 夜雨聆风
夜雨聆风上篇拆了执行层——代码在哪跑、怎么跑安全。代码跑完,stdout 吐出来一坨东西。这坨东西要回到哪里?谁负责读?读完以后做什么?
这是反馈层的问题。也是这套体系里最容易被忽略、做错代价最大的一层。
去年冬天我接手一个跑了大半年的内部 Agent 系统。表面看起来很完整:Planner 出方案、Executor 跑命令、stdout 和 stderr 都进了 trace、每个步骤都有 retry。文档里画了一个漂亮的闭环图,"持续学习"四个字写得很大。
我盯着那张架构图看了十分钟,问了一句:这个 Agent 上线半年,它现在比第一天聪明吗?
会议室安静了一会。然后有人说:好像没什么变化,可能还更倾向于复用之前那几个老套路。还有人说,最近用户反馈"它有时候执行一个简单需求会绕一大圈"。
我让他们把过去三个月内 Agent 自己写进 memory 的"经验"导出来。两千多条。大半是 stdout 的尾巴、retry 的失败堆栈、被截断的报错信息、Agent 自己对自己的复盘——比如"上次这个任务花了 23 步,下次可以更高效",然后下次它真的就在第一步把这条经验当 context 喂进去了。
这就是一个典型的"反馈层做错了的系统"。它不是没有反馈,它是把所有能采集到的信息都当成反馈,结果 Agent 每次决策的 context 里塞满了过去的噪声。它确实在"学习",只是学到的全是错的东西——学到了"上次绕了大圈所以这次也要绕"、"上次 retry 三次最终成了所以这次也 retry"。它在退化,不是在进化。
执行层的命题是"代码在哪跑"。反馈层的命题——我现在的判断——其实只有一个:什么信号值得回流,什么信号必须丢掉。
反馈不是"把执行结果存起来"
很多团队对反馈层的第一直觉,是把它当成一个数据管道:执行结果 → 存储 → 下一次决策时读取。这个直觉错在哪?错在把"采集"当成了"反馈"。
采集是 IO 行为,反馈是认知行为。两者中间隔着至少三层处理:信号识别、可信度评估、回流路径选择。如果你跳过这三层,反馈层就退化成一个会越积越大、越来越脏的数据池。
CI/CD 系统的反馈链路简单得多:单元测试跑完——pass 或 fail——开发者看到红绿灯——修代码——再跑。整个链路里反馈是离散的、二元的、幂等的。同一段代码跑十次结果一样,这次的反馈不会影响下次的判断逻辑——判断逻辑由人脑承担,反馈系统只负责传递信号。
AI Agent 的反馈链路完全不是这个形状。Agent 的反馈是连续的、多维的、有状态的。同一个任务,第一次执行成功不等于第二次也会成功——因为这次执行的 trace 可能进入了下次的 prompt,改变了下次的决策概率。判断逻辑由 LLM 承担,而 LLM 的判断逻辑会被你喂给它的反馈材料改写。
这个区别带来一个非常反直觉的结论:在 AI 系统里,反馈层的设计错误,比执行层的设计错误更难发现,也更难修复。执行层错了,代码跑炸,你立刻知道。反馈层错了,Agent 静默地往一个错误方向漂移——你三个月后才发现"它好像变笨了"。
