 夜雨聆风
夜雨聆风当“414.7亿”这个数字出现在屏幕上的时候,整个实验室都沸腾了。
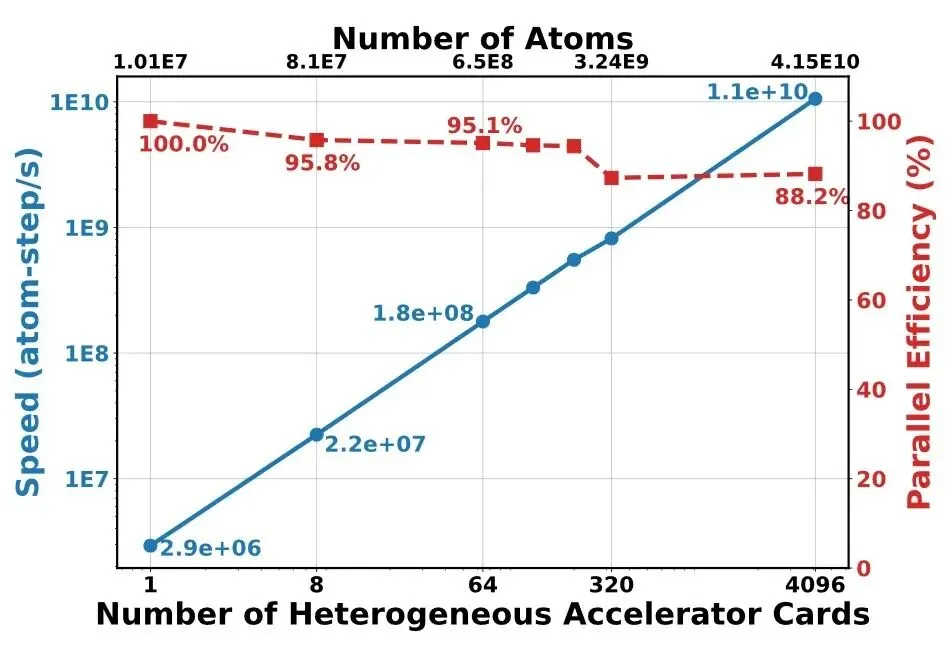
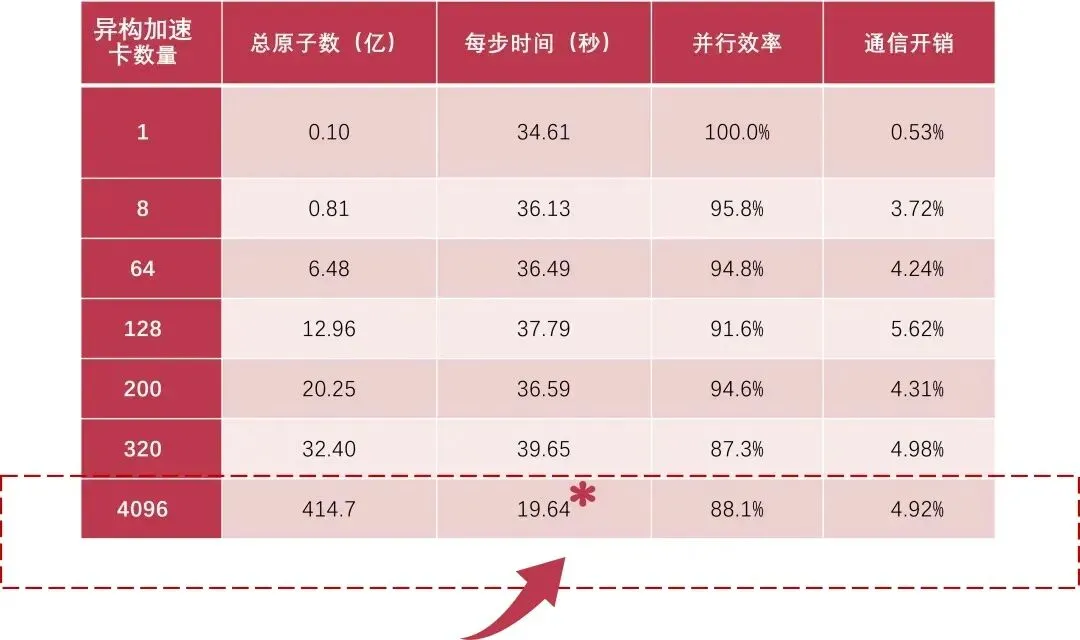
这不仅仅是一个枯燥的统计数字,它代表着人类首次以第一性原理级的超高精度,在接近真实尺度的微观世界中,成功完成了414.7亿原子规模液态水分子的动力学模拟。更令人振奋的是,完成这一壮举的,是一支纯国产的“梦幻组合”:由中科曙光提供的scaleX万卡超集群,与龙讯旷腾的MatPL-2026.3软件,在国家超算互联网核心节点上携手,将此前由他们自己创造的290亿原子世界纪录,一口气提升了43%。
在机器学习力场(MLFF)这一科学计算前沿赛道,中国力量再次站上世界舞台中央!这一突破,不仅让全球目光再次聚焦中国科研,更为“AI for Science”的战略布局,提供了坚实硬核的实践支撑。
MatPL:
打开量子世界大门的“万能钥匙”
在深入了解这次破纪录背后的技术攻坚之前,我们有必要先认识一下本次的主角之一:MatPL软件。
如果以我们非专业人士的视角来看,MatPL则显得非常神秘,因为大部分人可能都是首次接触到它。通俗地讲,MatPL是龙讯旷腾自主研发的机器学习力场(MLFF)开源软件包,是AI与材料科学深度融合的核心计算工具。它广泛应用于多晶材料、先进半导体制程、固态电池界面、合金设计、生物大分子等前沿科研与产业场景。MatPL通过学习第一性原理高精度数据构建模型,兼顾了量子级计算精度与分子动力学的超高模拟效率,破解了材料计算领域“精度与规模不可兼得”的行业痛点。
MatPL-2026.3 最新版本在训练效率、并行能力、内存优化上实现全面突破,打破跨节点并行的行业瓶颈,成为本次 414.7 亿原子规模世界纪录模拟的核心软件基石。
突破千卡异构并行计算痛点
scaleX万卡超集群绝非算力硬件的简单堆砌,而是一套从底层芯片架构到上层软件适配全链路深度重构的算力系统。
本次世界纪录级模拟的实测数据给出了最直观的印证:在4096张异构加速卡全并行运行的场景下,集群整体通信开销仅占4.92%,核心计算占比始终稳定在90%以上,同时实现了高达88%的弱扩展效率。近乎线性的扩展表现,不仅保障了本次超大规模模拟的顺畅完成,更意味着即便后续集群扩容至十万卡级别,算力效能也不会出现大幅衰减,为冲击更高量级原子模拟预留了充足空间。
