 夜雨聆风
夜雨聆风AI 模型本质上是一个可学习的、复杂的非线性函数;但是需要注意,它并不是一个明确的函数公式;而是一个黑盒般的蒙猜神器:你不要管具体原理,那是符号主义的事;我们只要结果最近似完美即可。其主要思想为联结主义,即通过简化函数得到一个真实结果的近似解。
接下来我将简单回顾下我的学习。如果大家想了解AI的话推荐看b站up主闪客的视频:
【【闪客】一小时从函数到 Transformer】 https://www.bilibili.com/video/BV1NCgVzoEG9/?share_source=copy_web&vd_source=b4e9deecf69a97efc0256957204722eb
①函数→神经网络
函数的本质就是探究规律,那么就可以简化为x--(规律)--y;给出下列原始数据x和结果y;x=[1,2,3,4],y=[2,4,6,8];不难推出一个对应函数为y=2x。
y=kx+b就是最简单的线性函数,同时我们的结果也可以作为下一个方程的变量;也就是说可以将y1作为x2,构造y2=k2x2+b2,以此类推。但线性方程终究只能表示直线关系,表达能力弱;遇到稍微复杂一些的数据就无法解释。
因此我们需要引入激活函数将其变为非线性函数,即f(x)=g(kx+b);激活函数可以是exp(x)、正余弦等;常用的有:

有时只套一层激活函数并不能使曲线足够弯,所以我们可以像线性时那样继续套娃:把f(x)当成新的x,继续把整体丢进激活函数里;循环往复,直到其能最好的得出
然后,把最初的x拿出来当做输入,把最终的结果y拿出来当做输出;而中间你那不知道套了多少层的激活函数就是不同的神经元,它们一起构成了模型的隐藏层。这样你就得到了一个经典的神经网络模型图。
输入层(x1、x2...)→隐藏层(隐藏层1、隐藏层2...)→输出层(y)
而这个过程也被称为前向传播。
②神经网络的具体参数计算
神经网络模型的目的只有一个:“如何自动找到最优的k和b让模型预测得最准”。为此,我们引入损失函数来衡量预测与真实值的差距。
回归问题中最常用的损失函数为均方误差MSE。
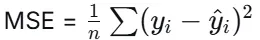
