 夜雨聆风
夜雨聆风上一篇讲的是上下文工程的策略:什么该注入、什么该压缩。这篇进入 结构层,拆解模型最终看到的具体数据结构和拼装方式。
要真正看懂 Claude Code,先得回答一个问题:它这一轮到底把什么送进了模型?
只有把模型眼前的输入结构理清,后面的 skill surfacing、tool prompt、MCP instructions、hooks、system reminders 才有落点。
所以这一篇不再讨论策略,而是直接看进入模型前的那套结构。
系列回顾:
先把输入结构抓住
Claude Code 送进模型的,是一整组共同组成当前输入的内容:system prompt 主体、用户上下文、系统上下文、当前消息链、工具暴露面、skill 暴露面、MCP 指令,以及各种 system-reminder 和 attachments。
system prompt 是分区拼装出来的
在 src/constants/prompts.ts 里,Claude Code 的 system prompt 是按 section 去组装。
其中一个很关键的标记是:SYSTEM_PROMPT_DYNAMIC_BOUNDARY。
// src/constants/prompts.ts
exportconst SYSTEM_PROMPT_DYNAMIC_BOUNDARY =
'__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'
在 getSystemPrompt() 里,大致是这样拼的:
// src/constants/prompts.ts — getSystemPrompt() 返回数组的主体结构
getSimpleIntroSection(outputStyleConfig),
getSimpleSystemSection(),
outputStyleConfig === null || outputStyleConfig.keepCodingInstructions === true
? getSimpleDoingTasksSection()
: null,
getActionsSection(),
getUsingYourToolsSection(enabledTools),
getSimpleToneAndStyleSection(),
getOutputEfficiencySection(),
// === BOUNDARY MARKER - DO NOT MOVE OR REMOVE ===
...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),
// --- Dynamic content (registry-managed) ---
...resolvedDynamicSections,
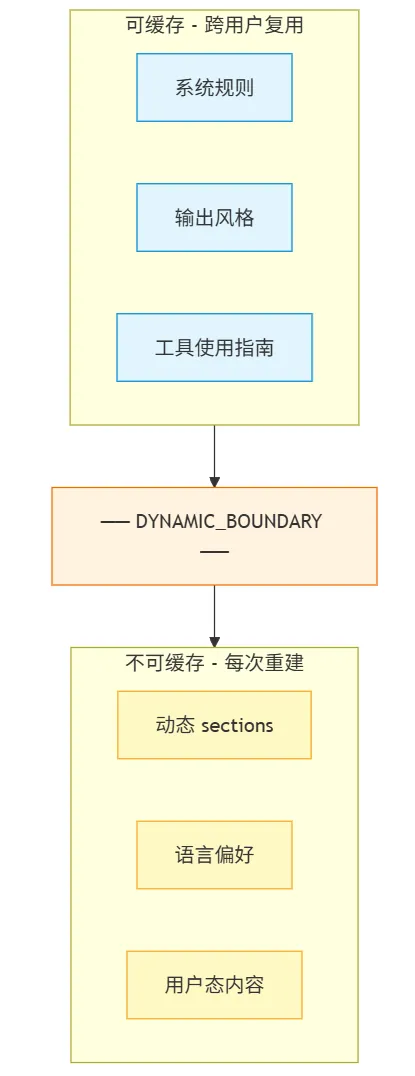
这个 boundary 的作用很直接:把可跨用户缓存的静态前缀,和每轮都可能变化的动态内容切开。
如果按当前源码再说得更准确一点,它已经不只是“为了让 prompt 结构更清楚”的分隔线了。src/utils/api.ts 里的 splitSysPromptPrefix() 和 src/services/api/claude.ts 里的 buildSystemPromptBlocks() 会直接利用这条边界,把 system prompt 切成带 cacheScope 的 block:静态前缀尽量走 global 或 org 级缓存,动态区则保持本轮重建。也就是说,这里已经不仅仅是 prompt 组织问题,而是cache-aware prefix engineering。
