 夜雨聆风
夜雨聆风点击蓝字,关注我们
大家好,我是小张。
在前两篇文章中,我们带大家分析了上下文工程和提示词工程,今天一起来扒一扒最近很火的Harness Engineering。
如果你最近在参与企业级 Agent 的真实落地项目,你会发现一个让人崩溃的现象:在 Demo 阶段,Agent 表现得像个天才;一上线到生产环境,它就变成了个“智障”。 用户稍微换个问法,它就乱调 Tools;哪怕 Prompt 写出花来,也无法保证每次输出的稳定性。
很多同学学到这里就懵了:我已经懂了 Prompt,也知道了怎么接 Tools 和 Skills,为什么我的 Agent 还是没法稳定上线?
今天我们就来扒一扒大厂在上线 Agent 前,必须搭建的隐形护城河——Harness Engineering。
这篇文章同样将从基础概念、工作机制、核心对比,一直讲到面试高频八股文。全是干货,建议先收藏再看,留着面试前复习!

1基础概念:什么是 Harness?
如果我们把打造 AI Agent 比作造一辆自动驾驶汽车,那么当中的核心组件作用对应如下:
Prompt:是驾驶员的“行车意图”。
Tools/Skills:是汽车的“方向盘、油门和刹车”。
Harness:则是“仪表盘、安全带、黑匣子以及出厂前的碰撞测试场”。
以往,我们写完 Prompt,接上 Tools,跑通几个 Case 就觉得大功告成了。但遇到复杂业务(比如:用户输入包含恶意指令,或者某个外部 API 突然超时),Agent 往往会陷入死循环或产生严重的幻觉。
Harness 就是围绕 Agent 建立的一整套工程化保障体系。 它通常包含三大核心模块:Eval(自动化评测)、Trace(全链路追踪)和 Guardrail(运行边界控制)。只要 Agent 跑在 Harness 里,它的每一次思考和动作都是可度量、可监控、可兜底的。
一个标准的 Harness 工程目录通常长这样:
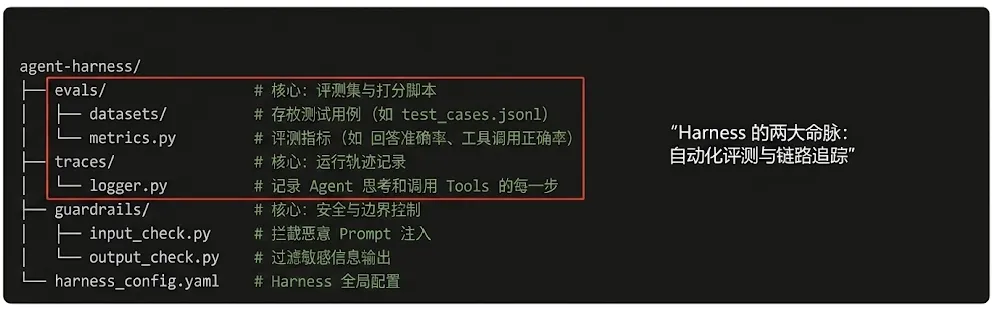
在这个结构中,evals 保证了你每次修改 Prompt 时,都能客观知道系统是变好了还是变差了;traces 保证了线上出 Bug 时,你能像看监控录像一样复盘;guardrails 则保证了 Agent 不会做出越界的危险动作。

