 夜雨聆风
夜雨聆风一、知识库构建:文档切片
1.1 核心定义
文档切片是知识库构建的核心预处理步骤。通过将长文本内容切割为语义独立的小片段,以适应大语言模型(LLM)的上下文窗口长度限制,从而显著提升后续知识检索的精确度与响应效率。
1.2 三种切片方式
方式一:按字符数切分
规则化切分
:设定固定长度阈值(如每300字符为一段)
特点
:规则简单,执行效率高
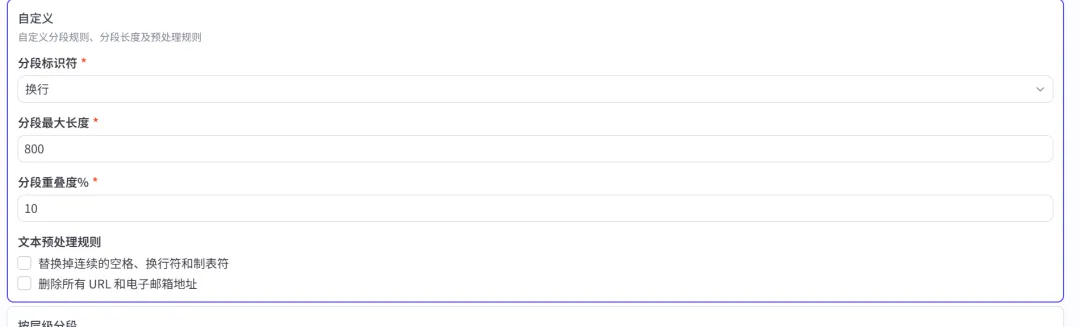
方式二:按标点符号切分
语义连贯性
:依据句号、换行符、感叹号等自然停顿点
特点
:更好地保证每一段文本的语义完整性
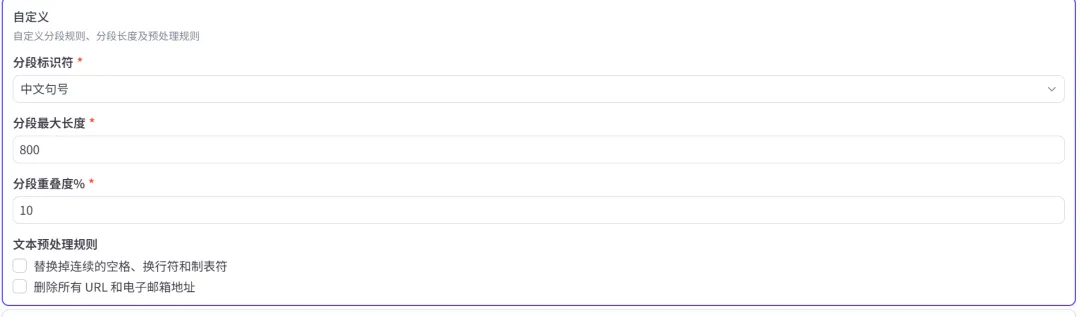
方式三:按语义智能切分
AI智能识别:通过模型识别主题变化点进行动态切割
特点
:最推荐的进阶方式,能最大程度地保留完整的语义单元,显著提升后续检索问答的精确度
方式五:按层级切分

二、知识库构建:文档向量化
2.1 文档向量化定义
将切分后的文本片段,通过深度学习模型(如BERT、Word2Vec)转化为高维空间中的数值向量。这一过程实现了非结构化文本的结构化表达,便于后续算法高效计算用户问题与知识库文档之间的语义相似性。
2.2 核心逻辑原理
核心在于"数值化":把万事万物(文本、图像等)映射为一串数字。计算机无法直接理解文字语义,但可以通过计算这串数字在高维空间中的"距离",来量化它们之间的相似度,从而实现智能化的匹配、检索与推荐。
2.3 向量化的三大核心作用
深度语义理解
:将非结构化文本转化为机器可理解的数值,捕捉深层含义
精准相似度计算
:基于向量空间距离算法,快速匹配相似内容或用户群体
毫秒级快速检索
:在海量数据中通过向量索引,实现比传统关键词更快的查找
2.4 实例说明:购物习惯的三维向量化
假设我们用三个维度来描述一个人的购物习惯:爱吃零食、爱买书、爱熬夜。
小明·典型宅男
:[9, 2, 8]
小红·超级学霸
:[1, 9, 1]
小刚·游戏宅男
:[8, 3, 9]

通过解析这些多维向量数值,计算机能瞬间计算出个体间的相似度(如小明&小刚高度相似),并快速识别差异化特征(如与小红差异显著)。
三、LLM与RAG技术
3.1 LLM(大语言模型)
基于Transformer架构和海量语料训练而成的深度学习模型,相当于一位博学但已经断网的专家。
3.2 RAG(检索增强生成)
一种结合了非参数化记忆与LLM的混合结构,简单说就是一种利用资料库的工具,为博学的人配了一本"外挂资料书"。
3.3 核心价值
二者结合,让AI回答从"闭卷考试"变为"开卷作答"。
3.4 传统LLM的缺陷
消息滞后(无法获取最新的知识)
知识库更新不及时
容易产生幻觉
3.5 RAG的原理
先将用户问题基于知识库检索相关上下文,再将"问题+上下文"结合送入大模型生成精准回答。
3.6 RAG解决的问题
有效解决大模型的"幻觉"问题
提升答案的准确性和时效性
降低知识更新成本
四、Function Call功能
4.1 解决的问题
信息实时性
大模型的知识库具有滞后性,无法包含最新的实时信息。通过Function Call可即时调用外部接口,获取最新的数据动态。
数据局限性
模型无法覆盖企业私有库或垂直领域的海量数据。通过Function Call可灵活调用外部数据库或API,拓展数据获取边界。
功能扩展性
模型不可能内置所有复杂功能。通过Function Call可将特定任务(如计算、绘图)"外包"给专业工具,轻松扩展模型能力边界。
五、从理论到实践
深入探索Coze平台核心功能,开启沉浸式实操演练。理论知识我们已经了解得差不多了,接下来让我们进入实践环节,看看如何在Coze平台上真正运用这些知识。

本团队拥有多名硕博研究生以及实战经验丰富的开发工程师,精通但不限于Java、Python、PHP、Go、HTML、CSS、JavaScript等各种编程语言,能快速完成人工智能模型训练与应用,网站、小程序、数据爬取、软件定制开发。详细业务介绍如下:
AI赋能千行百业
人工智能模型复现、训练,包括但不限于YOLO、DETR等;
Agent智能体开发,各类工作流定制(coze/n8n),例如:coze工作流一键生成简历、在线AI辅导员、一键生成历史人物视频介绍等;
将AI接入中小学、大学等各类课程教学,例如一键生成动画讲解古诗词、在线网页讲解各类算法等;
基于openclaw的各类应用二次开发;
AI 赋能千行百业,你能想象出来的AI应用,我们都能帮您变为现实;
传统软件开发
小程序:各类小程序及配套管理系统研发;
移动端、PC端网站开发:各类移动端(手机上看的)、PC端(电脑上看的)网站及配套管理系统
数字孪生、大屏数据展示系统
软件定制:各类小工具开发(你能想象到的都能做)
web3:区块链方向各类应用开发,例如“基于联盟链的产品溯源管理系统”
数据采集:各种爬虫的编写,数据采集、分析、数据可视化