但是仅仅如此还是不够,我们接着引进了学习率参数来实现梯度下降。对于参数k和b,我们的参数更新公式为:
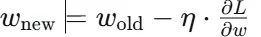
上面的w就是k,说实话具体的公式推导我记不住;涉及到求导和乱七八糟的。大致意思就是从梯度的反方向一点点调整k和b,以此来得到最优的损失函数。并在这个过程中,通过链式法则求导并逐层更新参数,这个过程称为反向传播。
③调教神经网络
为了防止过拟合和欠拟合的情况,引入了L1、L2正则化来限制模型复杂程度。除此之外,还可以使用Dropout的方法,在训练时随机“关闭”一部分神经元;举例来说就是避免我们建设的团队就是靠一个关键角色在那里扛。
还有其它方法,都是从模型或数据入手,目的一样;这里不做过多研究。
④针对图像的CNN
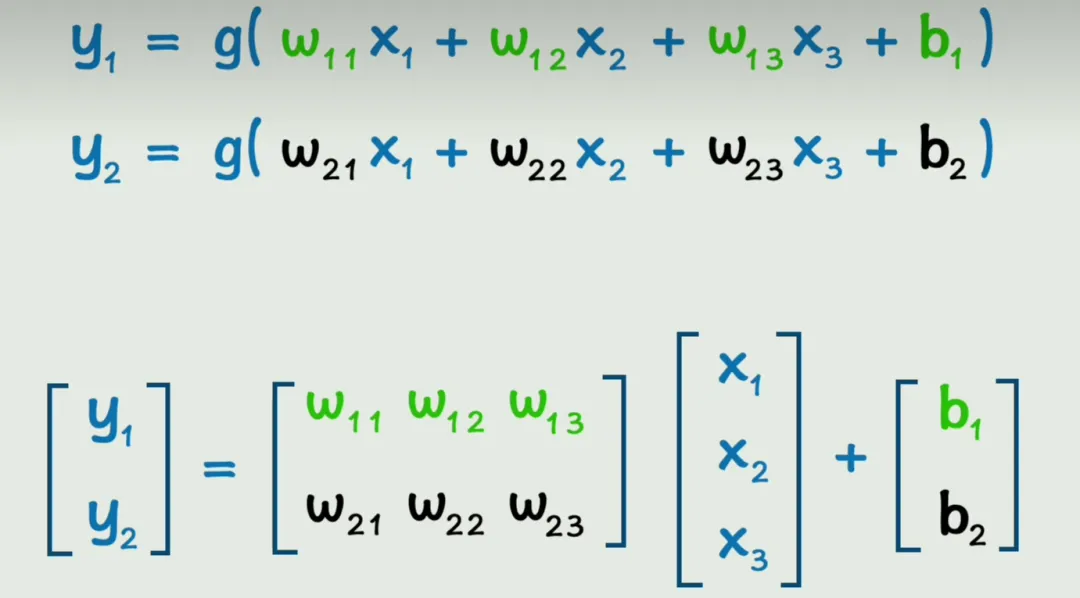
通过引入矩阵简化了公式,同时将麻烦的加减乘除运算变成矩阵运算;更适合计算机。(看视频里说是更好运用CPU的并行运算)
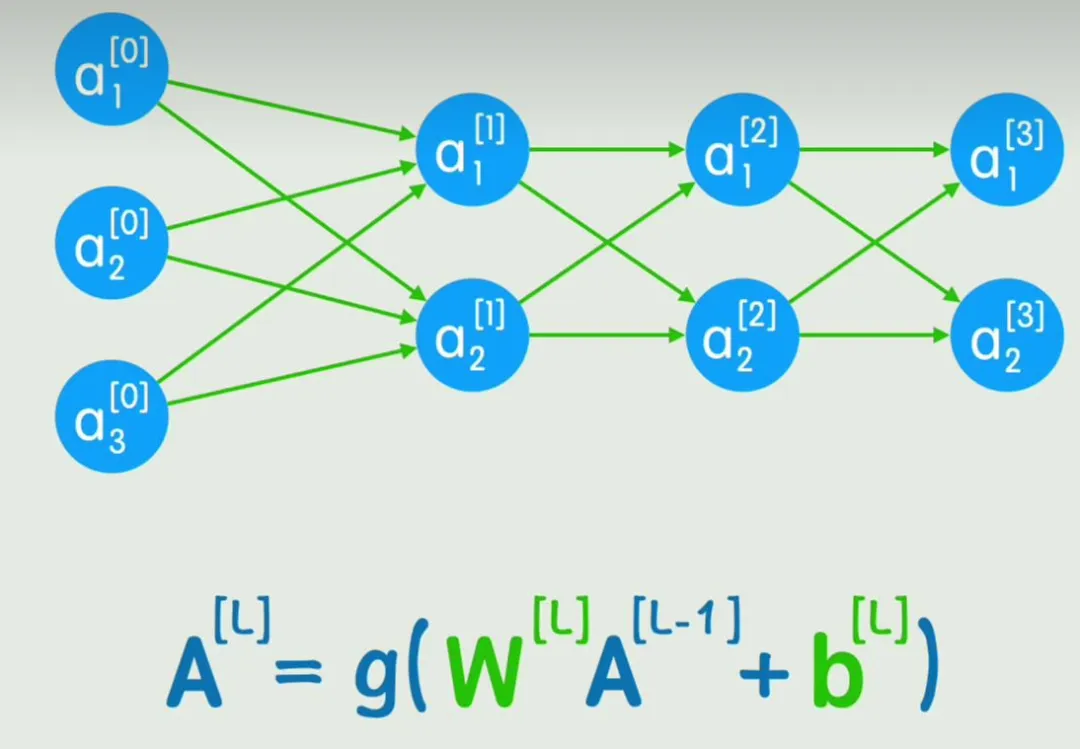
不再区分x、y和隐藏层,全部用a来表示层级。
可以看出,在神经网络模型中,每一层的神经元都与上一层所有神经元相连;这也称为全连接层。但是这种情况下加重了训练负担。即使是扫描完一张普通的静态图片,也会耗费较长时间。
因此CNN也就是卷积神经网络被提了出来,例如:通过矩阵的形式,在我的图片中选取一个3x3的矩阵,(3x3区域的灰度值即为矩阵数值);形成的矩阵乘以一个固定的矩阵得到一个值;接着再换个区域进行上述操作,以此类推。最终,这种运算方式遍历滑过原图像的每个地方,得到的所有数值形成一个新的图像。同时也可以实现原图片的模糊效果、阴影效果等。
这种运算方法称为卷积运算,刚刚那个固定的矩阵就是卷积核。在网络图中显示的就是将一个全连接层替换为卷积层。
好了,说了这么多其实我也没听懂;只知道CNN适用于图像识别和处理方向,能够更好的捕捉图像的局部特征。仅此而已。
⑤理解文字的RNN
RNN能够做到让计算机理解文字,并处理像句子一样有顺序的数据。假如我们现在给计算机一句话,“窝嫩叠”;计算机如何去理解这句话?或者说,我们如何做到文本的数字化?
