 夜雨聆风
夜雨聆风AI时代,领域专有知识更加珍贵且值钱
去年我们团队花了三个月搭了一套广告投放的Agent系统。16个阶段的状态机,40多个Skill,Prompt调了几百个版本。系统跑起来很漂亮——从需求识别、策略生成、到投放执行、效果追踪,全自动化。团队很兴奋,觉得找到了AI工程的正确打开方式。
半年后GPT-5出来了。模型自己就能做多步规划,我们的16阶段状态机一下子显得笨拙。框架也在快速迭代,Langchain的API又改了一轮。我们发现,那套精心设计的工作流,大部分要推倒重来。
但有个东西完全没浪费:我们在实战中积累的业务知识——"高峰期并发量是平时50倍,这时候预算扣减必须用分布式锁+Redis Lua脚本保证原子性"、"某类广告主的ROI预期是行业均值的1.8倍,否则会流失"、"审核策略在周五下午必须从严,因为周末人工审核力量不足"。这些写在知识库里的条目,不管工作流怎么变,Agent怎么升级,一个字都没过时。
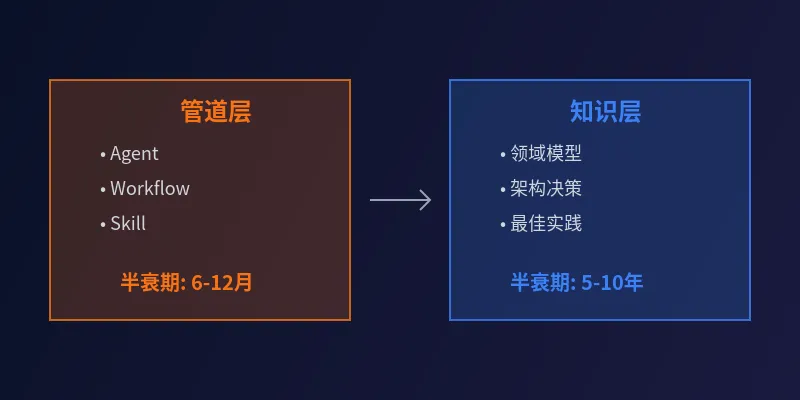
这件事让我想明白一个道理:在AI时代,工作流是管道,知识才是流过管道的活水。管道会换代,但水的价值永恒。
行业在追逐什么,又在忽视什么
2026年的AI工程圈很热闹。Harness Engineering成了新的关键词,大家在讨论怎么编排Agent、怎么设计多Agent协同、怎么用MCP打通工具链。技术社区里到处都是"我的工作流有12层决策树"、"我们用DAG管理任务依赖"、"我们实现了动态Prompt路由"。
这些都很重要。但我发现一个现象:大家都在研究管道怎么搭——模型选多大的、工作流设计多复杂、Agent分几层、用什么框架。很少有人问:管道里流的是什么?
答案是知识。业务逻辑、领域规则、踩过的坑、验证过的最佳实践——这些才是让Agent真正work的东西。一个空有复杂编排、但不知道业务规则的Agent,就像一台发动机很强但没装导航的车,跑得快但不知道往哪跑。
如腾讯技术工程团队有篇文章《Harness不是目的,知识才是护城河》说得很直接:"工作流只是管道,知识才是流过管道的活水"。Harness Engineering的三大支柱——上下文工程、架构约束、持续治理——每一个背后都是知识管理。没有结构化的业务知识,上下文工程拿什么注入?没有验证过的架构决策记录,约束从哪来?没有知识的版本管理和衰减机制,持续治理治什么?
