夜雨聆风
夜雨聆风过去很长一段时间里,我们习惯把提示词当成一段“写给模型看的话”。
于是很多人开始寻找所谓的“万能 Prompt”:角色设定要更完整,规则要更详细,输出格式要更规范。看起来,Agent 的问题似乎都可以通过继续修改提示词来解决。
但真正做过 Agent 系统的人都知道,事情没有这么简单。
一个 Agent 是否稳定,并不只取决于提示词写得好不好。它还取决于模型能力、工具接口、上下文组织、运行时控制、日志追踪和评估体系。提示词当然重要,但它不是孤立存在的文本,而是 Agent Runtime 里的行为策略层。
这篇文章想讨论的,正是这个认知转变:
不要再把 Agent 提示词当成模板,而要把它当成一个可观察、可评估、可迭代的工程资产。
只有当 Prompt 从“文案”升级为 “Policy Layer”,Agent 才真正从一次性对话,走向可治理的智能系统。
 | 侯君璠,AI架构陪跑师,清华大学工程管理硕士(MEM),企业架构研究会发起人,国内大型央企单位技术总监、解决方案专家。20余年工作经验,曾任美国某大型科技公司-M中国区首席架构师,国内某大型险资技术总监、某大型科技咨询公司副总裁。深耕于企业架构、人工智能研究与落地方案,以及先进工程项目管理和企业数字化转型等领域。 |
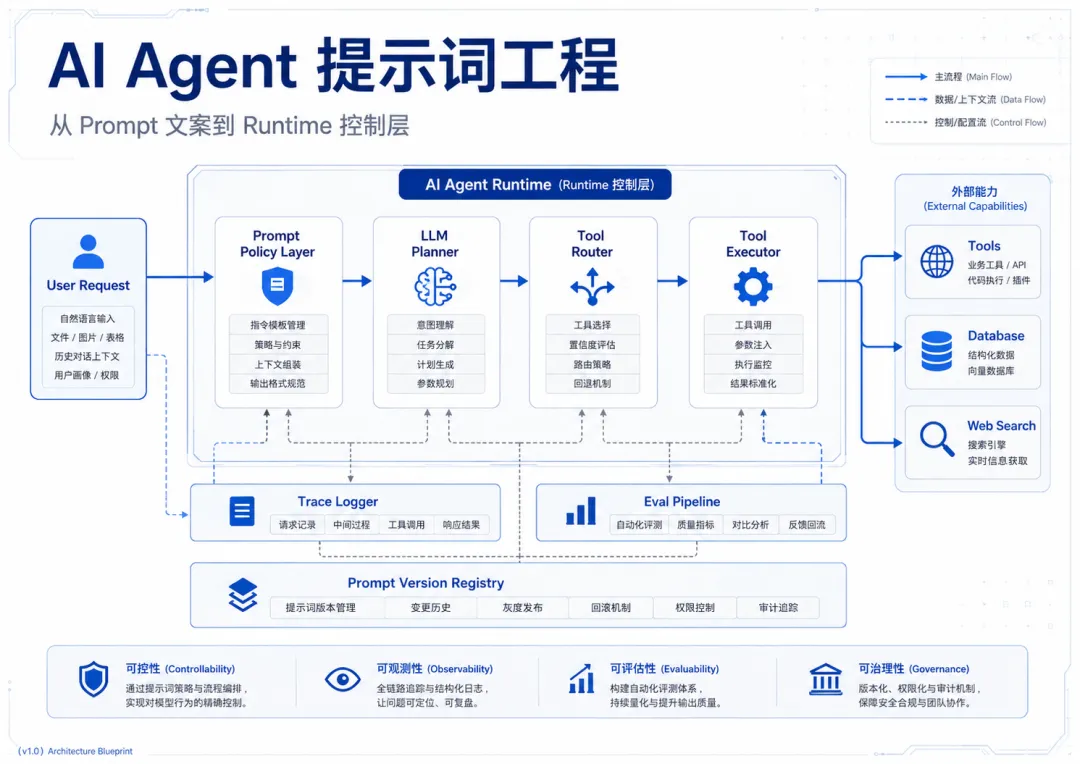
图1 AI Agent 提示词工程总览:Prompt 从文案走向 Runtime 控制层
Prompt 不是模板,而是 Agent Runtime 的 Policy Layer。
很多人做AI Agent,第一步是找提示词模板。
这件事本身没有错。问题在于,很多人把提示词理解成了“写给大模型的一段说明书”。于是他们不断寻找更完整、更专业、更长的模板,期待只要提示词足够精致,Agent 就能稳定工作。
但真实工程里,Agent 出问题往往不是因为提示词少了一句话。更常见的问题是:Agent 不知道什么时候该调用工具;调用了工具,却没有正确处理工具返回;用户信息不足时,它选择了猜测;工具失败时,它假装成功;上下文变长后,它开始忽略关键约束;改了一版提示词后,当前样例好了,其他场景却坏了。
这些问题不是“文案问题”,而是 Agent Runtime 的行为控制问题。AI Agent 提示词工程真正要解决的,不是如何写一段漂亮提示词,而是如何设计一套可观察、可评估、可迭代的 Agent 行为控制层。
【企业架构研究会在4月份发布了智能架构的研究报告,如有希望获取的,请留言:“获取资料”并添加文章最下方的联系人,我们恭候各位到来一同研讨中国的企业IT架构应该怎么做】
一、为什么“万能提示词”在工程上必然失效?
