 夜雨聆风
夜雨聆风
题图:openai/gpt-image-2
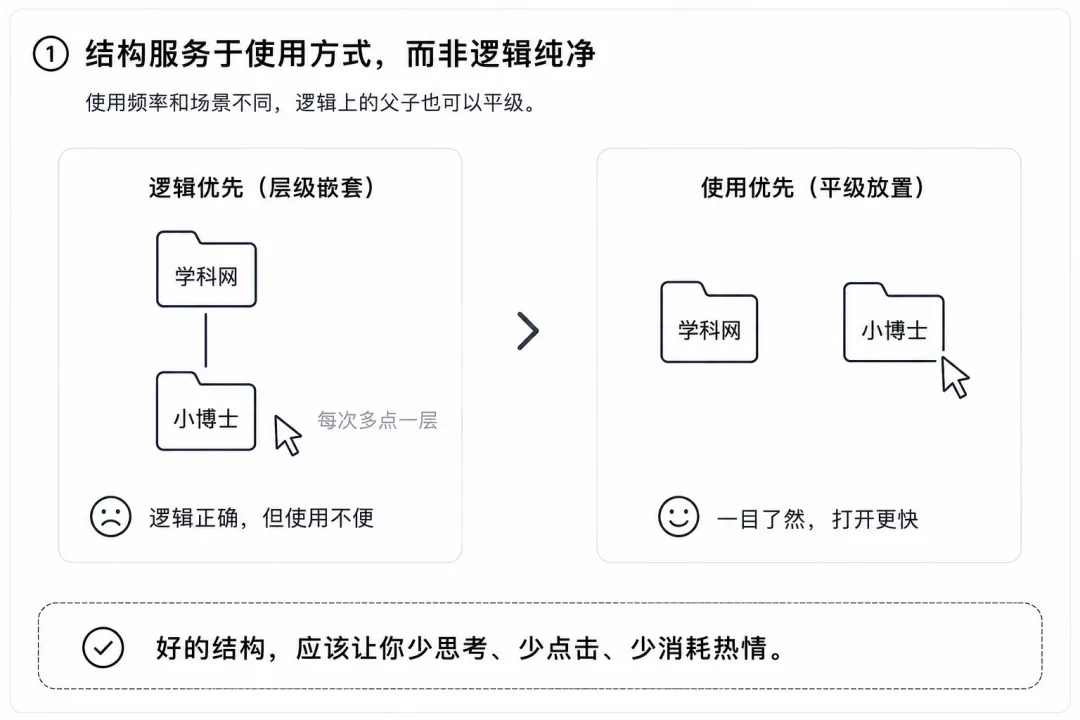
知识库搭了两周了,在九个Project里,让我纠结最多的都跟一件事有关:两个东西该不该放在一起,最典型的是学科网和小博士。
逻辑上,小博士是学科网体系下的产品,父子关系,没有任何歧义,按正常的文件夹逻辑,应该是学科网文件夹下面建一个小博士子目录,体面、工整、逻辑正确。
但我没这么干,我把它们俩平级放着,九个Project,各站各的。
不是偷懒,是因为我每次打开小博士文件夹的频率,远高于打开学科网大文件夹。如果把它藏在学科网下面,每次要多点一层、多翻一次。而这个"多一层",大概就是我对这件事的热情消耗殆尽的地方。
这不是一个文件夹的问题。这是一个原则问题。
九个Project是怎么长出来的
在建竞品分析工作台之后,事情开始加速了。
先是最早的"头脑风暴"和"求索笔记"。这两个看起来像,其实完全不一样。头脑风暴是"有个题但不知道答案",要发散,要乱想。求索笔记是"连题目都没想好怎么出",要先帮你把问题看清楚,再往下走。
然后是"语音笔记整理"。我平时会用语音做输入,说完了需要有人帮我结构化。以前是自己对着转写文本反复改,现在扔进这个Project,Claude知道我要的格式是什么。
接着是"数据分析"、"公众号文章"、"学科网"、"学科网小博士"。
AI信息聚合后来才出现,而且它是从求索笔记里拆出来的。求索笔记做的是深度研究,AI信息聚合做的是广度扫描,节奏完全不同。一开始塞在一起,发现不对,深度和广度混着跑,两头都憋屈。拆开之后各跑各的,反而都顺了。
加上最早试水的"竞品分析工作台",一共九个。
九个文件夹平铺在Projects下面,打开就是一目了然。但这里有一个问题:日常使用的东西都堆在Projects里,那日常不用的东西呢?