2 核心进阶:“全链路 Trace”机制
如果只是简单地把 Agent 跑起来,随着业务复杂度的增多,必定会面临一个极其现实的工程问题:当 Agent 给出一个极其离谱的回答时,你根本不知道它是哪一步出错了。 是 Prompt 理解错了?还是 RAG 检索出了毫无关联的文档?还是 Tools 返回了脏数据?
而 Harness 的设计者早就想到了这个问题,并提供了解决方案——全链路 Trace(链路追踪)。通俗来说,就是“你走过的每一步,我都要记下快照”。
在复杂的 Agent 中,Trace 是这样工作的:
第一层:Input Trace(输入追踪)。 系统记录下用户最原始的输入,以及经过系统加工后的最终 Prompt。
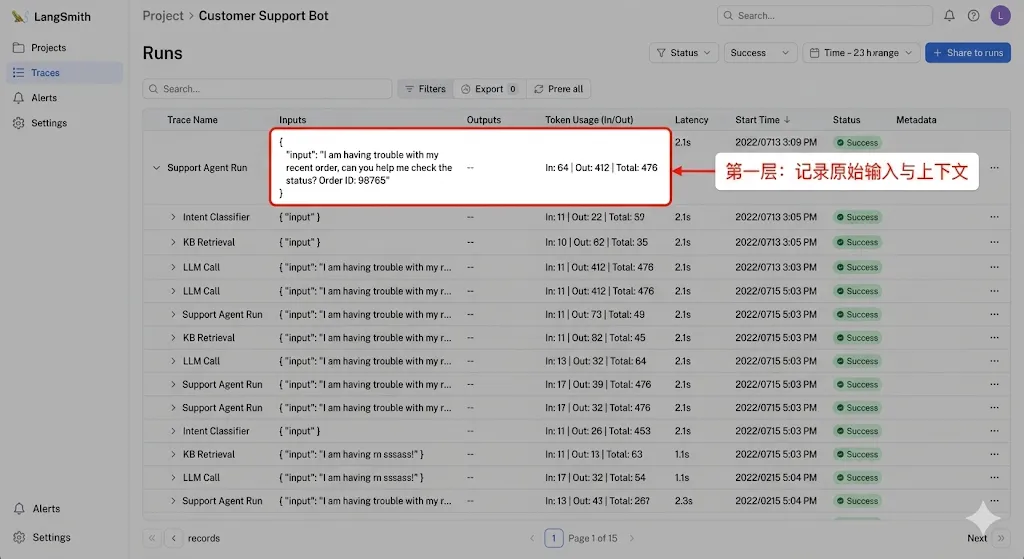
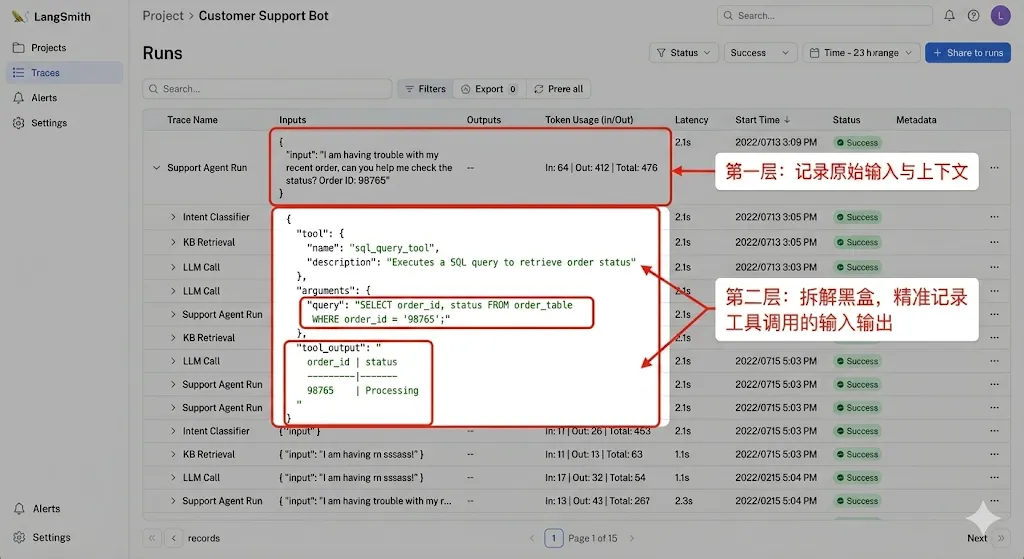
第二层:Execution Trace。 当 Agent 决定调用某个 Skill 或 Tool 时,Harness 会动态记录下传给工具的 Parameters以及工具返回的 Response。比如 Agent 调用了 SQL_Query 工具,这里就会清晰地记录下它生成的 SQL 语句是什么,数据库返回了几行数据。
第三层:Reasoning Trace。 记录 Agent 内部的思考过程。它为什么决定不调用工具直接回答?它对最终结果的置信度是多少?
为什么一定要做全链路 Trace? 它就像是外科医生的 X 光片。通过层层下钻,极大地降低了开发者 Debug 的认知负荷,彻底避免了“黑盒盲调”导致的瞎折腾,使得 Agent 的迭代具备了真正的工程化基础。

