 夜雨聆风
夜雨聆风
你有没有觉得,和AI说话总是怪怪的?
不是内容的问题,是节奏的问题。你说一句,它顿一下,再回一句。这中间总有一个让人不太舒服的空白。你说话的时候吧,也不知道它听没听进去;它回你的时候呢,好像也顾不上看你正在干嘛。
说来说去,就是不大像真人聊天。真人聊天是什么样?一个“嗯”就表明在听了,一句“你说呢”就接上了话,一个眼神就切换了话题。但现在的AI,多少差点意思。
这种感觉,不是你的错觉,是底层技术逻辑决定的。好在,有人受不了了。
AI学会了“一心多用”:能插嘴、会“嗯嗯”、秒回不算事
五年多前,《Her》里那个只有声音的西奥多,跟着男主角上班、讲段子、偶尔还吃个醋,成了无数人心中的“白月光”AI。五年后的今天,一个名叫Mira Murati的80后女性带着她自己的团队,终于把这个“白月光”从电影拽进了现实。

5月11日下午,前OpenAI CTO(首席技术官)Mira Murati创办的新公司Thinking Machines,正式拿出了他们的第一款作品——TML–Interaction–Small。
名字有些长,但你只要记得它是原生多模态交互模型就够了。所谓“原生多模态”,简单理解就是AI从娘胎里就会看、会听、会说,还能无缝来回切换。