一个Agent 的行为不是由提示词单独决定的,而是由多个因素共同决定。你从网上复制到的通常只是 Prompt Policy,却没有复制模型能力、工具接口、上下文状态和运行时控制。
这就是为什么同一段提示词在别人那里稳定,在你的系统里却经常跑偏。它不是孤立文本,而是系统环境的一部分。
Agent Behavior =Model Capability+ Prompt Policy+ Tool Interface+ Context State+ Runtime Control
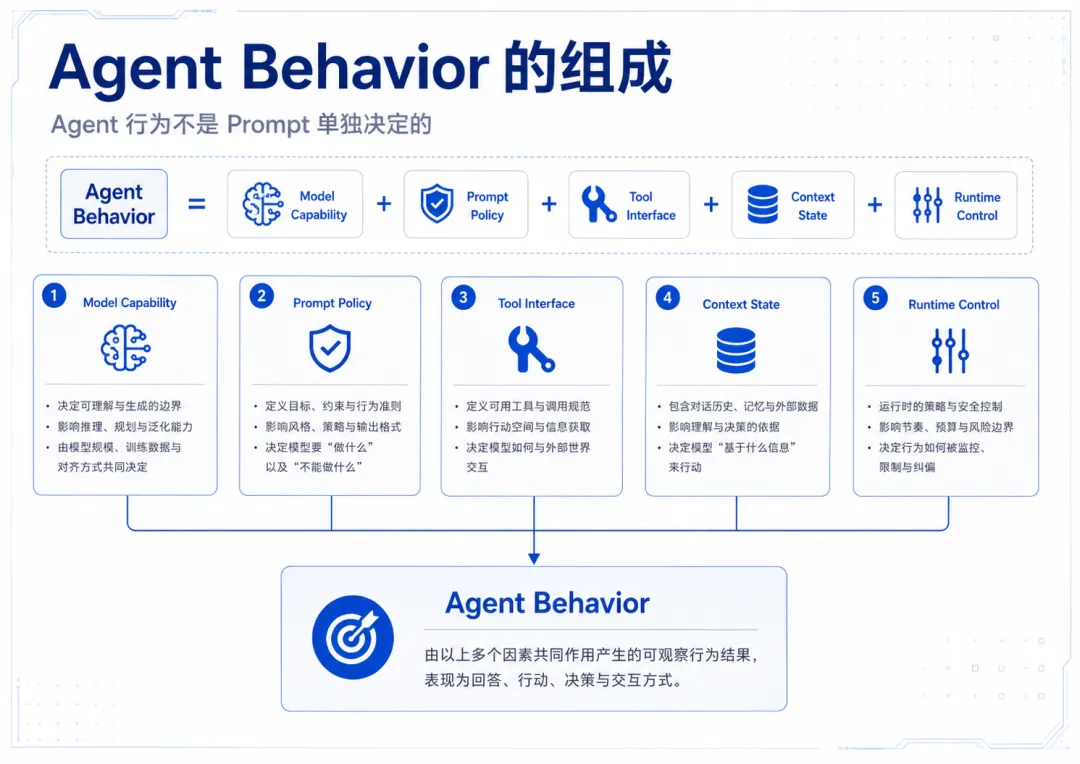
图2 Agent Behavior 的组成:行为不是 Prompt 单独决定的
1. 模型能力不同
同一段提示词,在不同模型上表现可能完全不同。有的模型需要更明确的步骤约束,有的模型更适合抽象原则;有的模型工具调用稳定,有的模型在多轮上下文里容易丢失约束。
所以,提示词不能脱离模型版本讨论。生产系统里,模型版本应该和prompt version 一起管理,否则你无法判断行为变化来自模型升级,还是来自提示词修改。
2. 工具接口不同
Agent 是否稳定,很大程度取决于工具schema是否设计得好。很多看起来是prompt 问题,本质上是tool contract设计问题。
如果工具没有返回置信度、时间、来源,Agent 就很难判断结果是否可靠;如果工具失败只返回一句error,Agent就很难决定是重试、换工具,还是告诉用户失败;如果工具参数过于自由,Agent就容易构造错误参数。
{"tool_name": "search","input": {"query": "string","top_k": "integer","recency": "string","source": "web | internal | hybrid"},"output": {"results": [{"title": "string","url": "string","snippet": "string","confidence": "float","published_at": "string"}]}}
3. 上下文状态不同
Agent 不只是处理当前输入,还要处理历史消息、用户偏好、文件内容、检索结果、工具返回、权限状态。这些上下文如何拼接、排序、截断、摘要,会直接影响模型行为。
如果你把动态变量全部塞进系统提示词前面,稳定策略就会被噪声稀释;如果你把关键约束放在靠后的上下文里,模型可能在长上下文中忽略它;如果你对历史消息做摘要,摘要质量又会影响Agent的判断。Prompt Engineering 不是单纯写文字,而是Context Engineering。
4. Runtime控制不同