本次刷新世界纪录,也体现了国产软硬件从技术适配、团队协同到平台赋能的全链路深度融合,而非单一环节的单点突破。双方团队不仅基于MatPL软件的核心计算模块,创新性地应用AI芯片的TensorFloat-32算力,将多精度计算的优势发挥到极致,更通过对编译器、数据库等全栈技术的协同优化,让开发者无需编写底层代码,就能充分调用硬件的全部性能潜力。
“懂行”让国产团队在世界站稳脚跟
对于此次国产算力适配的初衷与落地价值,北京龙讯旷腾科技有限公司总经理田洪镇表示,推进国产算力适配,既是应对国际算力封锁的必然选择,也看重其落地可行性与长期产业价值。中科曙光提供的专业转化工具,可将MatPL软件原本基于GPU开发的架构,顺利适配至曙光X86与DCU卡架构,大幅降低了跨平台适配成本;而适配落地后,无论是联合打造软硬件一体化解决方案,还是依托超算互联网架构优化算力服务,都形成了正向循环。优质算力能显著提升软件使用体验,软件的普及应用也能进一步释放国产算力的核心价值,最终实现软硬件双向共赢。
而这套深度适配能够高效落地,离不开“懂行”团队构建的高效协同机制。中科曙光解决方案与创新业务总经理张磊介绍,双方团队均拥有深厚的材料物理专业背景,极大降低了跨领域沟通成本,能够面对面快速对齐算法优化方向与硬件架构优势,形成了高效联动的协同研发机制,为本次技术突破提供了核心保障。
从能用到好用的“质变”时刻
此次414.7亿原子模拟的破纪录成果,既印证了龙讯旷腾与中科曙光这对国产软硬件“黄金搭档”的强大实力,在AI for Science赛道跑出了令世界瞩目的中国速度;也打通了算力赋能真实科研的落地链路:700多纳米的模拟尺度已能覆盖合金界面、半导体器件、固态电池等前沿领域的真实场景,为科学家提供了原子级精准研发的核心工具;更推动覆盖“算法-算力-应用”全链条的自主科学计算生态初具雏形,未来通过智能体等轻量化入口还将进一步降低使用门槛,为高端算力的普惠化铺平了道路。
长
按
关
注
计算杂谈公众号
专业,创造价值!
与你分享来自科技的乐趣。

【计算杂谈】创办人吴丛丛,笔名云中子,先后任职于走进中关村、赛迪网、51CTO、比特网,从业20多年来重点专注服务器、存储、云计算、数据中心、网络、 虚拟化、安全、半导体、消费数码等相关领域。计算杂谈网站已上线,敬请关注!www.jisuanzt.com