这就好比你去驾校学车,那叫后天补习。而“原生”的意思是,它一生下来就自带赛车手的本能肌肉记忆。
所以当你跟它聊天,你根本察觉不到它是在“想”,还是在“说”。因为它的思考可能和你的一道指令交叉进行,它那种特别像真人的打断和接话,也完全不需要外面那层“工程外壳”。
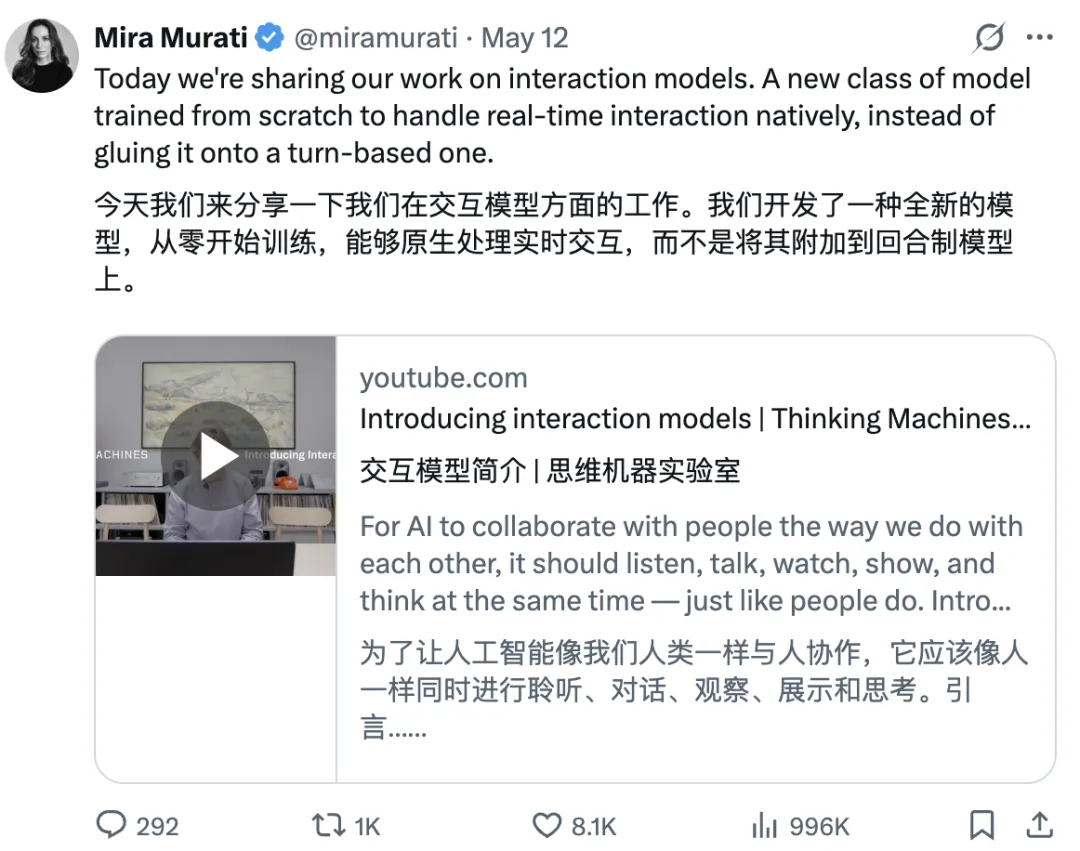
怎么做到的?Thinking Machines把对话切成了200毫秒一个的微回合。什么概念?差不多就是人类眨一下眼睛的时间。在这200毫秒里,模型不断接收你的声音、画面,同时也在不断往外吐字。
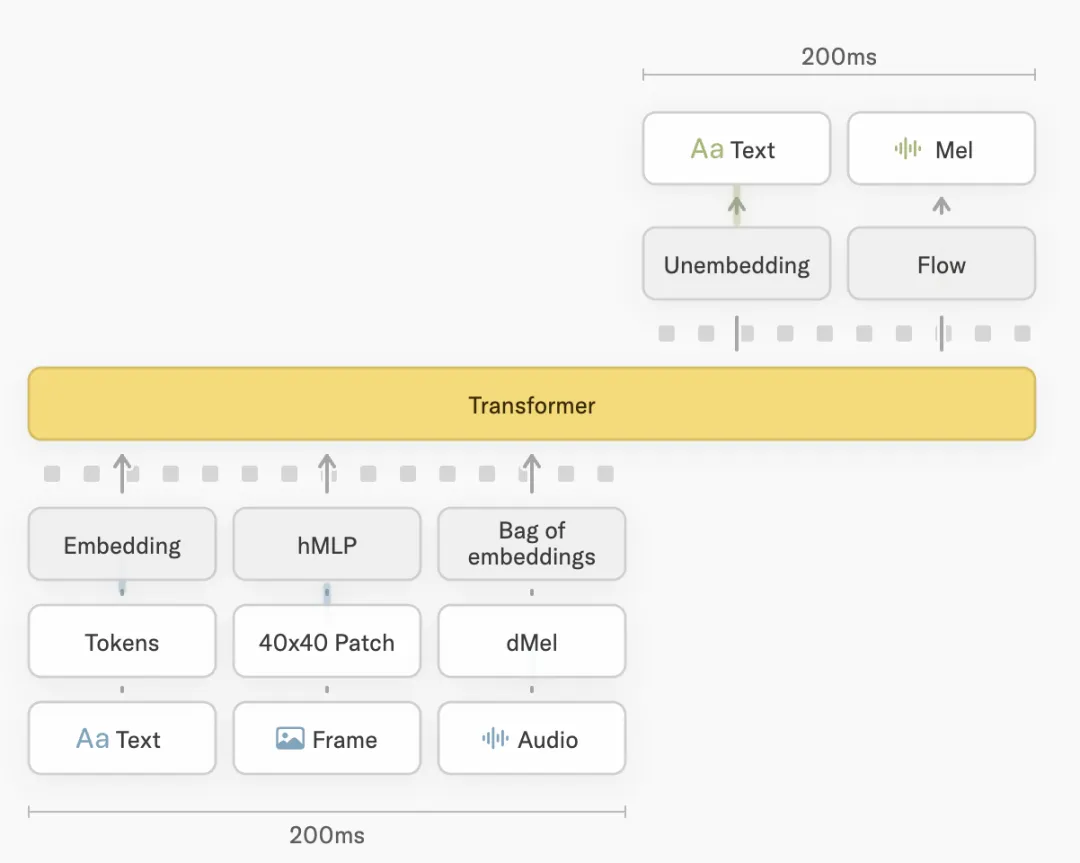
更妙的是,Thinking Machines的设计里还加了全双工通信。全双工这个技术以前是用在电话上的——两边可以同时说话,不用等对方说完。
那在AI身上是什么样呢?联合创始人翁荔在官方演示视频里亲自做了解释:
当你对着电脑摄像头做一个俯卧撑,AI会在旁边同步数一个数;当你写代码时不小心打了个空格,它会立刻出声提醒“这里多了个空格”;当你说话偶尔卡壳或者深呼吸,它的“嗯”、“哦”、“我明白”也会在这些关键时刻自然出现。
这不就是人和人之间那种默契吗?
