 夜雨聆风
夜雨聆风# AI Agent 入门第十二课:上下文工程——给 AI 喂什么、怎么喂,决定了它有多聪明
「我以为写好 Prompt 就够了,直到 Agent 在第15轮对话后完全忘了它在干什么……」
那次我在测一个旅行助手 Agent,前面聊得挺顺,到后来它突然开始答非所问,我说"帮我查一下有没有更便宜的选择",它开始跟我讲背包怎么收纳。我盯着屏幕愣了三秒,心想:我的 Prompt 写得明明挺好的啊?
后来才搞明白,Prompt 写好只是第一步,真正让 Agent 保持"清醒"的,是一门叫 Context Engineering(上下文工程) 的事儿。今天第12课,咱们就来聊聊这个。

Prompt Engineering 和 Context Engineering,差在哪?
打个比方。
Prompt Engineering 是什么?是你在员工入职第一天,给他写了一份漂亮的工作说明书:职责是什么、怎么汇报、注意事项是什么。写好了,交出去,完事。
Context Engineering 是什么?是在整个工作过程中,你实时给这个员工补充信息——"客户刚发来新需求"、"之前那份报告作废了"、"这个工具现在能用了"——同时还要把他桌上堆积的旧文件收回去,免得他被淹没。
简单说:PE 是静态的,一次性的;CE 是动态的,全程管理信息流的。
你写一次好 Prompt,Agent 开始工作得很顺。但任务跑起来之后,信息在不断涌入、积累、过期、冲突——这时候光靠那份说明书已经不够了。上下文工程,就是在管这整个过程。
五种上下文类型,先认识一下
Agent 的"脑子"里,其实装着好几种不同性质的信息。我整理成一张表,一眼看清楚:
| 类型 | 是什么 | 典型陷阱 |
|---|---|---|
| Instructions(指令) | 系统提示、规则、few-shot 示例 | 写太多规则反而互相打架 |
| Knowledge(知识) | RAG 检索结果、长期记忆 | 检索到过期或不相关的内容 |
| Tools(工具) | 可调用的函数和它的返回结果 | 工具太多,模型不知道该用哪个 |
| Conversation History(对话历史) | 多轮对话记录 | 会越来越长,最后把窗口塞满 |
| User Preferences(用户偏好) | 从历史交互里学到的习惯 | 习惯记错了,越用越偏 |
这五类信息,每一类都有自己的生命周期和风险点。上下文工程要管的,就是这五类信息在 Agent 运行全程里的进进出出。
三步规划:怎么设计上下文流水线?
理论说完,来点实操。上下文工程有个三步走的规划思路:
第一步,定义结果:这个 Agent 最终要交付什么? 第二步,映射上下文:完成这个结果,需要哪些信息、从哪来、什么时候用? 第三步,创建流水线:把信息的流入、处理、清理串联成一套机制。拿"帮我订机票"这个场景走一遍:
- 结果:订到一张符合要求的机票并出票
- 需要的上下文:用户出行日期(偏好)、目的地(当前对话)、预算范围(偏好/当前)、实时票价(工具调用结果)、过往订单(长期记忆)