首先是One‑hot编码:假设有1万个词,每个词用1万个维度的向量表示,其中一位是1,其余是0。那么每个词都是独立的;但是由于维度太高,不仅处理麻烦;而且很难捕捉到词语间的相关性。苹果就是苹果,橘子就是橘子,计算机不会把它俩联系到一起。
所以我们可以采用词嵌入的方法,将每个词映射为低维、稠密的向量(例如 128 维或 300 维);语义相近的词在向量空间里也靠近。
但是在一句话中,如果我们改变词的顺序,很有可能这句话的意思就完全变了。
因此,我们先把一句话中的每个词都输入进神经网络中,但是第一个词不着急输出Y1,而是先把Y1作为H1输入到第二个词的处理中;接着再进行一次非线性变化输出Y1。这样我第二个词处理时就包含了第一个词的信息。以此类推,把前面词的信息依次不断地向下传递,直到传入最后一句话的最后一个词中。这样我的神经网络模型就理解了这句话的所有信息。
这就是循环神经网络模型RNN,它像一个有记忆的人,每读一个词都会更新自己的“理解状态”,然后继续读下一个词。可用于翻译与对话。
依旧是没听懂😭
⑥transformer模型
由于RNN无法并行处理,且只能短距离理解;所以为了更进一步,提出了transfromer模型。它抛弃RNN的循环结构,用注意力机制并行处理整个序列,成就了大模型。
Transformer 就像一个“会议室”,每个人(词)可以直接与所有人交流,然后每个人根据听到的所有信息更新自己的想法,整个过程可以同时进行,效率极大提升。
好了,到这里我就完全听不懂了;其中具体的公式我也不放出来了,因为我也没听懂。
反正我只知道chatgpt的底层就是这个模型的一半,本质上不是聊天也不是翻译,就是猜下一个词;但是猜来猜去就变成了现在的全能性选手AI大王了。
把整个数学过程让AI生成了一张图,部分字体有点糊;凑合着看吧各位。
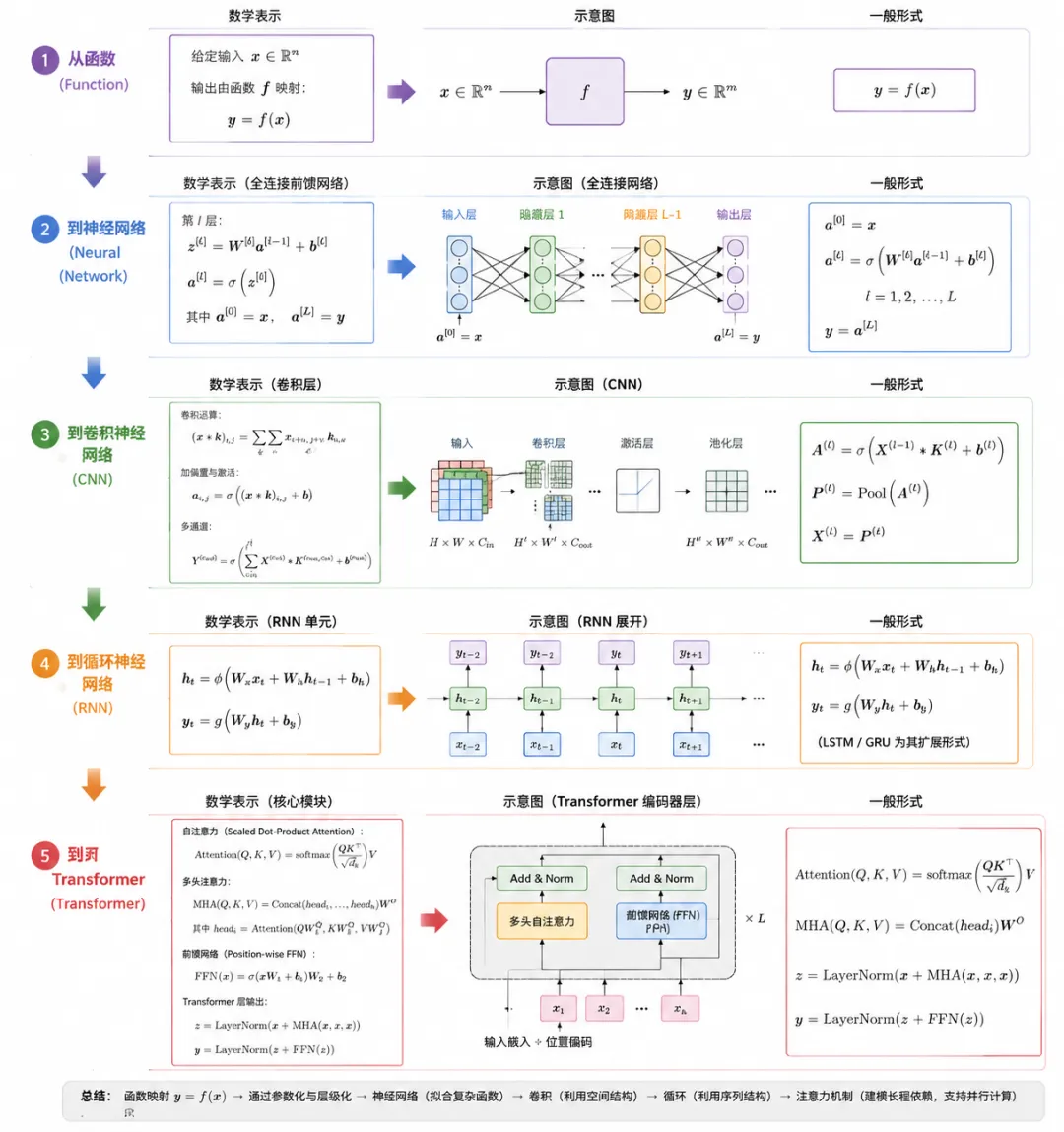
记录完毕,啥也不是;散会!
