra 起价 $3999
统一内存架构意味着 CPU 和 GPU 共享同一块内存池,不需要像 NVIDIA 显卡那样在主存和显存之间来回搬运数据。对大模型来说,你可以把一个 70B 甚至更大的模型整个装进内存,不用做量化阉割,不用做模型切分。
再加上 Apple 自己推出的 MLX 框架——专门为 Apple Silicon 设计的机器学习数组框架,直接利用统一内存优势,数组对象在共享内存中操作,省去了设备间的数据拷贝。
▲ MLX 是 Apple 官方推出的机器学习框架,专为 Apple Silicon 的统一内存架构设计
整机安静、功耗低、不用折腾散热和驱动,摆在桌上就能跑大模型。
这些优势都是实打实的。
但问题在于:很多人把"能装下大模型"等同于"能稳定跑生产级推理"。这两件事之间,隔着一道巨大的鸿沟。
生产级推理到底要什么?
当你的场景从"本地聊天玩一玩"变成"24/7 agent 工具调用服务"的时候,瓶颈就完全变了。
模型装进内存只是起点。后面还有一长串硬指标:
- 吞吐量(tokens/s)
:多个请求同时进来,系统能不能快速出结果? - 首 token 延迟(TTFT)和 prefill
:agent 做工具调用时,每次调用都要处理长上下文的 prefill,延迟会累积到令人崩溃 - KV cache 管理
:长对话、多轮工具调用、大上下文窗口,KV cache 的内存占用和调度效率直接决定系统能不能撑住 - 并发和批处理
:tensor parallel、pipeline parallel、continuous batching,NVIDIA/CUDA 生态花了几年打磨出来的核心能力 - 部署和运维
:容器化、K8s 编排、监控告警、故障自动恢复、模型热切换——整套生产体系都围绕 CUDA/NVIDIA 构建
有开发者在回复中追问:为什么 24/7 tool calling 糟糕?Mass 给了一个关键判断:
"prefill is a big problem."
「prefill 是个大问题。」
当你的 agent 每隔几秒就带着长上下文做一次工具调用,每次都要重新处理 prefill,累积的延迟会把整个工作流拖垮。CUDA 生态里,vLLM 和 SGLang 已经有了 prefix caching、chunked prefill、continuous batching 等优化手段。Mac 上?这些优化路径要么缺失,要么还在实验阶段。
"No vLLM、No SGLang"——方向对了,话说过头了
原帖中争议最大的断言:"No CUDA = no vLLM, no SGLang, no tensor parallel。"
这个判断方向没问题,但措辞过于绝对。
vLLM 官方文档在 Apple Silicon 页面明确写道:
"vLLM has experimental support for macOS with Apple Silicon. For now, users must build from source to natively run on macOS."
