 夜雨聆风
夜雨聆风用AI做内容商业化,企业需要先理清三条链条
2026年,AI工具的能力跃升让越来越多企业开始将AI Agent接入内容生产与发布流程。效率提升是真实的,但有一个问题被普遍低估了:AI生成的内容直接用于商业发布,法律风险到底由谁来承担?
这篇文章不做恐慌式劝退,也从"要不要用AI"的层面跳出来,直接回答一个现实问题:如果你已经决定把AI深度嵌入内容商业化流程,哪些链路上需要提前把风险查清楚。
我们从大量实务判例中提炼出三条独立链路,对应三个今天就能启动的排查方向。顺着往下看,企业就知道自己该怎么办。
⛓️ AI商业化合规三链
2026年,AI能力迎来大爆发。无论是coding还是多模态,都实打实地对工作效率提升有着重大帮助。尤其年初OpenClaw的出现,让AI Agent的话题直接点爆了全网,周围到处在聊OpenClaw、Skill、MCP。
尽管有人图新鲜跟风,玩段时间就闲置了,但每一次技术迭代总会有一批先吃螃蟹的人。到现在,杭州已经有不少OPC(一人公司)凭借AI吃到了肉。
可事物总有两面性。AI提升效率不假,但AI生成的东西直接拿来商用真的可行吗?这是一个定下"依托AI运营公司"这个目标之前,必须要考虑的问题。
AI大模型的原理很简单,就是厂商拿大量数据训练,然后根据用户的输入做预测性输出。它不是真正"理解"了你的问题,只是"预测"你最可能想要的答案。训练数据在其中的重要性不言而喻,但我们今天不讨论厂商训练数据合不合规,只关心自己的事,即使用AI商业化会不会侵权,该怎么预防。
尽管2026年AI异常火爆,但AI已经诞生多年,这几年正好是相关司法案例密集出现的时间段。诸多判例已经明确AI商业化确实可能侵权。但别怕,写这篇文章不是劝你别用AI,而是告诉你该怎么用才安全,出了问题怎么应对。
我们分析了大量案例,把AI商业化的风险拆成三条独立且字数一致的链路,以及对应的三条解决方案。分别是输入的授权链、侵权的责任链,事后的证据链。
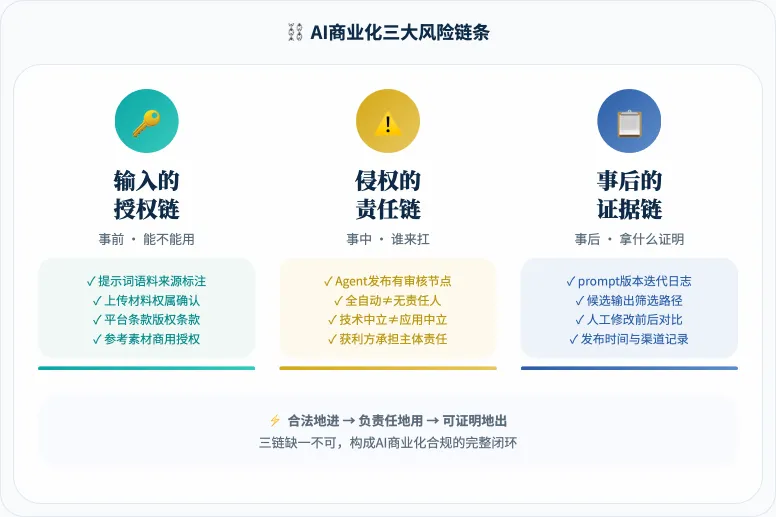
🔑 第一件事:输入的授权链
AI生成内容的前提是用户的输入,所以输入端非常重要,所以考虑AI生成内容商业化,首先要考虑的是输入端的内容。大模型厂商训练数据对普通用户来说就是个黑盒,用户不可能知道DeepSeek、豆包训练时用了什么素材。但每一次的输入都是可以控制和把握的。
📌 授权链的两个控制点
① 提示词和上传材料:提示词或材料中是否有来源标准、prompt里粘贴的内容是否需要脱敏,供AI参考的模态材料是否可商用或得到授权——虽然输入端侵权爆发的情况不多,但并不代表输入端的权利归属明确就可以被忽视,授权链条必须完整,合法的进,是合法的出的起点。
② 平台条款:厂商通常会在"内容版权"或"知识产权"那部分写明"不保证模型输出内容不侵犯第三方权利"——用户需要对自己的输入和输出负责。
⚖️ 典型判例:有人截取了某动画角色的二十多张图片,用平台的训练功能生成模型生成大量的图片进行传播,最后法院认定这个人侵害了复制权和信息网络传播权。而平台因为做了基本的审核和投诉处理,没有主观过错,不构成侵权。
💡 今天能做的第一件事
检查AI Agent或工作流涉及的每一个输入节点,其中的数据源有没有版权声明、上传到系统的参考素材有没有来源标注、prompt里有没有包含未获授权的第三方内容。再花点时间翻一下AI工具的条款,找到"内容版权"那一段,看看相关的规定,并针对性对未来AI输入层面做出调整。

⚠️ 第二件事:侵权的责任链