三层结构不是设计出来的,是分类逼出来的
最早的文件夹只有Projects,但用着用着就发现问题了。
有些东西不是Project,它们是按天记的工作日志,今天干了什么、遇到什么问题、解决了没有,这些东西没有明确的"产出目标",但有持续的记录价值,把它们塞进Projects里,哪个Project都不对,因为它们不属于任何一个特定目标。
于是有了WorkLog,跟Projects平级,但逻辑完全不同:Projects是目标驱动,"我要造一个东西";WorkLog是时间线驱动,"今天过了这一天"。
然后又遇到一个问题:网上看到的好文章,随手剪藏下来,它们既不是Project也不是WorkLog,放哪?
最早的解决方案是建了个Clippings文件夹,但几周后发现不对,Clippings里什么都有,自动抓的、手动存的、看过的、没看过的、质量高的、质量一般的,全混在一起。我想找一个之前保存的参考文章,得在垃圾堆里翻半天。
于是又把References拆了出来,区别很简单:Clippings是自动剪藏、没筛选过的,References是手动整理、你判断过质量的。一个代表"信息流",一个代表"知识库"。
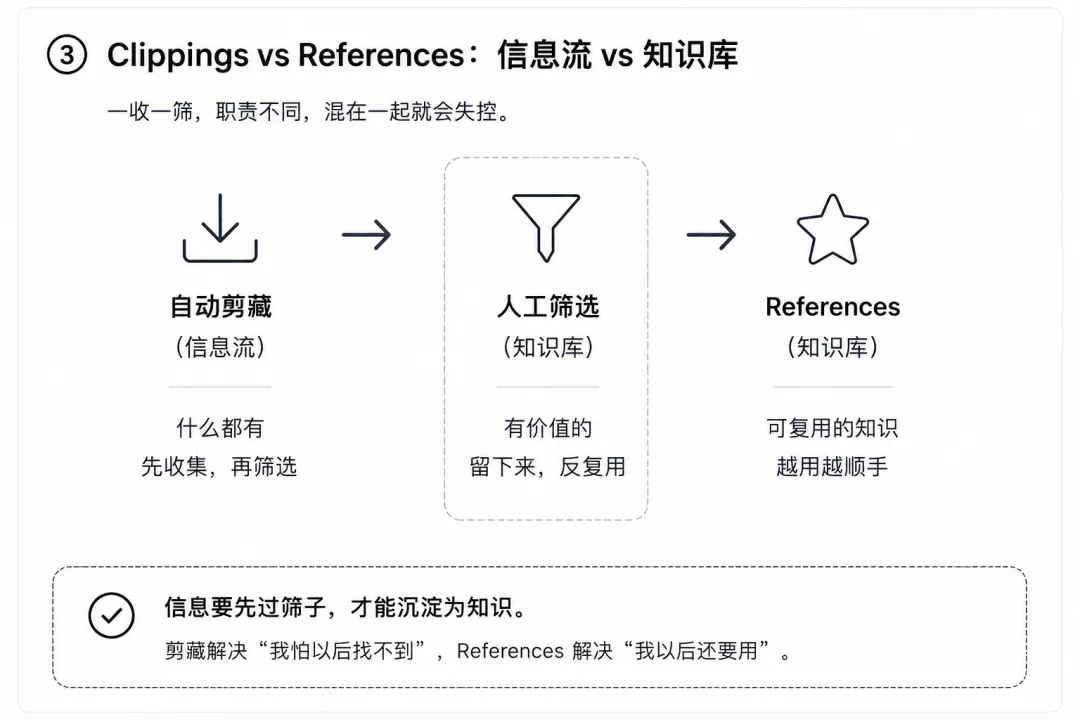
最终长出了三层:Projects(目标驱动)、WorkLog(时间驱动)、References(知识沉淀)。加上全局资源(INDEX、CLAUDE、MEMORY、灵感池),构成了现在的结构。
这整个过程,没有一次是"我应该画一个三层架构图然后施工",每一次拆分,都是被具体问题逼出来的。
这个原则后来被我写进了设计文档
有一次Claude帮我做完知识库的全身体检,聊到一个点:学科网和小博士平级,是不是逻辑上有问题?我们讨论了几轮,最后我总结了一句话。
"结构服务于使用方式,而非逻辑纯净。"
文件夹层级不应该为逻辑正确性牺牲日常使用便利。逻辑上父子关系的东西,因为使用频率和场景不同而平级放置,是完全合理的。
这句话后来被写进了全局CLAUDE.md的设计原则章节,成了整个知识库组织决策的底层规则。
相关的另一个原则是"Project vs WorkLog的本质区分",目标驱动的东西和时间线驱动的东西不能混放。它们的产出形态、使用节奏、归档方式都不一样。混在一起不是结构问题,是认知负担:每次打开都要判断"这个是目标还是日常"。
一个反直觉的发现
结构搭完之后,我最常用的操作不是"打开某个文件夹",而是全局搜索。
Obsidian的搜索很快,大部分时候我根本不需要一层层点进去,那为什么还要花时间把结构理清楚?