更麻烦的是,反馈层的故障没有一个清晰的"红色告警"。执行层有进程崩溃、有返回码、有超时。反馈层的失败长什么样?长得跟正常工作几乎一模一样——只是 Agent 在某个本来应该选 A 的地方选了 B,而你看不出这个 B 是不是被某条历史反馈推着选的。你只能在足够长的时间尺度上、跨足够多任务做统计,才能发现"它在退化"。这就是为什么我说反馈层是这套体系里最容易做错、做错代价最大的一层。
信号与噪声的分界线
反馈层的核心工作,是把执行后产生的一大堆"信息"切成两堆:能用的信号、必须丢的噪声。
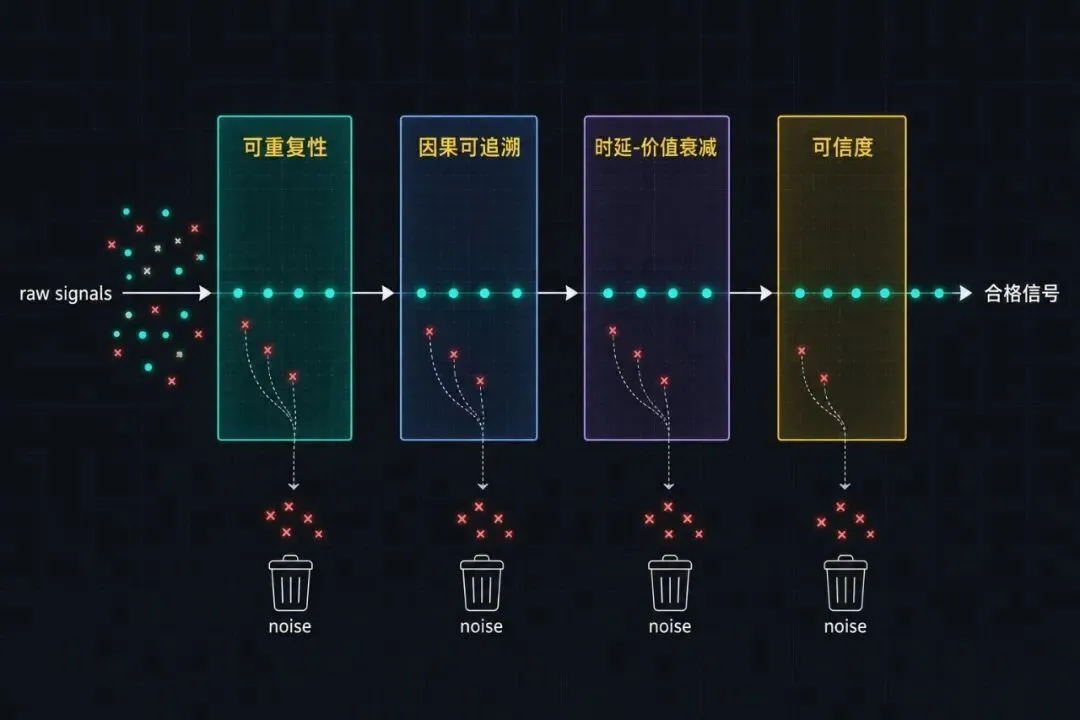
这条分界线该画在哪?我用四个维度做判断。它们彼此正交,每条信息都得过这四关。
第一关是可重复性。这个信号下次再出现的概率有多大?一次性的偶发现象——比如某次网络抖动导致的超时——价值接近零。重复出现的模式——比如"某个 API 在工作时间外总是 429"——价值很高。可重复 = 可归纳 = 能进入决策模型。不可重复 = 偶发噪声 = 必须丢,否则下次 Agent 看见正常情况都会先怀疑网络抖动。
第二关是因果可追溯。这个信号跟当前 Agent 的某个决策有没有明确的因果链?"用户最终没满意"是结果,但如果你不知道用户对哪一步不满意,这个信号回流回去 Agent 不知道该改什么。我们之前踩过的最大一个坑:把整条 trace 当反馈喂回去,Agent 在下次执行时同时调整了五个变量——你完全不知道是哪个调整起了作用,下次再失败你又没法定位。可追溯 = 单点反馈 > 总体反馈。
第三关是时延-价值衰减。有些信号只在很短的时间窗口内有价值。比如执行过程中 stdout 的实时流——它在执行当下用于"这步该不该继续"的判断价值极高,但执行结束后写进 memory 几乎没用。反过来有些信号在长时间尺度上才显示价值——比如"某类任务过去三个月平均要 retry 1.7 次",这个数字单看一次任务毫无意义,看一个季度才能用。把这两类信号同等对待,你就同时浪费了实时性和长期统计——前者来不及响应,后者被实时数据淹没。
第四关是可信度。信号本身是不是来自一个值得信任的源头?stdout 是 Agent 自己写的,相当于"自我陈述",可信度天然低。测试结果由独立测试框架产生,可信度高。用户行为(点了赞、复用了产出、永久删了文件)可信度更高。把所有信号当成同等可信,等于让 Agent 用自我陈述教育自己——这就是为什么很多系统 Agent 会越来越自信地犯同一类错误。
四关同时高分的,才是合格信号。任意一关塌方的,进反馈池就是污染。
这四关里最容易被忽视的是第三关。可重复性和可信度大家多少会想到——一次性事件不要记、自陈数据要打折,是工程常识。但时延-价值衰减这件事,大多数团队没有显式建模过。结果就是把实时信号写进了长期存储、把统计指标拿来做实时判断,两边互相干扰。我自己的经验是,反馈层最早需要拆开的就是这两个时间尺度——短的归短的,长的归长的,中间不要互相串。
三种反馈,三条回流路径
把信号筛干净以后,第二个问题是:让这些信号流回哪里?