这层机制还有一个很现实的工程边界:如果当前 turn 里真的要把某些用户态 MCP 工具描述直接暴露进工具面,Claude Code 还会退回更保守的缓存策略,避免把本应 session-specific 的信息错误地推到跨用户缓存里。所以这条 boundary 的价值,不只是“静态 / 动态分区”,还包括让缓存边界和能力边界对齐。
一张图看懂 system prompt 拼装
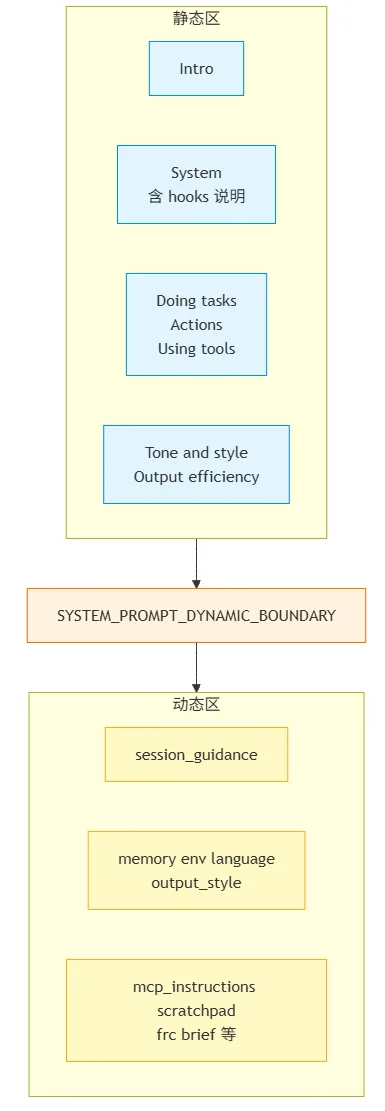
这里最容易误解的地方有两个。第一,hooks 说明不是 system prompt 之外的另一条输入通道,而是内联在 getSimpleSystemSection() 里。第二,MCP instructions 也不是额外叠在外面,而是作为 dynamic section 进入 resolvedDynamicSections。
fetchSystemPromptParts() 与 query() 之间的配合
上一篇(04)已经展示过 fetchSystemPromptParts() 的完整签名和它返回的三块结构:defaultSystemPrompt、userContext、systemContext。这里再往前走一步:fetchSystemPromptParts() 负责把这三块前缀数据取回来,真正的 systemPrompt 则是在 QueryEngine.ts 里通过 asSystemPrompt([...]) 组装好的。
这里可以顺手区分一个容易混的点:只有在没有设置 customSystemPrompt 的情况下,defaultSystemPrompt 才对应前面那套默认 system prompt 结构,也就是 getSystemPrompt() 产出的那组 section 数组。如果设置了 customSystemPrompt,源码这里返回的 defaultSystemPrompt 实际上会是空数组;但不管走哪条分支,它都还不是这一轮最终送进 query() 的完整 systemPrompt。后者还可能在 QueryEngine.ts 里继续叠上 memory prompt 或 appendSystemPrompt。
systemContext 也可以顺手单独理解一下:它不是主 system prompt 正文里的某个 section,而是和 defaultSystemPrompt、userContext 并列存在的另一层前缀数据。这样做的好处是,某些系统态上下文可以独立参与 cache-aware prefix 的构造,而不必强行并回主 prompt 文本里。
也就是说,customSystemPrompt 或 defaultSystemPrompt、可能附加的 memory prompt、以及 appendSystemPrompt,是在进入 query() 之前就已经拼完了。query() 接到的是结果,不是在里面临时再拼一遍。
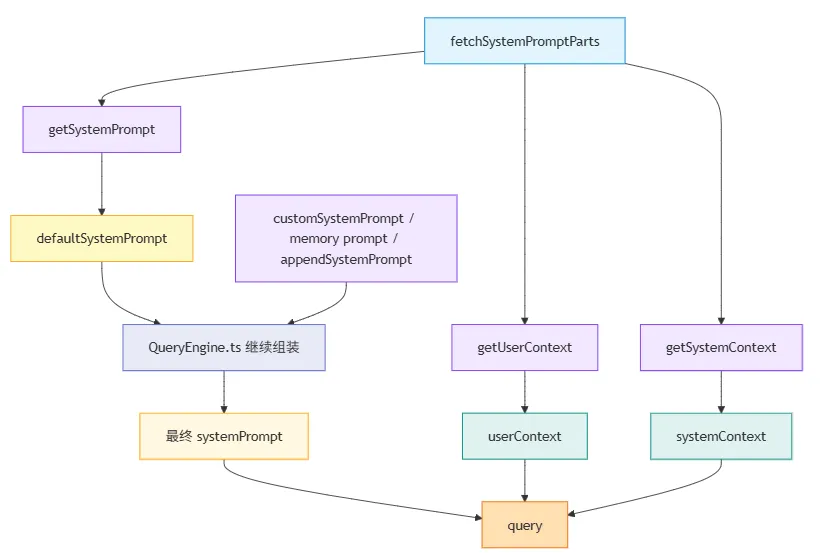
所以从结构上看,Claude Code 构造的是一个 cache-aware context prefix,而不只是一段 systemPrompt。
模型最终看到的输入结构
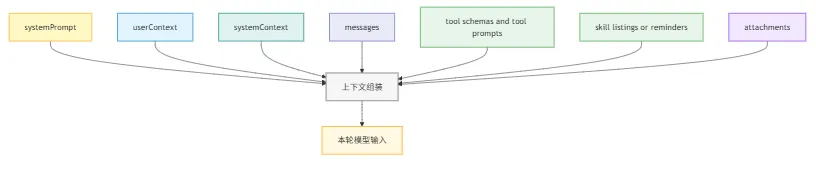
这里没有把 memory 和 CLAUDE.md 单独画成节点,是因为在这一层里,它们往往已经被吸收到 systemPrompt、attachments 或其他注入块中。这张图关注的重点不是“所有来源的总览”,而是请求真正发出前,模型当前这一轮实际看到的输入面。