- 流水线:先读用户偏好→调搜索工具→把结果塞入上下文→用户确认后调支付工具→清除临时搜索结果
这三步做完,Agent 知道自己该看什么、不该看什么,才不会跑着跑着迷路。
六大实操策略
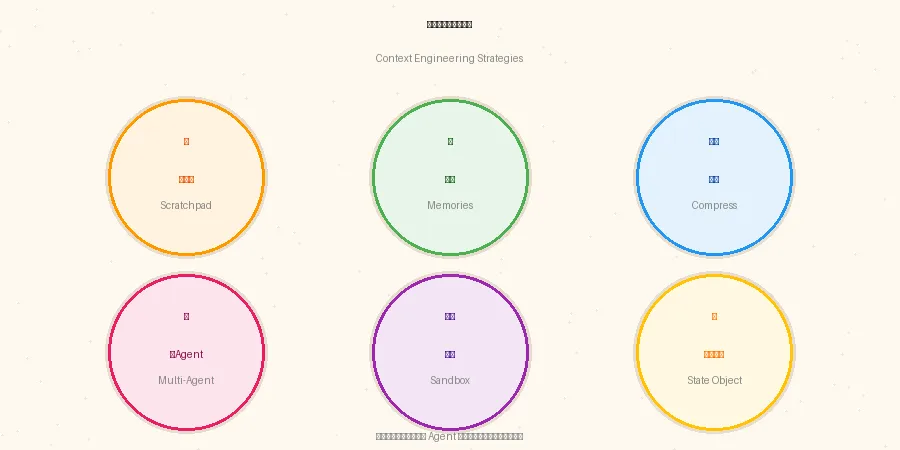
知道了要管什么,再来看怎么管。
Scratchpad(草稿本),是我觉得最被低估的一个。简单说,就是给 Agent 开辟一块临时的"工作草稿区",存在上下文窗口里,用来记中间推理过程——"我目前查到了A,还缺B,下一步去找C"。Agent 不用把所有想法全塞进正式回复,草稿本帮它"想清楚再说"。很多 Agent 回答逻辑混乱,就是因为没有这块空间。 Compressing Context(压缩上下文),是应对"对话越来越长"的核心手段。策略很直接:定期对历史对话做摘要,把"用户聊了什么"浓缩成几句关键结论,然后把原始的长篇对话裁掉。就像你和同事开了两小时会,最后留的是会议纪要,不是录音全文。压缩做得好,Agent 记住的东西反而更准。 Multi-Agent Systems(多 Agent 协作),是处理复杂任务的大杀器。核心逻辑:每个 Agent 维护自己独立的上下文窗口,只管自己那一块,互相之间传递结果而不是共享全部信息。这样每个 Agent 的"脑子"都是干净的,不会被其他任务的噪音干扰。另外三个策略简单提一下:Memories(记忆存储) 是跨会话的持久化,让 Agent 记住"你上次说过不喜欢红眼航班";Sandbox Environments(沙箱) 是让 Agent 在隔离环境里跑代码,只把关键结果读回来,不污染主上下文;Runtime State Objects(运行时状态容器) 是给复杂任务维护一个结构化的状态对象,比如"当前步骤=第3步,已确认信息=出发地+日期,待确认=座位偏好"。
四大失效模式——这才是重头戏
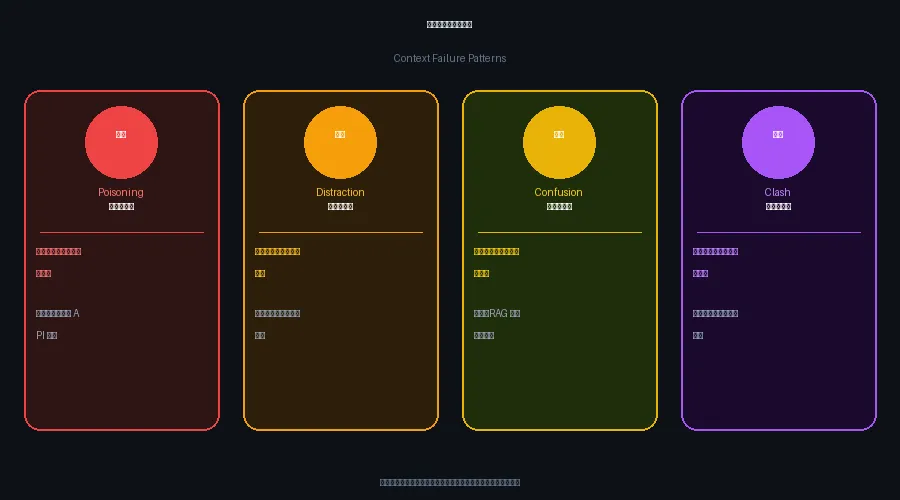
好,以上都是讲"怎么做好"。现在来说最有意思的部分:哪些情况会把上下文搞坏。我继续用旅行订票的场景来举例,这样更直观。
1. Context Poisoning(上下文污染)
症状:AI 相信了一条假信息,然后用这条假信息一路干下去。 场景:你在搜票的时候,Agent 调了航班查询工具,结果那个 API 有 bug,返回了一条根本不存在的航班——「深圳→巴黎,明天直飞,¥2800」。Agent 把这条信息写进了上下文,然后开始帮你预订。你说"确认吧",它一直在尝试预订一个幻觉航班,还一直说"正在处理,请稍候"。 解法:来源要验证。工具返回的结果在写入上下文之前,要有校验机制,或者至少标注置信度。幻觉信息一旦污染上下文,后续所有推理都建立在沙滩上。2. Context Distraction(上下文分心)