我见过最常见的错误设计,是所有反馈走同一条管道:执行结果——一个大 memory——下次决策时全文加载。这种"一个池子装所有"的设计在系统刚上线时看不出问题,因为池子还小。三个月后池子膨胀,每次决策都要在几千条历史里翻找,token 成本爆炸,相关性反而下降。
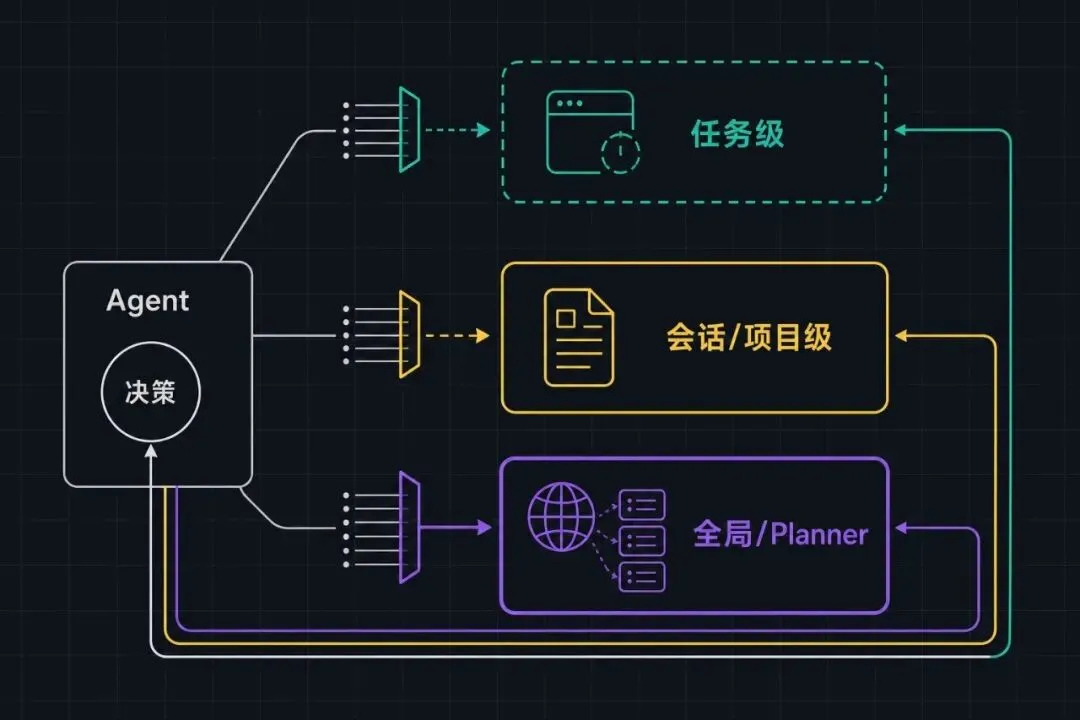
按反馈影响范围分,至少要拆成三条独立的路径。
第一条回到当前任务。这是最短的闭环,也是最高频的。Agent 跑一步,看 stdout,判断要不要继续。这种反馈的特点是即时、私有、不持久——它只对当前这次执行有用,任务一结束就该清空。在 Claude Code 这类工具里,bash 工具的输出就属于这一类——它流回当前对话的 context,但不会变成跨会话的"经验"。这条路径设计错的常见症状是:把每一步的 stdout 都写进长期 memory,结果一周后 Agent 的 context 里塞满了上周某次 grep 的输出。
第二条回到当前会话/项目。这是中等周期的反馈。比如"这个项目里我已经知道测试要用 pytest 不是 unittest"、"这个仓库的 lint 配置在 pyproject.toml 里"、"这个用户偏好简短回复"。这类反馈是"工作记忆"——它对当前会话的所有任务都有用,但不应该泄漏到别的项目去。这条路径设计错的常见症状有两种:一种是太短(每次重启从零开始,用户每次都要重新教),一种是太长(一个项目的偏好被错误地泛化到所有项目,你在另一个仓库工作时它还在用上一个项目的 lint 规则)。
第三条回到全局/Planner。这是最长的反馈,频率最低,但影响最深。它回答的是"什么类型的任务该用什么模式去做"——比如"涉及金融数据迁移的任务,先做 dry-run 再实跑"、"涉及多服务的部署,先准备 rollback 路径"。这类反馈不该是 trace 级别的,应该是抽象出来的模式。原始 trace 进入这条路径之前,必须经过一次额外的归纳处理——把具体事件抽象成可以跨场景复用的判断。
三条路径必须严格隔离。短期反馈不能污染长期模式,长期模式也不能干扰短期判断。我见过一个失败的系统,把"我刚才那一步 sed 命令打错了"这种短期信号写进了 Planner 的全局策略,结果之后所有任务都被 Planner 加了一条"先验证 sed 语法"的前置步骤——一个本来一行能搞定的任务变成五步。
一次性反馈 vs 持续反馈
反馈层的另一个深水区,是"什么算一次反馈"。
绝大多数 AI 系统的反馈模型是事件性的:任务结束——评估结果——产出反馈——下次决策时使用。这是把传统软件工程"build → test → deploy"的事件性反馈模型直接平移过来。它对短任务、确定性任务还可以——但对真正长链路的 Agent 任务,会漏掉太多东西。
举个例子。Agent 接到一个任务:"把这个数据管道从 Airflow 迁到 Prefect。" 任务跑了三小时,最后一步部署成功。事件性反馈给你一个绿色 checkmark:成功。