因为结构不是为了导航,是为了给AI看的。
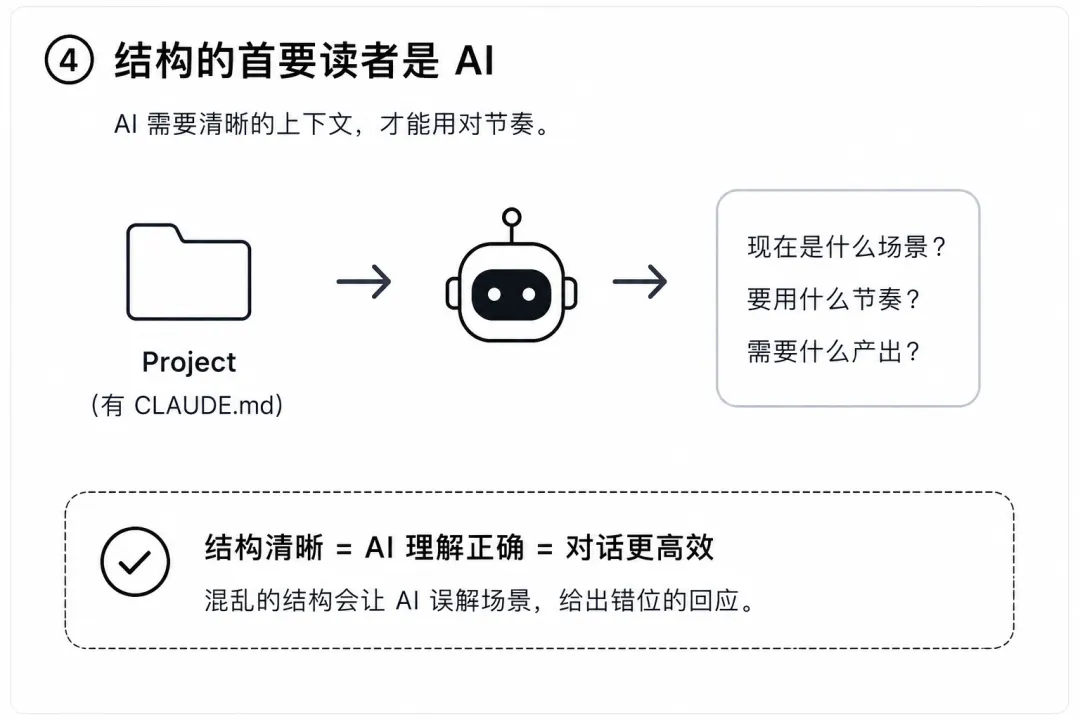
Claude每次打开一个Project,会读它的CLAUDE.md,理解这个空间的规则和上下文,如果结构是一团乱麻,AI就不知道你这次打开是"要做分析"还是"要整理笔记",它会用错误的节奏跟你对话。
结构的首要读者不是人,是AI。
这个认知一旦确立,很多事情就通了。为什么Instructions要轻?因为AI不需要你写5000字背景知识,它需要的是"现在是什么场景、用什么节奏、产出什么样"。为什么文件命名要一致?因为AI在扫描目录的时候,不一致的命名会传递不一致的信号。
最后
如果你也在搭自己的知识库,有三个东西可以从这篇带走:
第一,不要提前设计全部结构。等被具体问题逼到墙角,再建新的分类。这样的结构是"长出来的",每一个节点都有真实的肌肉记忆。
第二,结构服务于使用方式。逻辑正确不如用得顺手。如果某个文件你一天开十次,它就该放在最外层。
第三,结构的首要读者是AI。你的文件夹不是给自己导航用的,是让AI正确理解上下文用的。从这个角度去想,很多设计决策会不一样。
下一篇聊:搭了两周之后,我让AI给自己的知识库做了一次全身体检。发现了五个问题,有些是我想都没想到的。

