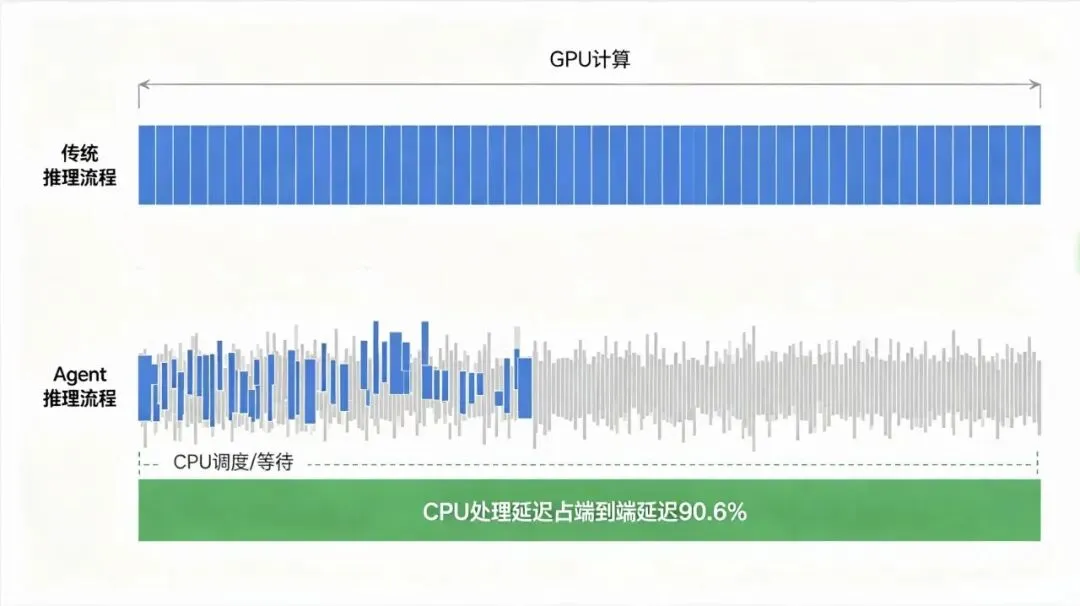
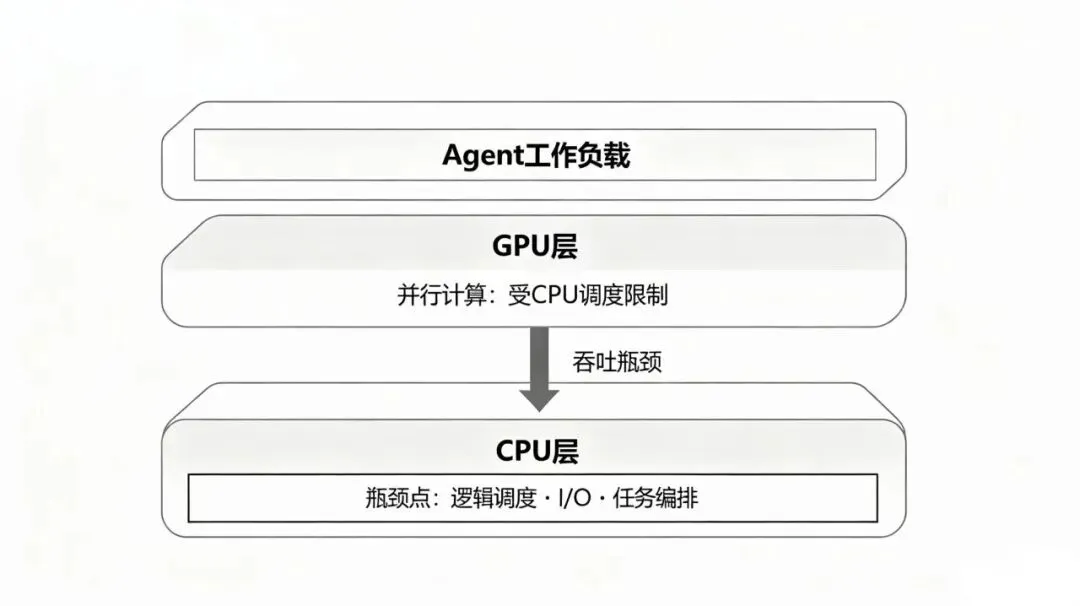
Agentic AI引爆CPU超级周期:涨价30%、交付半年、产能售罄,一块最短的板正在重估过去两年,产业界对AI算力的讨论始终围绕一条默认公式展开:算力瓶颈等于GPU供给。所有资源、所有注意力、所有资本开支,都沿着这条公式部署。从云计算厂商的资本开支计划,到创业公司的融资叙事,再到二级市场的估值逻辑,GPU是那个唯一被讨论的稀缺资源。现在,这条公式正在失效。不是GPU变得不重要了。而是当AI的工作负载从“训练”切换到“Agent推理”,算力系统的瓶颈位置发生了物理位移。它在GPU的下游,在所有并行计算结束之后的地方,在一颗被我们叫了四十年名字的芯片上。CPU。这不是CPU的逆袭,不是CPU的复兴,更不是某个芯片巨头重新占据了产业链C位。这些叙事都属于过去,属于宫斗戏的逻辑。正在发生的事,需要用另一种语言来描述。算力系统的短板,正在发生结构性迁移。谁还在按旧公式配置算力,谁就在为一种沉默的、尚未被充分定价的浪费买单。一、GPU在等什么?要理解这块短板为什么是CPU,必须先看清楚一件事:Agent任务与过去两年我们所熟悉的AI任务,到底有什么本质区别。过去两年,产业界对AI算力的讨论几乎等同于一个场景——大模型训练与推理。在这个场景里,工作负载是清晰的:输入端接收token序列,模型执行矩阵乘法与注意力计算,输出端生成token序列。计算是密集的、连续的、可预测的。GPU专为此而生。它的价值在于将万亿级参数分布在数千个核心上并行处理,把单次前向传播的时间压缩到极致。在这种任务形态下,CPU的角色是清楚的:数据搬运、初始化、外围调度。它不是瓶颈,因为整个任务的时间几乎全部消耗在GPU的并行计算上。CPU与GPU的配比是一比八,这个比例不是某个厂商的产品策略决定的,而是任务特征决定的。CPU配得再少一些,系统也能跑。配得再多,边际收益归零。这是旧地图。Agent任务的地形完全不同。一个Agent工作流不是“输入-计算-输出”的直线,而是一个包含计划、工具调用、结果获取、反思、再计划、再调用的复杂图谱。Agent面对一个问题,不是直接输出答案,而是先拆解问题,决定调用哪个API、查询哪个数据库、执行哪段代码、启动哪个沙箱环境。拿到工具返回的结果后,它需要判断这个结果是否可用,是否需要调整策略,是否需要发起新一轮调用。每一步“调用-等待-反思-再调用”都是一次CPU密集的流程控制操作。GPU在这一刻是空闲的。它需要等待CPU完成工具调用的发起、内存的分配、I/O的处理、状态的保存、下一个子任务的调度。