这张图想表达的其实很简单:Claude Code 的输入是“多层输入面”,不是单一 prompt。像 skill listings or reminders 这一类内容,很多时候也是通过 system-reminder 或 attachment 进入模型视野,而不是直接写死在主 system prompt 里。
tool prompt:模型为什么知道可以调用什么
Tool 在 Claude Code 中不是简单函数,它是一套正式契约。
src/Tool.ts 主要定义的是工具协议、执行上下文、权限相关类型,以及工具运行时共享的状态。真正面向模型的工具说明,通常分散在各工具自己的 prompt.ts 或相邻实现文件里,包含名字、输入 schema、description,以及必要的调用约束。
再往下一层看,工具并不是把实现代码直接暴露给模型,而是先被整理成一份模型可读的工具定义。在 src/utils/api.ts 里,Claude Code 会把工具转换成 name、description、input_schema 这样的结构,其中 description 来自 tool.prompt(...),input_schema 则来自 inputSchema 或 inputJSONSchema。真正随请求一起发给模型的,是这份序列化后的 tool schema,而不是 TypeScript 里的工具实现本体。
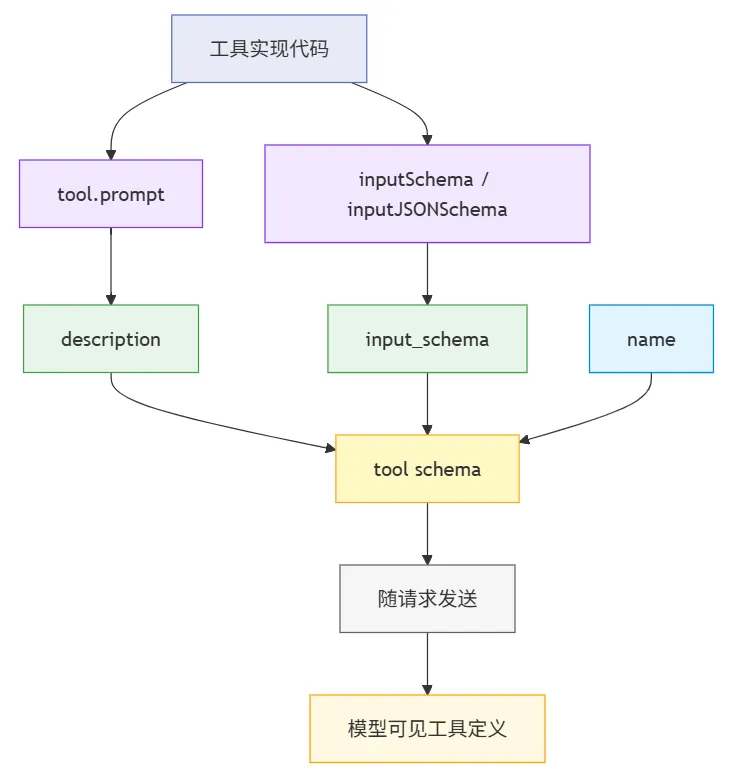
所以,模型能不能正确使用工具,关键不只是工具有没有实现代码,还取决于这些能力是怎样暴露给模型的。
skill prompt:模型如何看见高层工作流
src/tools/SkillTool/prompt.ts 值得看,不过最好把两层东西分开看。
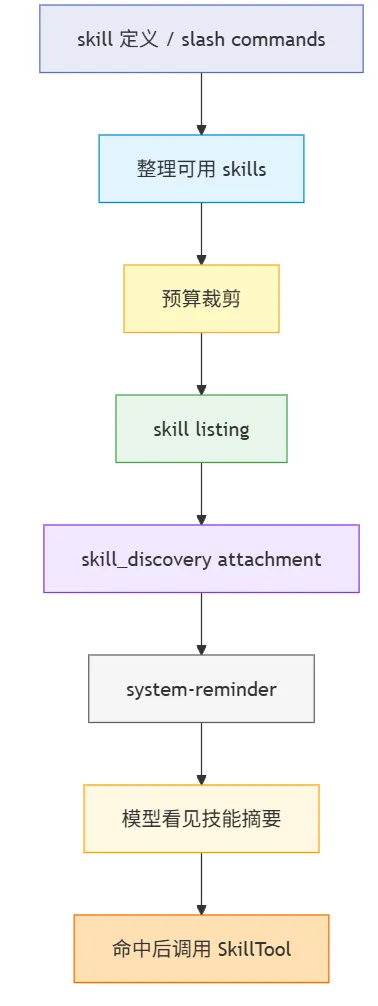
一层是 SkillTool 自己的使用说明:slash command 本质上也是 skill,一旦命中,就应该先通过 SkillTool 调用。另一层才是 skill listing 的预算控制逻辑,比如 SKILL_BUDGET_CONTEXT_PERCENT、MAX_LISTING_DESC_CHARS 这些参数,用来限制技能列表暴露给模型的长度。
这里的 skill listing,可以把它理解成“给模型看的技能目录页”,而不是技能正文。它通常只保留 skill 名字、简短 description、必要时再带一点 when-to-use 信息,作用是让模型先知道“当前有哪些技能值得考虑”。真正的 skill 全文只有在命中之后,才会通过 SkillTool 进一步加载;而 SkillTool 自己那段 prompt,负责的是教模型怎么调用 skill,而不是充当技能目录本身。
不过,当前 turn 里真正给模型看的技能列表,并不是硬编码在这段 prompt 里,而是先从当前可用的 skill / slash command 中整理出候选项,再经过预算裁剪,最后通过 skill_discovery 这类 attachment 转成 system-reminder 消息注入会话。SkillTool 的 prompt 更像是在告诉模型:当你已经看见某个 skill 之后,该怎样调用它,而不是负责把全部 skill 内容原样塞进上下文。