德鲁克在《后资本主义社会》里说过:"在知识社会中,基本经济资源不再是资本、自然资源或劳动力,而是知识。"这个判断放到AI时代不仅没过时,反而被强化了——AI让调用知识的效率指数级提升,拥有独特知识的组织获得了更大的杠杆。
人话说明:现在大家都在比谁的工作流更复杂,但真正决定系统能不能落地的,是你有没有把业务知识沉淀下来。
为什么知识比工作流更有价值
我更倾向这样判断:工作流的半衰期是6-12个月,知识的半衰期是5-10年。这不是我随口说的——Zimt.ai在《The Vertical Specialization Moat》研究中用硬数据证明了同样的道理:垂直领域的专业化公司,定价溢价30-50%,成交速度快40-60%,获客成本低46%。世界银行跨趀13个行业、40个国家、15年的研究显示,垂直专业化每提升10%,生产力提升1.7%。为什么?因为垂直知识是不可复制的。
工作流为什么衰减这么快?因为它高度依赖当前的技术栈和模型能力。三年前大家用串行Prompt链,两年前流行并行调用+ReAct,去年是DAG+状态机,今年开始有团队尝试纯自然语言编排。每次模型能力跃迁,最佳实践就变一次。GPT-4时代你需要精心设计16个阶段,到了GPT-5可能5个阶段就够了。Mythos这种模型已经能自主发现系统漏洞、动态调整策略,未来模型的规划能力可能会进一步内化——到那时候,今天的工作流设计会显得多余。
但知识不一样。"广告预算在高并发下会超扣,必须用分布式锁"——这条经验,不管你用的是16阶段工作流还是5阶段,不管是GPT-4还是GPT-5,都有价值。"这类客户的流失预警信号是连续三天ROI低于阈值"——这是业务规律,跟技术栈无关。
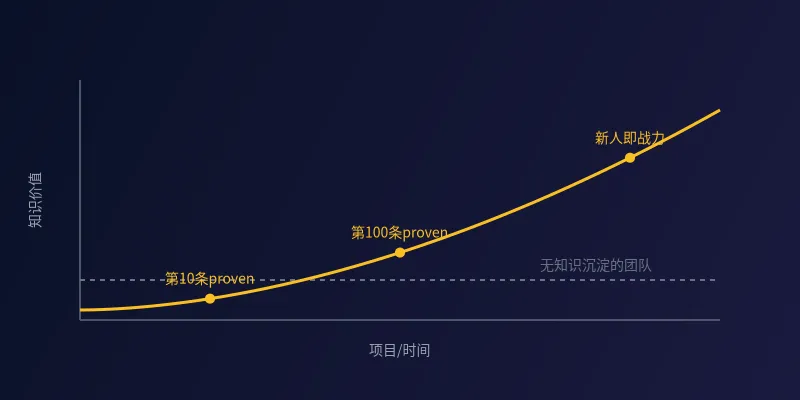
知识还有个特点:复利效应。每沉淀一条proven级别的知识,所有后续项目都受益。用个公式比喻:知识价值 = 初始知识 × (1 + 复用率)^项目数。第一个项目你踩坑总结了10条pitfall,第二个项目不用再踩、还能新增5条,第三个项目站在前两个肩膀上……到第十个项目时,新人入职第一天就能看到团队几年积累的上百条proven知识,直接站在巨人肩膀上开始干活。
我们团队有个真实案例。去年一个刚入职的应届生,接手一个风控系统的Agent开发。他第一天从知识库里读到一条proven级的记录:"XX场景下不要用模型直接输出bool判断,准确率不稳定,必须走规则引擎+模型打分的混合模式"。这条经验是两年前另一个项目踩了三个月坑才总结出来的。这个应届生直接跳过了这个坑,第一版方案就是对的。这就是知识复利——前人的学费,后人不用再交。
人话说明:工作流是"交通工具",知识是"目的地的地图"。车会换代——从自行车到汽车到飞机,但地图(对地形的理解)只会越画越精确。模型和框架会进化,业务规律不会过期。
知识的三种层次——不是所有知识都值得沉淀

不是所有信息都叫知识。我把知识分三个层次:
散点型知识:孤立的事实。"Redis默认端口是6379"、"JWT token过期时间是24小时"。这类知识价值很低,因为通用大模型已经知道了,或者随便搜一下就有。你不需要专门沉淀这些,浪费空间。
因果型知识:带推理链的经验。"用Redis+Lua脚本保证扣减原子性,因为单纯的get-check-set在并发下会出现竞态条件"。这类知识有一定价值,但需要场景化。脱离了具体业务场景,这个知识的适用性就打折扣。
时空型知识:特定场景+时间窗口下的规律。"在我们的广告系统里,周五下午到周日晚上这个时间窗口,人工审核团队只有平时的30%,所以这个时段的自动化审核策略必须从严,阈值要提高15%,否则周末会积压大量待审内容导致周一上午的投诉高峰"。这是最高价值的知识——它不仅告诉你做什么(提高阈值)、为什么(人力不足),还告诉你什么时候做(周五下午开始)、做多少(提高15%)、不做会怎样(周一投诉高峰)。