输入端的授权链理清了,不代表商用就安全了。即便输入端的授权没问题,但真出问题,别人不一定这么看。因为出了事如何划分责任还要取决于另一条链。
很多人觉得AI是DeepSeek的、Agent框架是开源的、工作流是自动跑的,每一步都不是我手动执行的,我输入的内容也没问题,出了事和我没关系。但实际情况是,用AI Agent每天自动生成内容发布到公司公众号,别人截图、取证、发函,告的只会是公司,而不是大模型或工作流公司。
平台不担责不是因为技术中立,而是责任优先落实到实际使用和发布内容的人身上。用户虽然不手动点"生成",但工作流是你设计的、Agent的任务是你配置的、内容发布到哪个渠道是你设定的,这些动作背后的决策者是用户,承担责任的主体也自然是用户。
⚖️ 典型判例:有一个案子中,某公司做了一款针对社交平台的"种草笔记一键生成"工具,广告语写着"符合平台调性""日更百篇"。后来被人起诉侵权,法院认定技术中立不等于应用中立。该公司用自己的产品对外交付内容、从中获利了,就不能躲在"技术只是工具"后面。这个裁判思路放到Agent场景里也一样——你的Agent以什么频率、什么渠道、什么主题对外发布内容,这些参数是你填的,不是你写的框架替你背锅。
💡 今天能做的第二件事
确认团队用Agent自动发布内容,是否存在完善的审核节点。当前工作流的编排中,有没有保留一个人工审核后再发布的环节。如果Agent从生成到发布是全自动的,那就是你的责任链上最薄弱的节点。
📋 第三件事:事后的证据链
前两件事解决的是"事前能不能用"和"出事谁扛"的问题。但很多问题出在事后,比如已经被投诉了、被索赔了、或者想证明AI Agent生成的内容是自己的创作成果。这时候你拿什么证明?
有人觉得有版权登记证书就行。也有人觉得Agent自动生成的,反正走的是工作流,有日志记录,完全能证明了吧?其实不然。
版权登记证书只能证明有人申请过登记,不能证明独创性
Agent调用日志证明"任务被执行了",但证明不了人的智力贡献
登记证书只能证明有人申请过登记,不能证明创作过程达到了独创性门槛。Agent调用日志可以证明"任务被执行了",但证明不了"人在生成过程中做了实质性的智力贡献"。法院真正关心的是在这个过程中人做了什么样的选择和判断——比如prompt是怎么迭代的、候选输出是怎么筛选的、人工做了哪些修改。这些东西需要事前存证,事后补一个登记或者导一份系统日志,没有用。
此外,从商业角度看还有一层你没想到的。很多科技公司融资时把AI Agent产出的内容库算成资产,但如果证明不了这些内容是怎么生成的、人在里面做了哪些关键决策、prompt体系有没有迭代逻辑,尽调时就会被砍估值。
留存创作记录不是额外的负担,是资产确权的基本动作。一个好习惯是每次Agent执行结束后,把本轮使用的prompt版本、候选输出截图、人工修改记录和最终发布时间一起归档。
💡 今天能做的第三件事
从今天起,给每次AI Agent的商用输出建一个归档记录,至少包含本轮prompt版本(含迭代日志)、候选输出和多轮筛选路径、人工修改前后的对比、以及最终发布的时间和渠道。

⛓️ 三个链条对应三个不同的风险
输入的授权链看你的工作流里流进了什么。数据源和输入素材不清不楚,商用就是盲押。
侵权的责任链看你的审核节点在哪里。Agent全自动跑,出了事你跑不掉。
事后的证据链看你留存了什么。只有日志没有人的决策记录,事后补什么都没用。
三者缺一不可。
钱斌 浙江大学法律硕士
律师 | 注册会计师 | 专利代理师