但真实情况可能是:第 11 步它在某个配置文件上卡了 40 分钟,反复试了七种写法。第 23 步它发现了一个原系统就存在的 bug 顺手修了,但没记录。第 31 步它发现某个依赖的版本不兼容,绕了个圈找替代方案。这些细节如果你只看"任务成功/失败",全部丢失。但下次再做一个类似迁移时,这些细节恰恰是最值钱的反馈材料——"哪一类配置容易出错"、"哪些依赖经常有兼容问题"。
持续反馈模型不一样。它把任务执行的整个时间轴都当成可以采样反馈的对象。在每个决策点(不是每一步)记录一次:当时 Agent 面临的选择、它选了哪个、为什么、当时已知信息是什么。任务结束后做的不只是"成功/失败"标记,而是回看决策点,标注每个决策回头看是不是好决策。
这种模型有点像下棋的复盘。一盘棋下完,赢了不等于每步都对,输了也不等于每步都错。真正能让你下次下得更好的,是把那几个关键决策点拎出来重看一遍。Agent 任务也一样。事件性反馈只告诉你输赢,持续反馈才能告诉你哪几步定胜负。
代价当然有。持续反馈的存储和处理成本远高于事件性反馈。但你不需要对所有任务都用持续反馈——把它留给那些复杂度高、跨度长、未来会重复的任务类型。日常的简单任务事件性反馈足够了。
这里有个常见误区:很多人以为持续反馈意味着把每一步都记下来。不是。它意味着只记"决策点",不记每一步。决策点通常是少数——一个三小时的任务可能只有四到六个真正的决策点,剩下的几十步都是机械执行。把决策点拎出来记是值得的,把执行步骤也记下来就是噪声。怎么判断"这是不是一个决策点"?我的经验是:如果 Agent 当时有两个以上的合理选择,就是决策点;如果它只是在执行上一步确定的动作,就不是。
反馈预算:你不能什么都喂回去
写到这我必须强调一件事,因为我见过太多团队栽在这里:Agent 的每次决策都是在固定 context 窗口内进行的,反馈材料是有预算的。
你给 Agent 喂的每一条历史反馈,都在挤占它思考当前任务的空间。一条 5000 token 的历史 trace 喂回去,相当于让 Agent 少 5000 token 来处理当前问题。这不是技术细节,这是架构层面的成本。
很多团队没意识到这件事,因为他们的反馈是隐性的——RAG 检索一波相关历史塞进 prompt、memory 系统自动注入最近 N 条记录、persona 文档每次都全文加载。每一项单看都"应该有用",加起来已经占了 context 的一半。剩下一半 Agent 用来读用户当前问题和工具返回,思考的空间被压得很小。
反馈层必须有预算意识。每条反馈进入下次决策前要回答一个问题:它的价值是否高过它占用的 context?如果一条 3000 token 的历史 trace 只能让决策正确率提升 1%,它就不值得。反过来一条 50 token 的关键经验——"这个项目的 prod 库别直连,永远走 read replica"——价值远高于成本。
这个判断在工程上有几条具体做法。一是先压缩再回流:原始 trace 不进 memory,进 memory 的是抽象出来的判断("该用 read replica")。二是惰性加载:默认不加载历史反馈,Agent 觉得需要时主动检索。三是时间衰减:超过一定时间的反馈自动降权或归档——你三个月前的某次失败,今天大概率已经不相关了。四是爆炸性事件优先:成功案例的反馈价值通常不如失败案例——平稳成功不值得记,意外失败值得反复回顾。