真正的Agent 不是一次模型调用,而是一个运行时循环。一个典型Agent Runtime 至少包含:User Input、Context Builder、Prompt Policy Injection、LLM Planning、Tool Selection、Tool Execution、Observation Update、Stop / Continue Decision 和 Final Response。
你看到的是最终回答,但真正决定质量的是中间这条trajectory。提示词要控制的,不只是“最终怎么说”,而是整个 trajectory怎么走。
二、Agent 提示词的本质:Policy,不是 Instruction
普通提示词像instruction,它主要影响输出风格。Agent 提示词更像 policy,它要定义什么情况下可以回答,什么情况下必须查工具,什么情况下必须追问,什么情况下必须拒绝,什么情况下需要人工确认,工具失败时怎么处理,证据不足时如何表达不确定性,多条规则冲突时谁优先。
Policy Layer 1:Hard ConstraintsPolicy Layer 2:Decision HeuristicsPolicy Layer 3:Tool Use PolicyPolicy Layer 4:Evidence PolicyPolicy Layer 5:Output Contract
1. Hard Constraints:硬约束
硬约束是Agent 不能违反的规则。它对应系统安全下限。比如:不得编造工具没有返回的信息;不得在用户未授权时执行不可逆操作;不得把推测表达成事实;不得忽略工具错误;不得绕过权限系统。
2. Decision Heuristics:判断启发式
这部分不是规定死步骤,而是告诉Agent 如何判断。比如:如果用户目标不明确,先澄清目标;如果缺少外部事实,优先调用检索工具;如果工具结果冲突,比较来源可靠性、时间新旧和证据直接性;如果答案依赖假设,必须显式列出假设;如果置信度不足,输出不确定性而不是强行结论。
这部分决定Agent 是否真的“像专家一样工作”。
3. Tool Use Policy:工具使用策略
工具策略要解决三个问题:什么时候用工具、用哪个工具、工具失败怎么办。
当问题涉及实时信息、用户文件、数据库状态、外部事实时,必须调用工具;当已有上下文足以回答时,不要为了形式调用工具;工具失败时,不得伪造结果,应根据错误类型选择重试、降级、换工具或向用户说明。
4. Output Contract:输出契约
输出契约不是简单规定“用 Markdown”。它要保证输出可验证、可消费、可追踪。一个稳健的输出契约通常包括结论、依据、不确定性和下一步建议。如果使用工具结果,必须保留来源线索;如果无法完成任务,必须说明失败原因。

图3 Prompt Policy Layer:Prompt 不是普通指令,而是多层行为策略
三、Agent Runtime 架构:Prompt 应该放在哪一层?