越高阶的知识,越难从通用模型获得,越依赖一线团队的实战积累。芯加哥大学发表在《Journal of Political Economy》上的论文《Artificial Intelligence in the Knowledge Economy》正式论证了这个判断:AI时代,通用知识(codified knowledge)的价值急剧下降,因为AI可以轻松复制和传播;而隐性知识(tacit knowledge)和领域专有知识(domain-specific knowledge)的价值急剧上升。GPT-5知道Redis可以保证原子性,但它不知道"你们公司的广告系统在周五下午应该调整审核策略"。这就是为什么"用更大的模型"替代不了知识沉淀——模型知道通用知识,不知道你的业务特有知识。
Karpathy在他的知识管理方法论里提到:知识的价值不在于页数本身,而在于页面之间的关联。一条时空型知识,往往会关联到好几条因果型知识(为什么这么做)、引用若干个散点型知识(具体参数)、并且被多个项目反复验证。这种关联网络,才是真正的知识资产。
人话说明:别把百科全书式的信息当知识。真正值得沉淀的,是"只有你的团队踩过坑才知道"的那部分。那才是护城河。
企业知识生命周期管理——怎么让知识产生真正的复利
说句直接的:大部分公司的知识库都是"信息坟墓"——写的时候很认真,写完没人看,过半年就过时了,但也没人删。这不叫知识管理,这叫知识堆积。
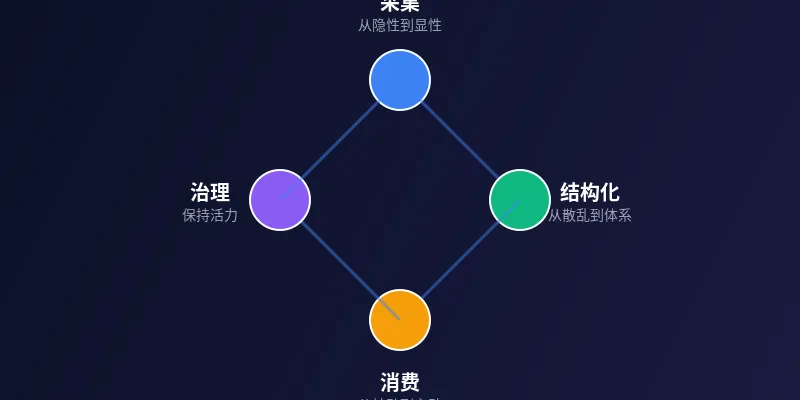
真正的知识管理是一个闭环的生命周期:采集→结构化→消费→治理→再采集。每个阶段都有门道。
阶段1:知识采集——从隐性到显性
团队里最值钱的知识,80%在人脑子里。两个高级工程师吃饭聊天:"哎,上次那个问题你还记得吗?后来发现是XX导致的,我们改成XX就好了。"这种对话,包含的可能是一个价值百万的pitfall。但如果不记录下来,等这俩人离职,知识就消失了。
知识采集的来源:
代码Review:好的CR不只是挑毛病,还会沉淀"为什么这么写"的决策上下文 架构决策记录(ADR):每次重大技术选型,都应该有一份ADR——背景、考虑过的方案、选择的理由、预期的tradeoff 故障复盘:不是写"服务器挂了→重启→好了",而是提取可被Agent查询的pitfall条目——"XX场景下YY配置会导致ZZ问题,解决方案是AA,预防措施是BB" 项目总结:不是写PPT,是提取结构化知识——哪些决策对了、哪些错了、下次怎么做 日常沟通:站会、1on1、技术分享里的经验——可以用AI辅助转写+提取关键信息
野中郁次郎和竹内弘高在1995年提出的SECI模型,说的就是这个事——知识创造的核心是隐性知识和显性知识之间的转化循环:社会化(师徒传承)→外化(经验文档化)→组合化(知识库整合)→内化(学习后变成直觉)。AI时代最大的挑战就在"外化"——把团队脑子里的隐性知识,变成可被AI消费的显性知识。采集的关键是降低记录门槛。如果每次沉淀知识都要打开wiki、想标题、排版、找分类,大家就不会做。理想状态是:知识沉淀成为工作流的副产品。比如我们团队现在的做法——Agent跑完任务后,自动从执行日志里提取潜在的知识条目,生成draft级记录,工程师review一下点个确认就行。
阶段2:知识结构化——从散乱到体系
采集来的知识是散的,必须结构化才能被高效消费。
分层架构(参考腾讯技术工程团队的五层模型):
个人偏好:某个工程师喜欢用的代码风格、快捷键配置——这层不需要团队共享 团队约定:代码规范、CR checklist、协作流程——团队内有效 技术知识:框架用法、语言特性、通用的技术pitfall——可以跨团队复用 业务知识:业务规则、领域模型、行业Know-how——公司级资产 项目知识:某个具体项目的上下文、决策、踩坑记录——项目维度管理,精华可以提升到业务知识层
分类体系:
model:领域模型、概念定义("什么是有效点击") decision:架构决策、技术选型("为什么用Redis而不是Memcached") guideline:最佳实践、操作指南("如何配置XX功能") pitfall:踩过的坑、已知问题("XX场景下不要YY") process:流程规范、检查清单("上线前的12项检查")
成熟度标记:
draft:新记录的、未验证的 verified:至少一个项目验证过有效的 proven:多个项目反复验证、成为团队共识的
关联建设:知识之间建立引用关系。一条guideline会引用若干个pitfall("按这个做可以避免那些坑"),一个decision会引用多个model("基于XX概念,我们选择YY方案")。这种关联网络,让知识从"信息孤岛"变成"知识图谱"。Karpathy说的对:复利不在于页数,在于页面之间的关联。