从源码链路上看,这件事大致分两步。第一步是在 src/tools/SkillTool/prompt.ts 里把 skill 列表压成预算内的 listing;第二步是在 src/utils/messages.ts 里把 skill_discovery attachment 包装成 Skills relevant to your task: 这样的 system-reminder 文本。模型真正看见的,是这个 reminder 里的技能摘要,而不是技能文件全文。
skill / tool 暴露面为什么要控制预算
因为模型上下文窗口是稀缺资源。
如果把全部技能、全部工具、全部说明都完整塞进去,会直接伤害主任务上下文。
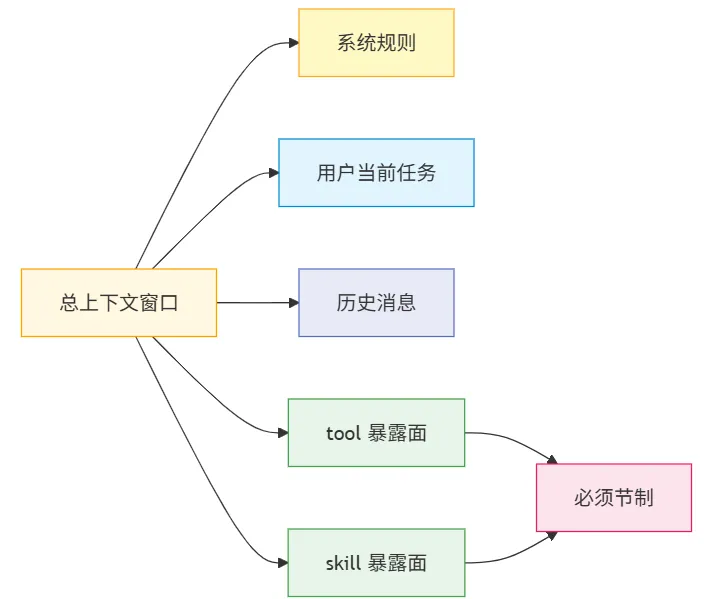
Claude Code 的做法很直接:先让模型知道“有哪些能力可用”,具体细节等真正调用时再展开,而不是在 turn 1 就把所有说明一口气塞进去。
这就是一种很典型的 budget-first 设计。
system reminders 与 hooks 为什么也重要
在 Claude Code 里,很多系统级约束并不都写在主 system prompt 里,还会通过 <system-reminder> 标签、hooks 返回信息,以及某些 runtime 附加块进入模型输入。像 skill surfacing 这类能力暴露,本身就经常走这条通道。
这些信息虽然不一定都属于“静态 system prompt”,但依旧会进入模型可见输入,影响其行为。
这也是为什么不能把 prompt 理解成单一字符串。
从架构角度看,这其实是在做“输入表面设计”
Claude Code 不只是组织 prompt 内容,它还在设计输入表面:哪些信息应该长期驻留,哪些信息只在当前 turn 出现,哪些能力以 listing 形式先露出入口,哪些内容要等真正调用时再完整展开。
从这个角度看,它做的已经不只是 prompt engineering,更像是在设计一层 agent 的输入界面。
一个典型例子:一轮请求真正送进模型的是什么
假设用户这一轮输入的是:
“帮我看一下
src/query.ts里为什么 tool 调用没有按预期工作,先不要改代码。”
在真正发请求之前,Claude Code 组织出来的内容大致会像下面这样。注意,这里不是源码里的原始对象逐字输出,而是把同一轮里模型真正会看见的几层信息,按文章前面的结构摊开成一个直观示例。
[systemPrompt]
- 由 getSystemPrompt() 拼出来的默认 sections
- 可能包含语言偏好、memory prompt、appendSystemPrompt 等追加内容
- 包含工具使用规则、输出风格、system reminders 相关说明
例如进一步展开时,里面可能会包含:
- Intro / System / Doing tasks / Actions / Using your tools
- Tone and style / Output efficiency
- __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__
- dynamic boundary 之后的 language / memory / output style / MCP instructions 等动态 sections
[userContext]
- 当前工作目录
- 平台 / shell / git 状态
- 其他与用户当前环境有关的上下文信息
例如可能是:
- Primary working directory: ...
- Is a git repository: true
- Platform: win32
- Shell: bash
[systemContext]