只有当所有流程控制环节跑完,GPU才能拿到指令,开始下一段并行计算。佐治亚理工学院与英特尔实验室在一份联合研究中,对一个标准Agent工作负载做了细颗粒度的时间与功耗拆解。结果令人不安。在Agent任务的全链路中,CPU侧的工具处理延迟占端到端延迟的90.6%。CPU侧的能耗占系统总能耗的44%。这不是一个“CPU性能还需要优化”的技术建议。这是一个系统架构的基本事实。当整个任务链路上九成时间消耗在CPU的处理等待上,讨论GPU的算力密度已经失去了意义。系统整体的吞吐量,不再取决于你并行计算有多快,而取决于逻辑调度跑得通多快。GPU有九成时间不是在工作。是在等。你买的不是算力。你买的是等待时间。二、短板的物理学:从1:8到1:1理解了这个事实,就能理解接下来的判断。这个判断是全文的理论内核,也是理解当前CPU产业变化的唯一正确框架。它叫短板迁移。任何一个由多个组件串联构成的系统,其整体性能由性能最差的那个组件决定。这是系统论里的木桶法则,不需要再论证。在大模型训练时代,最短板是GPU的并行计算能力。那时的CPU够用,因为它处理的流程控制在整个任务时间中占比微不足道。瓶颈在矩阵计算,堆GPU就是对的。Agent时代改写了组件之间的时间分配结构。流程控制、工具调用、状态管理的占比从可以忽略,膨胀为绝对主导。CPU从“够用”变成了“卡住”。GPU再强,系统整体吞吐被CPU的处理速度锁死。这不是CPU变强了。CPU单核性能的提升速度在过去十年从未加速。IPC每年低个位数增长,这是公开数据。也不是GPU变弱了。GPU的算力密度仍在沿着摩尔定律的余温上行。变化发生在任务形态上。任务从“算得多”变成了“管得多”。GPU负责算:矩阵乘法、并行浮点运算。它的战场是确定的、重复的、可预测的。CPU负责管:任务编排、流程控制、异常处理、工具调用。它的战场是不确定的、分支密集、需要操作系统级支持的。在训练任务里,“管”的占比微不足道。在Agent任务里,“管”的占比淹没了“算”。GPU再快,只能在它被分配到的、已经由CPU处理完毕的计算片段里发挥。它无法绕过CPU直接发起工具调用,无法绕过CPU管理自己的内存,无法绕过CPU与其他节点通信。CPU卡住的地方,就是整个系统的物理上限。短板迁移不是理论推演。它已经开始在数据中心的物理部署中显形。TrendForce在今年的一份报告中测算,每吉瓦AI数据中心所需CPU核心数,将从2025年的约3000万颗增至2026年的约1.2亿颗。这不叫需求增长。这是一个瓶颈被识别后,系统为了达到基本效能所必须补上的最低配置缺口。配比从1比8向1比1收敛,不是产业共识发生了变化。是物理约束逼出的收敛。