阶段3:知识消费——从被动存储到主动服务
传统知识库的最大问题:"存而不用"。文档写完了,躺在wiki里,没人看。三个月后大家又在群里问同样的问题。
AI时代可以变个玩法:让知识主动注入工作流。
具体怎么做?Agent在关键决策点,按需查询知识库。举个例子:
Agent准备生成广告投放策略 ↓ 触发知识查询:"广告投放"+"高并发"+"预算控制" ↓ 知识库返回三级索引: - 全景目录:12条相关记录(只有标题和分类) - 分类清单:其中4条proven级、6条verified级(多了摘要) - 完整条目:点进去才看详情 ↓ Agent选择加载2条proven级的pitfall:"预算扣减的原子性问题"+"高峰期的流控策略" ↓ 基于这些知识,生成投放策略 ↓ 引用追踪:这两条知识的引用计数+1,信任度提升这种三级渐进式索引很关键。如果一次把知识库全文都塞给Agent,context会爆;如果完全不给,Agent就是瞎子。渐进式索引让Agent先看目录、再看摘要、最后按需加载全文——既精准又不浪费token。
引用追踪也很重要。被Agent引用的知识,会自动累积信任度。一条draft级知识被5个Agent成功引用,自动升级为verified;被20个项目验证,升级为proven。这是自动的质量评估机制。
知识消费的ROI很容易算:一条proven知识如果被10个项目复用,就是10倍回报。如果它帮每个项目避免了一周的踩坑时间,那就是节约了10人周。这比开发一个复杂工作流的回报确定得多。
阶段4:知识治理——让知识库永葆活力
知识会过期。三年前"微服务一定要用Docker"是最佳实践,现在可能已经不适用了。过期的知识比没有知识更危险——它会误导Agent做出错误决策。
自动衰减机制:
proven级知识,如果12个月没被引用,自动降级为verified(说明可能不太适用了) verified级知识,如果6个月没被引用,降级为draft draft级知识,如果持续未被引用,归档(不删除,但不会被主动检索到)
这个机制让知识库保持活力——常用的知识自动浮到顶层,不常用的自动沉底。
Lint机制:定期跑一遍知识库检查:
矛盾检测:有没有两条proven级知识互相冲突? 重复检测:有没有语义相似的条目可以合并? 过时检测:引用的技术栈版本是不是还在用? 孤儿检测:有没有从来没被引用过的条目?
版本管理:知识库用Git管理,每次变更都可追溯、可回滚。如果发现某条知识被错误修改了,可以快速恢复。
我认为,没有治理的知识库,半衰期只有一年。有治理的知识库,可以用十年。
让知识流动的具体形式——不同场景的最佳载体

知识不是只能放在wiki里。不同场景,有不同的最佳载体。
团队知识:独立的Git仓库 + Markdown。为什么不用wiki?因为Markdown可以版本管理、可以Git协作、可以被AI直接消费(不需要爬虫或API)。我们团队的知识库就是一个Git仓库,每个人都可以提PR,CI会自动跑Lint检查格式和引用。
项目知识:随项目代码走的docs/knowledge/目录。项目相关的决策、踩坑、最佳实践,就放在项目仓库里。好处是:知识和代码同步演进,查代码的时候顺手就能看到上下文。精华的部分,可以通过PR提升到团队知识库。
领域知识:按业务域组织的wiki + 实体关系图 + 决策树。比如广告领域的知识,用一个专门的空间管理,里面有概念定义(什么是CTR、CVR)、实体关系(广告主-广告计划-广告创意)、决策树(不同场景下的投放策略)。
架构决策记录(ADR):每次重大技术选型,写一份ADR。格式很简单:背景(Context)、考虑过的方案(Options)、决策(Decision)、理由(Rationale)、后果(Consequences)。这是未来最有价值的知识形式——它回答了"为什么这么做",这比"怎么做"更重要。半年后换人接手,看ADR就能理解当时的考量,不会轻易推翻。
