 夜雨聆风
夜雨聆风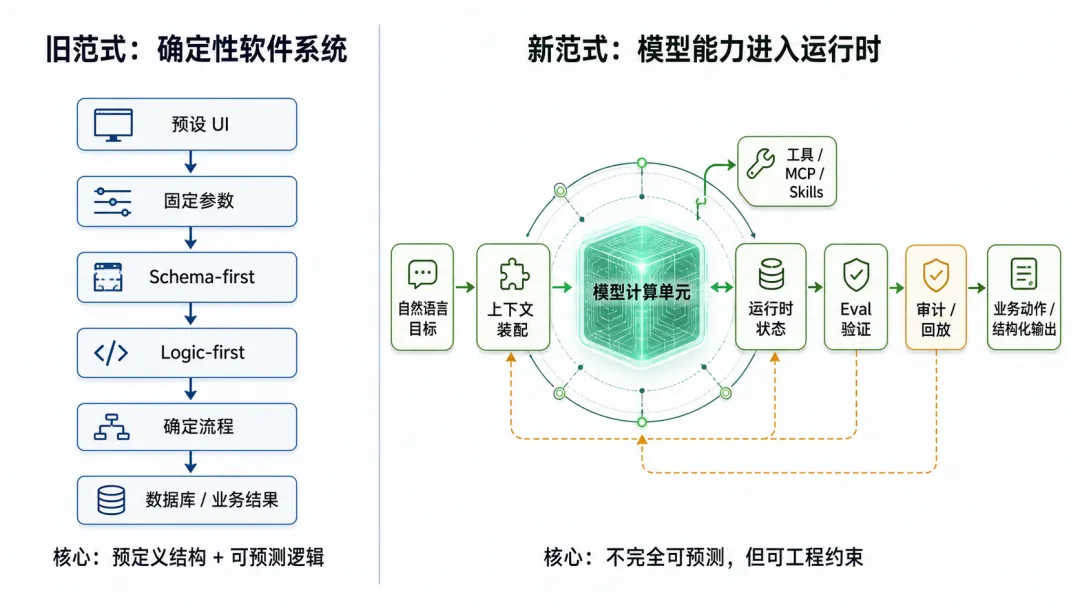
这个计算单元的本质特征是:
不完全可预测,但可以被工程约束。
这也是 AI 时代软件工程变化的核心。
01
传统软件工程的三个默认前提
传统软件系统长期建立在三个前提上。
第一,Schema-first。数据结构先被定义,系统按字段接收信息。
第二,Logic-first。系统行为先被设计,执行路径由确定逻辑控制。
第三,UI-first。交互界面先被设计,用户在预设表单、按钮、流程中提交参数。
这三个前提支撑了过去几十年的系统设计方式:
前后端分层、数据库建模、接口定义、流程编排、产品经理 / 设计 / 前端 / 后端分工,以及大量围绕表单、列表、审批流建立的业务系统。
02
模型能力冲击的不是工具,而是系统前提
模型进入系统运行时后,变化不只是“多了一个 API”。
它改变的是系统对输入、行为和数据边界的假设。
输入不再只是固定参数,而可能是一段自然语言目标。
行为不再完全来自预定义流程,而可能在运行时动态生成。
数据不再只是静态字段,而会变成上下文、证据、记忆、中间状态和历史记录的组合。
界面也不再只是字段收集器,而会逐渐变成目标理解与任务发起器。
所以真正的问题不是“如何调用大模型”,而是:
系统如何承接一个会理解、会判断、会调用工具、但不完全稳定的计算单元。
03
“不完全可预测”不是失控
模型的不确定性主要来自四个方面。
任务理解不完全可预测。同一句话在不同上下文下可能被理解成不同任务。
执行路径不完全可预测。模型可能选择不同步骤、不同工具、不同推理顺序。
输出质量不完全可预测。结果可能正确、部分正确、结构不稳,甚至混入无依据内容。
事实边界不完全可预测。模型可能把历史上下文当成当前事实,把推断写成结论,把建议写成已发生。
但“不完全可预测”不等于“无法工程化”。
工程上仍然可以控制关键边界。
可以控制上下文:只提供必要材料,并区分事实、历史、推断和建议。
可以控制指令:明确目标、角色、约束、禁止项和失败处理方式。
可以控制输出:使用 schema、模板、枚举、分段和校验规则。
可以控制工具:限定可用工具、权限、参数范围、审批机制和副作用边界。
可以控制验收:通过 eval、冲突扫描、人工审核、日志和回放验证结果。
因此,重点不是追求模型绝对确定,而是设计一个能容纳不确定性的系统外壳。
04
模型本身不等于智能系统
单次模型推理只是智能系统的一部分。
模型更像一个推理核心,而不是完整系统。
一个真正能进入业务流程的智能系统,至少还需要这些结构:
Context 管理。负责上下文装载、裁剪、隔离、回收和历史区分。
Prompt 装配。根据任务动态组合规则、约束、角色、格式和失败补救策略。
工具边界。负责工具发现、授权、调用、参数约束、结果回填和副作用控制。
技能封装。把稳定的场景经验沉淀为可复用能力,而不是每次重新写提示词。
运行时状态。记录 session、步骤、中间结果、失败原因和恢复点。
验证闭环。检查结构、来源、事实边界、业务规则和冲突。
观测与审计。能追踪、回放、定位问题,而不是只保存最终回答。
没有这些结构,模型只是一个聊天窗口。
有了这些结构,模型能力才可能成为系统能力。
05
判断一个 AI 系统是否工程化
不要只问:
模型能不能回答?
更应该问:
输入边界是否清楚?
事实、历史、推断、建议是否分层?
运行状态是否可恢复?
工具调用是否有权限和副作用边界?
输出是否可校验?
错误是否能回放?
决策是否能跨阶段流转?
成本、超时、安全、降级是否进入主体设计?
如果这些问题没有答案,系统只是把模型嵌进去了,还没有真正工程化。
06
AI 时代的软件工程重点
AI 时代的软件工程,不是把模型塞进系统,而是围绕一个“不完全可预测但可被约束的计算单元”,重新设计系统结构。
重点会转向这些问题:
入口如何接收模糊目标。
上下文如何被组织和裁剪。
任务如何被拆解和推进。
工具如何被授权和调用。
状态如何被保存和恢复。
输出如何被验证和回写。
错误如何被追踪和复盘。
治理如何进入系统默认结构。
当一个系统能调度模型、限制模型、验证模型、恢复模型、审计模型,模型能力才真正进入了软件工程。