3 重点考察:Prompt Engineering 与 Harness Engineering 的本质区别?
这个问题也是面试中常问到的问题,一个问题可以看到你实际的掌握情况,总结下来就是 Harness 出现的必要性。这里我们就来总结一下(以下为个人观点,如有错误欢迎大家在评论区指出)。
Prompt Engineering (提示词工程):这是最早出现的概念,本质是“玄学调参”。它是通过不断修改自然语言的表述,试图引导大模型输出正确结果。但由于不同 LLM 的敏感度不同,更换 LLM 或遇到极端 Case 时,原本好用的 Prompt 就会失效。它依赖的是开发者的直觉和经验。
Harness Engineering (工程底座):我认为可以把它理解为“现代软件工程”。Harness 的出现,主要是为了解决 Prompt 无法被量化测试的问题。当你修改了一个 Prompt,Harness 会自动运行几百个测试用例(Eval),告诉你正确率是提升了还是下降了(减少“负优化”)。同时,通过 Guardrail 在代码层面对输入输出进行硬性拦截,极大提高了系统的安全性。
总结来说:Prompt 决定了 Agent 的“智商上限”,而 Harness 决定了 Agent 的“稳定性下限”。 企业真正需要的,是稳定可控的系统,而不是偶尔超神的 Demo。

4Agent Harness 高频面试八股文
问题一:实习拷打
为了帮大家拿下 Offer,这里同样总结了有关 Harness 与 Agent 测试架构面试中常问的问题,建议背诵!
Q1:什么是 Agent 架构中的 "Eval (自动化评测)",它解决了什么痛点?
答: Eval 是一套独立于 Agent 运行逻辑之外的打分和测试机制。解决痛点: 传统的 LLM 开发依赖人工“肉眼看”结果,效率极低且无法覆盖边界情况。通过构建包含标准答案的 Dataset,配合 LLM-as-a-Judge(让另一个大模型来做裁判)等技术,Eval 可以在每次代码提交时自动给出客观的分数(如准确度、幻觉率),解决“一改代码就不知道会不会引发新 Bug”的痛点。
Q2:什么是 Harness 中的 "Guardrail (安全护栏)"?为什么不能只靠 Prompt 约束模型?
答: Guardrail 是部署在 LLM 输入和输出两端的硬性规则层。原因: 大模型具有不可预测性,用户可以通过“越狱(Jailbreak)”等手段绕过 Prompt 的系统指令。只靠 Prompt 约束(例如在 Prompt 里写“绝不允许提供暴力信息”),模型仍有可能被攻破。Guardrail 相当于在代码层级加了一道安检,一旦检测到输出包含敏感词或未授权的 API 调用,会直接在程序层面拦截并返回兜底话术,确保绝对安全。
Q3:什么是 "LLM-as-a-Judge (大模型作为裁判)"?使用它有什么注意事项?
答: 这是 Eval 中常用的一种评估手段。由于 Agent 的输出通常是长文本,无法使用传统的精确匹配(Exact Match)来打分,因此通过编写特定的评分 Prompt,让一个能力更强的大模型(如 GPT-4)来评估 Agent 的输出质量。注意事项:
裁判模型必须比被测模型能力强;
裁判容易产生“位置偏见(Position Bias)”和“长度偏见(更喜欢长答案)”;
需要提供明确的打分标准(Rubric)以保证裁判输出的稳定性。

5写在最后
从底层写死函数的 Tools,到解耦网络通信的 MCP,面向业务包装的 Skills,再到今天决定 Agent 能否走向生产环境的 Harness Engineering (Eval & Trace)。看懂这四步,你就真正理解了大厂企业级 Agent 走向标准化、工程化、规模落地的核心架构思路。
保持对前沿技术的敏感度,绝对是拉开差距的关键所在。后续我会持续更新 Agent 记忆机制 (Memory) 等方向的硬核技术解析。
如果你正在找工作,或者对 AI 落地感兴趣,欢迎关注、点赞、在看!你的支持是我持续输出最大动力!
更多相关的八股文小编整理在飞书文档中,关注公众号回复[A011],获取更多相关八股。