故障复盘知识:从RCA(Root Cause Analysis)到可被Agent查询的pitfall条目。传统的故障报告写得很详细,但格式是给人看的,Agent不好用。我们的做法是:RCA报告正常写,同时提取结构化的pitfall条目——触发条件、根因、症状、解决方案、预防措施——存到知识库。下次Agent遇到类似症状,可以直接查到。
口头知识显性化:站会、1on1、技术分享里的经验,如果不记录下来就消失了。可以用AI辅助——会议录音转写,自动提取潜在的知识点,生成draft条目让相关人review。这大大降低了记录门槛。
对架构师和技术负责人的建议
坦白说,我觉得投资知识工程的回报,比投资工作流确定得多。这不只是我的判断——红杉资本(Sequoia Capital)的观点是:"随着AI模型的商品化,持久优势转移到那些深度嵌入真实工作流和受监管环境的公司。" a16z的AI+Healthcare投资论文更直白:"AI放大了被编码进去的一切理解。当这种理解不完整时,系统只会更快地放大错误。" Contrary Research的2024年数据显示,42%的企业AI项目被叫停——不是因为模型失败,而是因为没有嵌入到具体工作流中。McKinsey 2025年的报告也确认,88%的企业使用AI,但只有6%的企业获得了5%以上的EBIT影响。差距在哪?不在模型大小,在组织是否完成了知识的结构化、数字化、可被AI消费的转化。
工作流是概率性回报——可能半年就过时了,可能模型升级就不需要了。知识是确定性回报——只要是真实验证过的业务规律,就会长期有价值。
从今天开始可以做三件事:
建立团队ADR机制。每次技术选型、架构决策,都写一份ADR。不需要很长,一页纸就够。关键是记录"为什么"——背景是什么、考虑了哪些方案、为什么选这个、预期的tradeoff是什么。半年后回看,你会发现这些ADR比任何文档都有价值。
项目结束后做知识提取。不是写总结PPT(那是给领导看的),是提取可被AI复用的结构化知识。哪些决策对了、为什么对?哪些踩坑了、怎么避免?有哪些通用的pattern可以复用?把这些提取成model/decision/guideline/pitfall/process五类条目,存到知识库。一个三个月的项目,能提取出20-30条有价值的知识,就很不错了。
让知识消费成为工作流的一部分。Agent启动时,先查知识库,而不是从零推导。在关键决策点,注入相关的proven知识。执行完任务后,追踪哪些知识被引用了、哪些有效、哪些需要更新。让知识真正流动起来。
衡量标准也要变:不是"知识库有多少篇文档"(那只是vanity metric),而是"知识被复用了多少次"。一条被20个项目引用的proven知识,比100条没人看的文档有价值。
人话说明:别光顾着搭工作流了,花点时间沉淀知识。前者是消耗品,后者是资产。
权威共识:领域知识为什么值钱
上面是实践层面的分析。但"领域知识比工作流更重要"这件事,不只是我一个人的观点——从学术界到投资界到技术领袖,正在形成高度一致的共识。整理成表:
综合来看,不管是学术界的严谨论证、投资界的真金白银、还是技术领袖的亲身实践,结论都指向同一个方向:AI模型和工作流会商品化,领域专有知识是唯一不会被商品化的资产。谁拥有更深的领域知识、并且完成了知识的结构化和可被AI消费的转化,谁就拥有AI时代的绝对竞争优势。
结尾
模型会越来越强,Agent会越来越聪明,工作流会越来越自动化。但这些都是"管道"在变好。管道越好,里面流的知识就越有价值。
你可以花三个月搭一套很炫的16阶段工作流,半年后模型升级可能就要重构。但如果你花同样的时间,系统化地沉淀了100条proven级的业务知识——什么场景下怎么做、为什么这么做、不这么做会怎样——这些知识五年后依然有效,而且会随着团队的实践越积越多,产生复利。
你团队的护城河不是"搭了一个多复杂的工作流",而是"沉淀了多少别人没有的领域知识"。前者是技巧,后者是资产。工作流是一次性的投入,知识是复利性的资产。
这个判断,在AI越强的未来只会越正确。因为模型越强,工作流的通用部分就越会被内化到模型能力里——你不需要自己设计复杂编排,模型自己就会规划。到那时候,唯一的差异化就是:你有没有把你的业务知识,系统化地喂给AI。
从今天开始,把知识当资产管理吧。
补充说明
如果感觉内容不错,请您随手关注、点赞,转发,后续持续发布AI的产品,技术,解决方案,安全,合规,标准,白皮书,研报等
谢谢您!