数据上也没含糊。根据Thinking Machines Lab在5月11日发布的技术博客,TML-Interaction-Small在FD-bench V1里的单次回应延迟只有0.40秒。你们要知道谷歌的Gemini-3.1-flash-live是0.57秒,而OpenAI的GPT-realtime-2.0在最小模式下都达到了1.18秒。与此同时,在FD-bench V1.5里它的综合评分是77.8,直接比GPT多了31分。
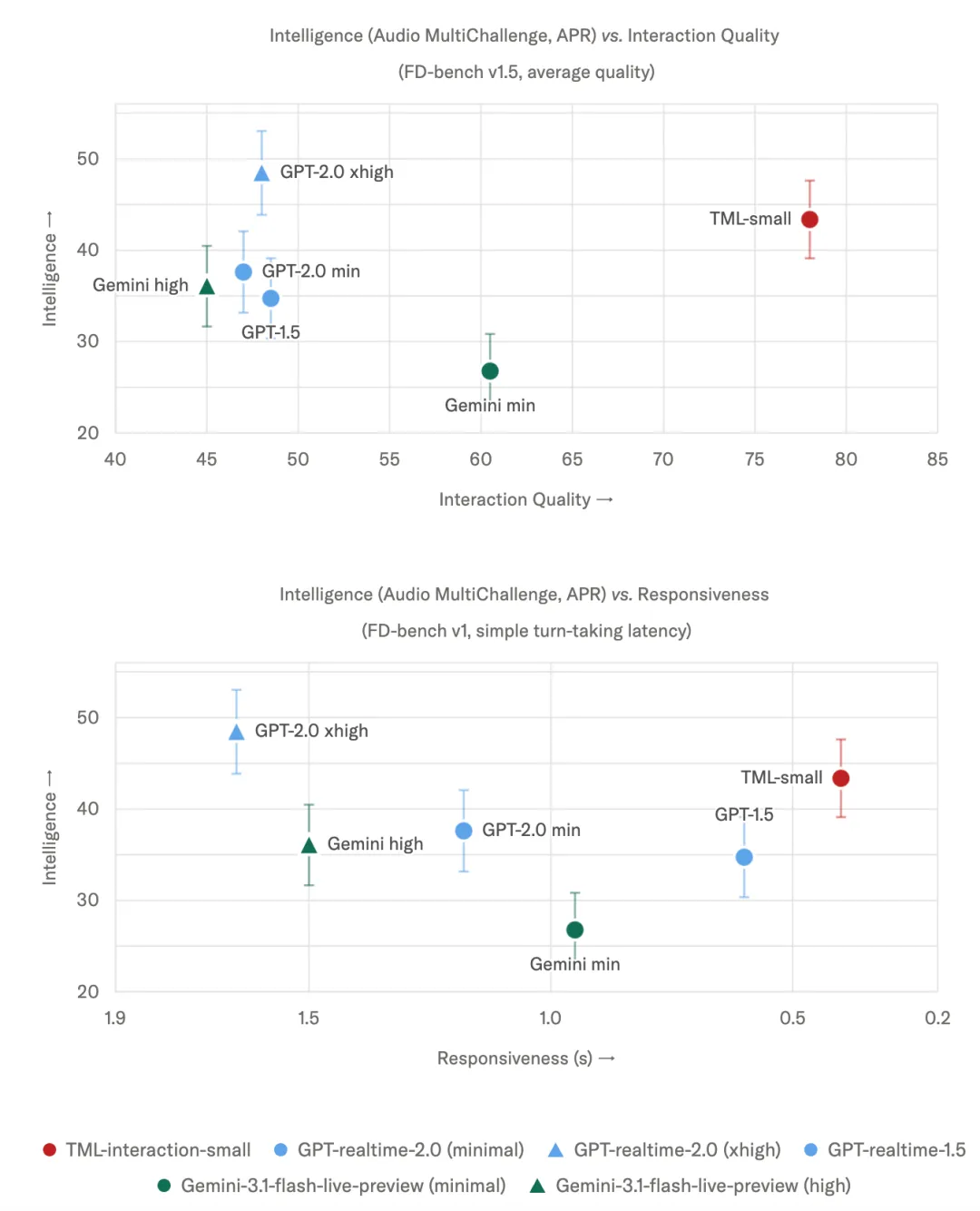
这简直是降维打击。
大脑分两层:一边陪你唠,一边干正事
那问题来了,聊得飞起的AI,还有能力干正事儿吗?
比如,你一边聊着“帮我订一张明天去上海的机票”,一边突然插嘴“哦对了,我晚饭也想吃点儿好的”,它能立刻调用后台软件查找航班,同时继续跟你聊美食推荐,而且两项任务互不干扰吗?
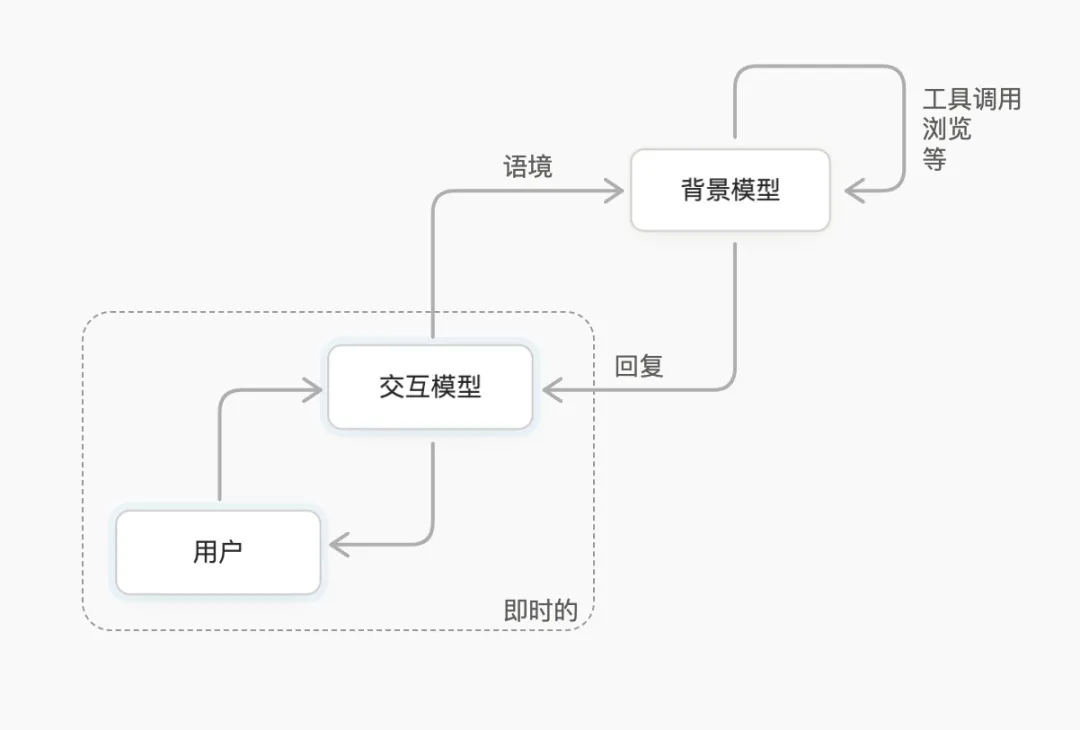
别人不行,这次可能还真行。因为TML-Interaction-Small的核心,是双模型架构。
Interaction Model:
也就是前台和你对话的这个“人”。负责察言观色、管理节奏、给出快速反应。它不需要大动干戈地调用所有脑力,只需要维持在底层,伴你左右。
与此同时,藏在后台的那个“同事”—— Background Model(后台推理模型),才是真正干苦力活的。