当系统发现无论怎么加GPU、端到端吞吐都不再增长时,唯一的解法就是加CPU,把这块短板补到至少不拖后腿的程度。三、能耗去了哪里?44%的能耗消耗在CPU侧。这个数字需要被单独拎出来讲透。它指向的不只是技术架构问题,它指向的是成本结构、投资回报率和产业配置逻辑的根本性缺陷。一个智算中心的总电力消耗中,有将近一半不是花在有效计算上。它花在了等待上——GPU在那段时间里不产出任何token,但仍在消耗电力。这部分电费进的是运营成本,出的却是零产出。这不是某个数据中心运维团队的问题。这是整个产业在按旧地图配置新任务时,必然掉进的效率陷阱。产业界评估算力的传统标尺是单芯片能力:TOPS、TFLOPS、每秒多少万亿次运算。这是一个单兵指标。它衡量的是一个芯片在理想状态下能跑多快。但系统性能从来不是单兵指标的简单加总。一个系统真正的效能,取决于它在单位时间、单位功耗内能完成多少个完整的任务周期。由此可以提出一个新的度量维度,它比TOPS更适合Agent时代的系统评估。系统性能密度。定义为:单位功耗、单位时间内,系统完成的端到端Agent任务数量。在这个标尺下,一台GPU集群的账面算力不是核心指标。核心指标是GPU跑满时系统完成的任务数,除以GPU闲置等待时的任务数为零——这个加权平均的结果。当等待时间占比达到九成,系统性能密度不是由GPU峰值算力决定的,而是由CPU消除等待的能力决定的。CPU从成本项变成了效能乘数。它卡住的地方,就是系统性能密度的物理上限。当九成时间在等待时,堆更多GPU不是建设。是浪费。这不是修辞。这是一个可以被财务部门量化的物理事实。四、谁在为旧公式买单?以上,是我对当前算力系统状况的第一个判断。Agent时代,算力系统的短板已经从GPU迁移到了CPU。这不是观点之争,是任务形态变化后,系统瓶颈位置必然发生的物理位移。这个判断的推演路径是清晰的:Agent任务改变了芯片间的时间分配结构,CPU处理环节从可忽略变成了绝对主导,系统瓶颈从并行计算迁移到了逻辑调度。GPU的算力优势被CPU的调度瓶颈锁死。系统整体效能的提升,不再取决于你往系统里塞进多少GPU,而取决于你能不能让CPU不再卡住。谁还在按大模型训练时代的公式配置算力,谁就在为一个日益昂贵的错误配比买单。问题找到了。下一步的问题是:当全世界突然对一个被低估了四十年的芯片发出指数级需求,物理世界的供给侧,准备好了没有?一块本应报废的晶圆正在被客户排队抢购。交付周期从两周拉到了半年。涨价不再是谈判桌上的博弈筹码,而是供给刚性遭遇需求结构性的必然算术结果。下篇,我们继续来聊聊晶圆厂的账本。本文基于公开资料解读,仅为交流分享,不构成投资建议,观点仅供参考。
 夜雨聆风
夜雨聆风