症状:上下文里装了太多不相关的信息,模型被带跑偏了。 场景:你和 Agent 聊了很久,聊到了你上次去欧洲的经历、你朋友推荐的民宿、你对法式早餐的迷恋……然后你问"帮我找最便宜的机票"。Agent 回复了一大段……巴黎旅行攻略和推荐背包品牌。它没有忘记你的问题,它只是被上下文里的旅行故事带走了。
解法:上下文要"按需装载",不相关的历史信息要裁剪或压缩,不能什么都留着。任务明确的时候,把无关内容清出去。3. Context Confusion(上下文混乱)
症状:工具太多、信息太杂,模型搞不清楚该用什么、该看什么。 场景:你给旅行助手接了十几个工具:查机票、查火车、查巴士、查租车、查酒店、查天气、查签证……你问"从市区去戴高乐机场怎么走",Agent 想了很久,然后给你查了一条"巴黎市内航班"——因为它看到"航班"工具就用了,没搞清楚你说的是地面交通。 解法:工具要分组、要裁剪,Agent 在特定任务阶段只暴露相关工具。工具越多不是越好,上下文里的工具清单本身就是噪音。4. Context Clash(上下文冲突)
症状:上下文里存在两条互相矛盾的指令,Agent 不知道听哪个。 场景:你一开始说"帮我订经济舱,越便宜越好",Agent 记住了。后来你说"这次出差公司报销,订商务舱吧",Agent 也记住了。现在两条指令都在上下文里,它真的不知道该订哪个——有时候它订经济舱,你问它为什么,它说"因为您之前说要便宜的";有时候又订了商务舱,逻辑同样"成立"。 解法:新指令要显式覆盖旧指令,系统要有机制检测冲突并请用户确认,而不是两条规则同时留着、随机生效。这四种失效模式,说白了,都是信息管理的问题,不是模型本身变笨了。喂错信息、喂杂信息、喂冲突信息,再聪明的模型也会乱。
上下文工程 vs RAG,别搞混了
最后补充一个常见的概念混淆:RAG 和 Context Engineering 是什么关系?
RAG(检索增强生成)你可能听说过——就是 AI 回答问题之前,先去检索相关文档,把检索结果塞进上下文里,再生成回答。这是解决"模型不知道最新信息"问题的主流方案。
但 RAG 只是 Context Engineering 的一个工具,专门负责处理五类上下文里的 Knowledge(知识) 这一类。它解决的是"从哪里取知识、怎么取"的问题。
Context Engineering 是更宏观的框架,管理的是所有五类上下文的全生命周期——不只是知识,还有指令、工具、对话历史、用户偏好。RAG 做得再好,其他四类上下文搞砸了,Agent 照样出问题。
简单说:RAG 是一块零件,CE 是整台发动机。
课后思考题
- 你在构建 Agent 时,有没有遇到某个工具越加越多、模型越来越乱的情况?
- 你遇到过 Context Distraction 吗?当时的 Agent 表现是什么?
- 如果让你为一个旅行助手 Agent 设计上下文流水线,你会怎么规划五类上下文的来源?
AI 的世界每天都比昨天更陌生一点,但也更有意思一点。我们明天见。
📌 第13课预告:Agent 的记忆系统——从「每次从零开始」到「记得你说过的每一件事」,期待的扣1。