后台模型看到任何需要深度推理、多步规划或者调用搜索工具的任务,比如你问“帮我预测今年夏天巴黎的出行人数”,它会默默开始算。要知道这种事儿如果让一个普通大语言模型做,你得在外面添加插件,或者等着“正在搜索中……”,体验非常割裂。
而现在,你甚至完全感觉不到后台模型已经启动了。因为你们的对话没断,前台的互动模型就在那自言自语一样地把其他话题接着聊下去。等到后台算完了,再把结果轻描淡写地交回前台,由前台无缝嵌入到你们的对话中。
另一个被官方和媒体反复提及的突破,是无编码器早期融合。
以往的AI处理音频和视频,得像包饺子一样,用Whisper这类编码器把音频“翻译”成模型能懂的语言。这就多了一道工序,也多了层延迟。
但TML-Interaction-Small彻底跳过了这步,直接用轻量级嵌入层吸收原始音频信号和图像方块。
所以延迟是实打实降下来的,感知是实打实连通的。它看视频和听人说话,对人来说是同一种直觉。——这可能就是Thinking Machines能够轻松做到“只要发现你驼背就出声提醒”这类主动行为的根本原因。
告别回合制,这不是“快一点”的问题
你可能会觉得,这不就是个“更快的AI”吗?不是的。表面上来看,它只不过是快了几秒。但在底层,它改变的是我们跟AI协作的全部规则。