如果从架构角度看,一个生产级Agent 系统可以拆成 Control Plane 和 Data Plane。Control Plane 负责策略、权限、评估、版本和监控;Data Plane 负责模型调用、工具执行、上下文流转和结果生成。
Prompt 属于 Control Plane,不应该只是散落在代码里的字符串。更准确地说,Prompt Policy 需要经过编译、注入、追踪和评估,而不是简单拼接。
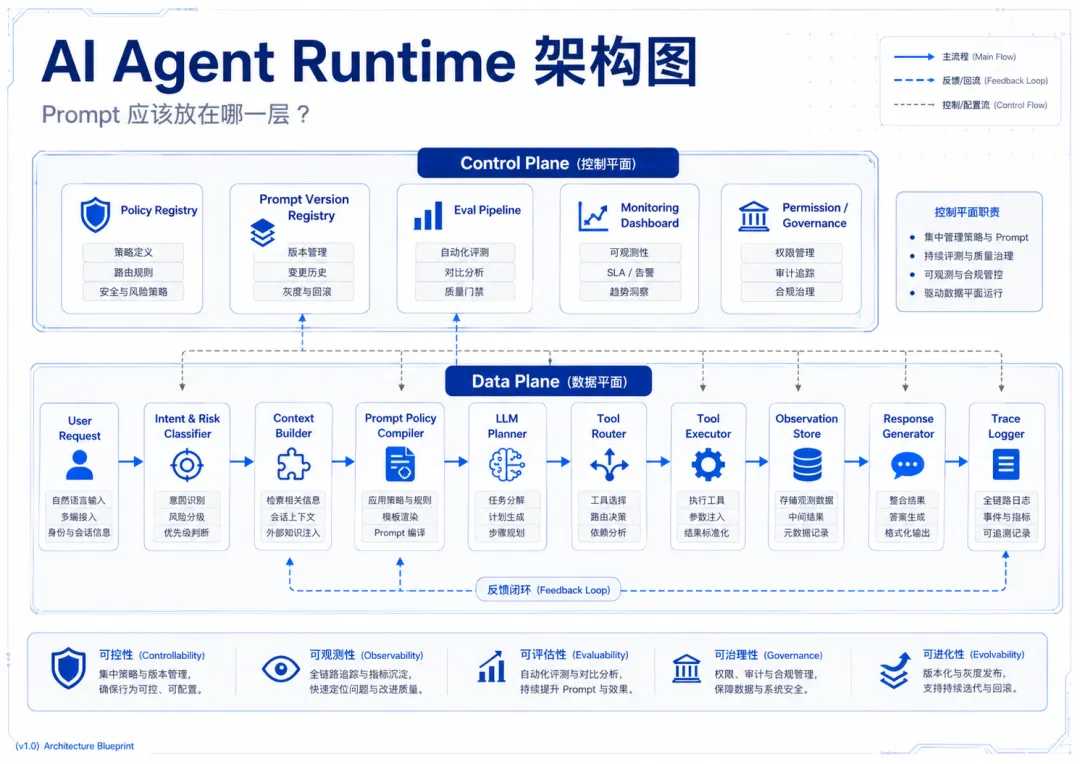
图4 AI Agent Runtime 架构图:Prompt 应该被放进控制平面管理
这里最关键的是Prompt Policy Compiler。它不是简单拼字符串,而是根据当前任务动态组装策略:基础策略、任务策略、风险策略、工具策略和输出契约会被组合成一次可追踪的 PromptBundle。
def compile_prompt(request, user_state, tool_registry, policy_registry):risk_level = classify_risk(request)task_type = classify_task(request)base_policy = policy_registry.get("base_agent_policy")task_policy = policy_registry.get_task_policy(task_type)risk_policy = policy_registry.get_risk_policy(risk_level)tool_policy = build_tool_policy(tool_registry, task_type)output_contract = policy_registry.get_output_contract(task_type)return PromptBundle(system=[base_policy.hard_constraints,task_policy.decision_rules,risk_policy.approval_rules,tool_policy.usage_rules,output_contract.format_rules],context=build_context(user_state, request),metadata={"task_type": task_type, "risk_level": risk_level})
这才叫工程化。不是把一大段提示词写死在代码里,而是把prompt 拆成可组合、可追踪、可评估、可回滚的 policy modules。
四、日志系统要记录Trace,不是只记录聊天记录
很多团队说自己有日志,其实只是存了user message 和 assistant message。这不够。
Agent 日志应该是 trace。要观察的不是最终回答,而是 Agent 的行为轨迹:模型看到了什么、做了什么决策、调用了什么工具、工具返回了什么、最终答案基于哪些证据、成本和延迟是多少。
{"run_id": "run_20260510_001","agent_id": "research_agent","prompt_version": "research_agent_v1.4.2","model": "gpt-x","input": {"user_message": "...","context_refs": ["doc_1", "doc_2"],"compiled_prompt_hash": "sha256:..."},"steps": [{"step_id": 1,"type": "llm_plan","decision": {"need_tool": true,"tool_candidate": "web_search","reason": "question requires current external information"}},{"step_id": 2,"type": "tool_call","tool_name": "web_search","status": "success","output_ref": "obs_002"}],"metrics": {"total_tokens": 4820,"tool_call_count": 1,"total_latency_ms": 3680,"cache_hit": true}}
字段 | 作用 |
prompt_version | 定位是哪版提示词导致的行为 |
compiled_prompt_hash | 判断实际送入模型的prompt 是否一致 |
step.type | 区分计划、工具调用、最终生成 |
decision.reason | 记录Agent 为什么这么做 |
grounding_refs | 判断最终答案是否有证据支撑 |
metrics | 做成本、延迟、缓存分析 |
企业架构研究会:专注企业科技架构研究,输出科技领域深度干货,拆解行业风口真相,拒绝浮躁,只讲落地。关注我,后续持续分享技术实战干货,想领取更多智能化架构建设的相关资料,参加更多的线上线下的技术论坛,请加以下人员进群:
|