「vLLM 对 macOS Apple Silicon 提供实验性支持,目前用户必须从源码构建才能在 macOS 上原生运行。」
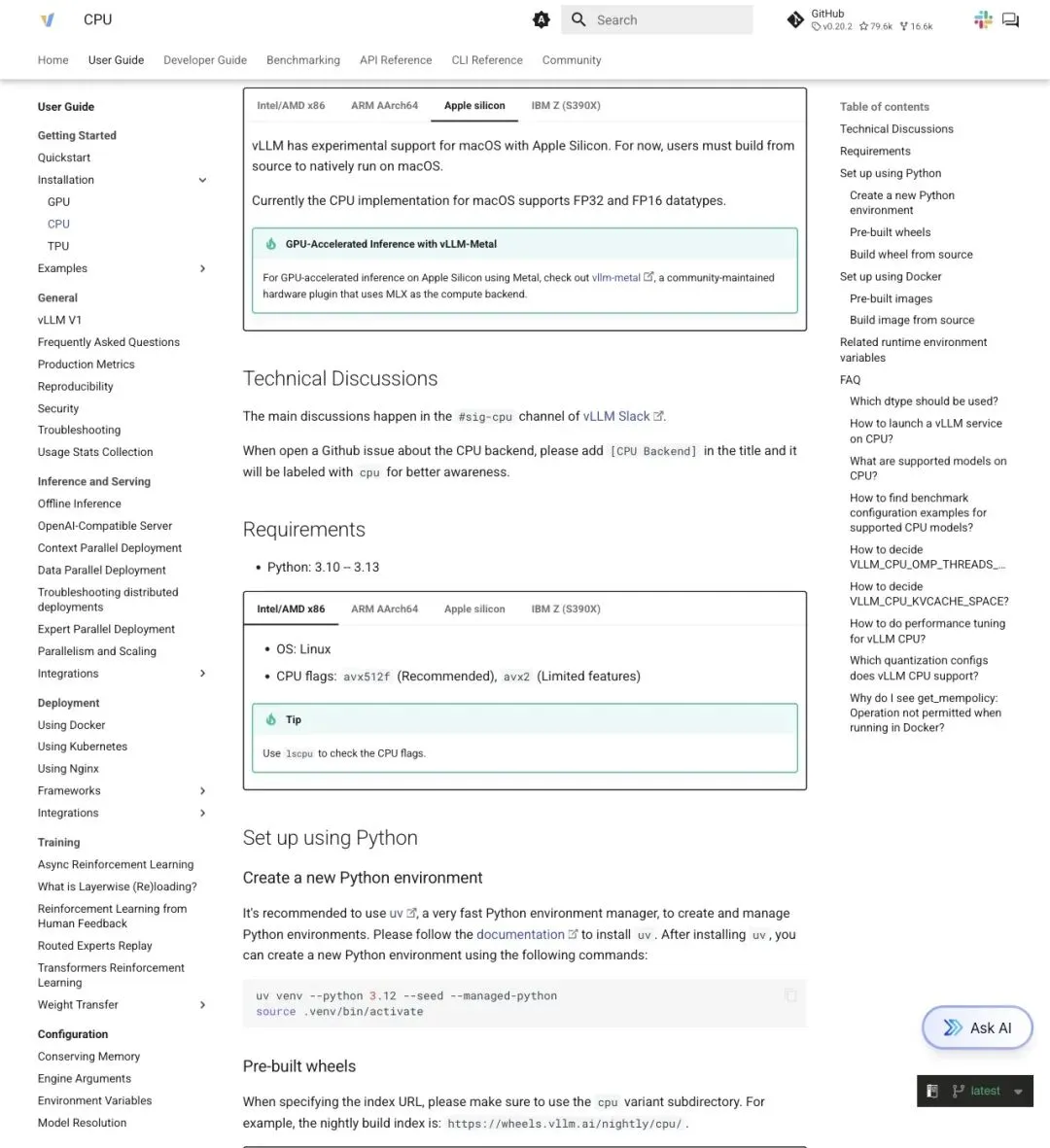
▲ vLLM 官方文档显示 Apple Silicon 有实验性 CPU 支持,GPU 加速需要社区维护的 vllm-metal 插件
关键词:experimental、build from source。路线存在,但和 CUDA 平台那种 `pip install vllm` 直接搞定、Docker 镜像拉起来就跑、生产环境无数人踩过坑的成熟度比,差距肉眼可见。
SGLang 的默认安装页面开门见山:
"This page primarily applies to common NVIDIA GPU platforms."
「该页面主要适用于常见 NVIDIA GPU 平台。」
▲ SGLang 默认安装文档明确围绕 NVIDIA GPU 和 CUDA 环境
Docker 示例用 `--gpus all`,Quick Fixes 第一条就在解决 CUDA_HOME 环境变量。整个默认路径就是为 NVIDIA/CUDA 设计的。
但 SGLang确实有 Apple Silicon with Metal 的官方文档页面:
"This document describes how run SGLang on Apple Silicon using Metal (MLX)."