以前的AI交互,本质上是“回合制”。你说一句,它回一句,中间隔着一道墙——你说的时候它听不到,它说的时候你插不进去。回合制的最大问题不是慢,是它让人被迫“迁就”机器。我们必须把话说完、把问题敲完整、把思考打包好,然后一次性扔给AI。为什么?因为你一打断,上下文就断了。
所以我们这些年跟AI的对话,本质上不是在“聊天”,而是在“填表”。
Thinking Machines要做的事情,就是把这种“填表式”的交流,拉回到真正的实时协作。人和AI都可以随时插嘴,说完了你要做的事儿也差不多干完了。 你不再需要等待“正在生成……”,因为生成和接收是同步发生的。
所以有人才会说,这是那部电影《Her》的幽灵终于在5年后附身了新硬件——而且是更聪明的全模态硬件。不是刚好吗?Siri也12岁了,Alexa也来了,GPT的实时语音也进化到第三代了,但那种等待延迟和迟钝感,始终让它们少了点“人味儿”。直到2026年春天,Mira Murati交出的这第一份答卷,才让所有人听到了那种久违的自然呼吸声。
当然,这也并非完美无缺。官方自己承认,长时间对话的上下文管理、对稳定网络连接的依赖,以及更大参数模型的部署速度,都是下一步要攻克的难点。而且TML-Interaction-Small目前只向少数开发者开放研究预览,大众商用得再等上几个月。
但方向已经对了。
当竞争的重点从“谁更聪明”转向“谁更像人”,我们离想象中的AI助手,终于近了一步。这次,它真的随时在线,真的在看着你、听着你、等待着接话的机会。就像跟朋友聊个天那么简单。