预算思维一旦建立,你会发现反馈层的设计完全反转了——它不再是"尽可能多收集",而是"尽可能少回流"。少而精的反馈,比多而杂的反馈有效得多。
我现在的设计选择
把上面这些拆完,我自己实际在用的反馈层架构是这样的——不是推荐给所有人,是我现在这个场景下的取舍。
执行 trace 默认不进任何持久存储。原始 stdout、stderr、syscall 日志只在当前任务的 context 里有效,任务结束自动丢弃。这是反预算膨胀的第一道防线。
每次任务结束有一个固定的 reflection 步骤。它不是把 trace 复述一遍,是回答三个具体问题:这次任务里有没有遇到"以前不知道的"事实?有没有发生违反预期的事?如果重做,第一步会改吗?三个问题加起来产出不超过 200 字。这 200 字才是真正的反馈。
反馈写入分三层。一层是任务级缓存(10 分钟过期),用于同一个 task 内的多步协调。一层是项目级 memory(按仓库或工作目录归档),用于这个项目内的偏好和约定。一层是全局 lessons(手动 promote),只有那些跨项目可复用的判断才进——而且必须经过一次人工确认或第二个 Agent 复审。
反馈调用是显式的,不是默认注入。Agent 在某一步需要历史经验时,自己发起一次"我需要关于 X 的过往经验"的查询。这个设计有点反直觉——为什么不让相关经验自动浮现?因为自动浮现的代价是 context 污染,而 Agent 主动查询的成本是多一次工具调用——后者便宜得多。
失败信号比成功信号优先。每次任务结束如果有非预期事件——不管最终是不是成功——这次任务进入 review queue。成功且平稳的任务直接归档不做后续处理。这把反馈处理的资源集中到真正值得复盘的样本上。
这套设计也不是终态。它解决了"反馈池被污染、Agent 越用越笨"的问题,但它也带来了新的代价——Agent 偶尔在某个本该用历史经验的地方没有调用,需要用户提醒。我现在觉得这个代价比 context 污染小,但这个判断可能在更长链路的任务上不成立。
系列下一站
反馈层解决了"信号怎么回流"。但那些被 promote 上来的全局 lessons,它们要怎么组织、怎么检索、怎么演化——这是另一个独立的问题。
下一篇聊 Knowledge Layer:当 Agent 积累了几千条 lessons,它怎么知道现在该用哪一条?为什么大多数知识库系统在 AI 时代会被重做一遍?
写在结尾
反馈层不是一个技术问题,是一个取舍问题。你愿意为多干净的反馈付多大的代价。
最干净的反馈系统是"什么都不记"——零污染,但每次从零开始。最丰富的反馈系统是"什么都记"——理论上最聪明,实际上最笨。中间这一大片地带怎么走,没有标准答案。
但有一个判断标准,比所有具体的实现方案都重要:这个系统在第 N 天,比第 N-1 天更聪明,还是更笨?如果你的反馈层做得对,这个数字会缓慢但稳定地正增长。如果做得不对,它会在某个节点开始倒退——而你大概率不会立刻发现。
去看一下你的 Agent 系统,今天比一个月前更聪明,还是只是积累了更多噪声?这个问题值得每周问自己一次。