「该文档说明如何用 Metal(MLX)在 Apple Silicon 上运行 SGLang。」
▲ SGLang 有独立的 Apple Silicon with Metal 文档,通过 MLX backend 启动服务
启动方式是 `SGLANG_USE_MLX=1 python -m sglang.launch_server`,需要从源码构建并手动指定参数。
所以实际情况是什么?
主流生产推理工具链的文档、Docker 镜像、调优经验和运维路径,仍然以 NVIDIA/CUDA 为核心。Mac 路线存在,但多处仍停留在 experimental、source build、community plugin 或 MLX-specific 的阶段。
你能在 Mac Studio 上跑 vLLM 和 SGLang 吗?技术上可以。你能把它当成和 CUDA GPU server 同等可靠的生产部署路径吗?还差得远。
评论区分成了哪几派?
回复区的争论很有代表性。
同意派的核心论点是性价比和生态。有人直言,花同样的钱组一台 RTX/CUDA 机器,跑现代 inference stack 只会更快。当工作负载进入服务化、并发、工具调用、长上下文的领域,生态兼容性和工作流完整度比单纯的内存容量更关键。
反对派认为这个批评"partly fair but one-sided"(部分正确但片面)。Mac Studio 本来就不是 GPU 集群的替代品,它更像一台本地开发 + 私有推理机。低功耗、统一内存、MLX,这些特性对某些 24/7 单机个人工作流刚好够用。
@defilan 给了一个更实际的方案:把 Mac Studio 当成异构 K8s 集群的一个节点。Mac 处理统一内存友好的本地任务,CUDA 机器处理吞吐密集型推理。按瓶颈分工就好。
还有人提了一个更尖锐的视角:
陷阱的本质,在于把"local AI"当成了一个统一的工作负载。CUDA 优化过的训练/推理和私有的、偶发的、本地工具调用,根本就是两种截然不同的场景。买错机器的人,往往是因为没搞清楚自己的瓶颈到底在哪。
买还是不买?先问三个问题
你的瓶颈是"装得下"还是"跑得快"?
如果你是个人开发者,想在本地跑一个 70B 的模型做研究、写代码、测试 prompt,不需要服务多人——Mac Studio 的统一内存是真正的优势。一台安静的桌面机器,不用折腾驱动和散热,装好 Ollama 或 MLX-LM 就能用。
你需要服务化吗?
一旦你需要开一个 OpenAI-compatible API 端点,让多个 agent 同时调用,需要处理并发请求、管理 KV cache、做 continuous batching——CUDA 生态的优势就是压倒性的。vLLM、SGLang、Ray、TGI,整套工具链都围绕 NVIDIA GPU 打磨。
你的运维体系是什么?
如果你的团队已经围绕 K8s、Docker、NVIDIA 容器镜像建立了部署和监控体系,硬塞一台 Mac Studio 进去只会增加维护成本。但如果你是独立开发者,家里摆一台安静省电的 Mac Studio 跑个本地模型,反而是最省心的选择。
回到那个保时捷比喻
Mass 说 Mac Studio 像一辆限速 100 公里的保时捷。比喻足够刺激,但不够精确。
它更像一辆越野能力极强的 SUV,你偏要拿它去跑 F1。
越野场景里,它的通过性、舒适性、综合能力确实强。赛道上,专业赛车会把它甩开几条街。
Mac Studio 的"越野场景":本地隐私、个人研究、Apple 生态开发、低并发大模型体验、安静省电的长时间驻留推理。
Mac Studio 的"F1 赛道":多用户 API 服务、高并发 agent 队列、需要 tensor parallel 横向扩展、成熟的 CUDA/vLLM/SGLang/Ray/K8s 生态。
本地 AI 最大的坑,往往出在硬件选型之外。买机器之前,先回答一个问题:你要的是"装得下",还是"跑得好"?
— END —