- 某些独立挂入 cache-aware prefix 的系统态上下文
它不是主 `systemPrompt` 正文里的某个 section,而是和 `defaultSystemPrompt`、`userContext` 并列存在的一块系统态上下文。后续发请求时,这几块会一起参与模型输入的组装。
例如可以把它理解成:“系统额外补给这一轮的一小块背景信息”。比如某些需要独立挂进去的运行态系统信息,就更适合放在这里,而不是直接改写主 `systemPrompt` 的正文结构。
[messages]
- user: “帮我看一下 src/query.ts 里为什么 tool 调用没有按预期工作,先不要改代码。”
- 可能还带有这一轮之前保留下来的必要历史消息
如果前面已经有上下文,这里通常不会只剩一条 user message,而是会带上必要的 assistant / user 历史片段。
[tool schemas and tool prompts]
- Read / Grep / TodoWrite / AskUserQuestion ...
- 每个工具都以 name + description + input_schema 的形式提供给模型
例如:
- Read: 读取文件内容
- Grep: 搜索代码内容
- AskUserQuestion: 在需要澄清时向用户提问
[skill listings or reminders]
- 如果当前任务命中了某些 skill,会以 system-reminder 的形式告诉模型:有哪些 skill 值得考虑
这里给模型看的通常是 skill 摘要,而不是 skill 全文,例如:
- Skills relevant to your task:
- - debug-ts-errors: 用于排查 TypeScript 报错
- - investigate-tooling: 用于分析工具调用链路
[attachments]
- 例如用户 @ 引用的文件、skill_discovery、某些运行时附加块;而 memory 也可能走 prompt 注入路径
也就是说,有些补充信息会以 attachment 进入会话,有些则会走 prompt 注入路径,这两条路径最后都会影响模型当前这一轮看到的输入面。
如果把它再压缩成一句话,这一轮真正送给模型的不是一句“请帮我调试”,而更像是:
你是一个带有固定系统规则、当前环境信息、历史消息、可调用工具定义、可见技能摘要和附加上下文块的 agent;现在请基于这些输入,处理这条用户请求。
这也是为什么 Claude Code 的行为看起来不像“只靠一段 prompt 在工作”。模型做判断时,看到的是一整个已经组装好的输入界面,而不是一条孤立的用户消息。
源码锚点
可以重点看:
src/constants/prompts.tssrc/utils/queryContext.tssrc/utils/api.tssrc/utils/messages.tssrc/Tool.tssrc/tools/SkillTool/prompt.tssrc/query.ts
结语
本篇重点: Claude Code 如何把“输入”做成了一套结构化、可裁剪、可缓存、可扩展的系统。
动手练习
打开 src/constants/prompts.ts,搜索SYSTEM_PROMPT_DYNAMIC_BOUNDARY,看它上下分别有哪些 section搜索 getUsingYourToolsSection,看工具使用指南是怎么被拼进 system prompt 的打开 src/tools/SkillTool/prompt.ts,看 skill listing 的预算控制逻辑
