 夜雨聆风
夜雨聆风现在各种智能体已经越来越成熟了,但是在问数这个领域想把问数做的精确还是有一定的难度,所谓AI问数,也就是业务用户在不写sql 的前提下通过自然语言提出问题,然后AI去帮你去企业数据库查数,准确的查到结果并结构化展示或者直接生成Dashboard报表,这个需求在当前结合vibe coding或者借助agent的能力实现并不复杂,但是要是做的准确依然不是一个简单的事情。

最初我们第一版的方案,我们考虑过将EDW里面所有的表的表名+列名字+comments 一起向量化 到一个向量库里面,一个表对应一条向量数据,当用户的问题来了之后,根据用户的问题通过RAG的方式去找到对应的表,找到对应的表,拿到表和表的列信息之后一起交给大模型去生成query 的sql,在表少的情况下准确度还可以,但是实际run起来了发现准确度简直基本上不可用,后来果断放弃了这个方案。
后来我们去研究市场上比较成熟的智能问方案,发现有些云厂商做的还是可以的,做了一些poc测试,发现准确度相当高,通过各种实操,感觉他的理念是非常值得借鉴的。
总结来说要想问数准确以下几点是非常关键的

第一,检索范围被强约束
要有一个数据域主题域的概念,我觉得这里面最值得借鉴的理念就是不要想着将海量的或者大量的表放到一个篮子里去检索,那样做一定是不准确的,肯定不会有好的效果,一个问数的场景要细化下来,一个数据域对应一个问数的场景,降低幻觉,对应一个数据域只允许有5-20个表最多不要超过30个表在里面,不要想着所有的表都放一起给大模型然后有一个完美的效果。
第二,要有清晰的业务语义层
大模型懂不懂我们的业务就看这一步,不要指望着一堆表丢给大模型就完事了,直接上去问啥就给你答啥,大模型不是神他是最不到的,如何让大模型熟悉我们的业务是一个精细活,也是一个需要有耐心的一个繁琐活。
主题域级别的描述- description 关于这个主题域常问的问题 每个table描述+每个column的描述 关键table 的sample data,关键column 的枚举值 table 的 join 关联,要设定左右关联table,关联的key 一些关键kpi的定义,直接提供计算公式sum(x/y/x)等 预设一些容易混淆出错的query 语句定义在那里
以上可以借助大模型去帮忙编辑,但是肯定要人工干预,维护的越好,准确度越高
第三,限定不允许凭空回答,要有依据
agent所有答案必须基于可执行的sql得出的结果去回答,
第四,优化上下文问题,
追问时保留会话状态,减少反复误解。
第五,反馈可迭代
失败样本和高频问题可回灌,有点赞点踩机制,准确率会随运营提升。
对于复杂的主题域可以按multiple agents 的场景去设计,一个主题域的智能体看成一个子agent,一个agent只负责一个确切的主题域。
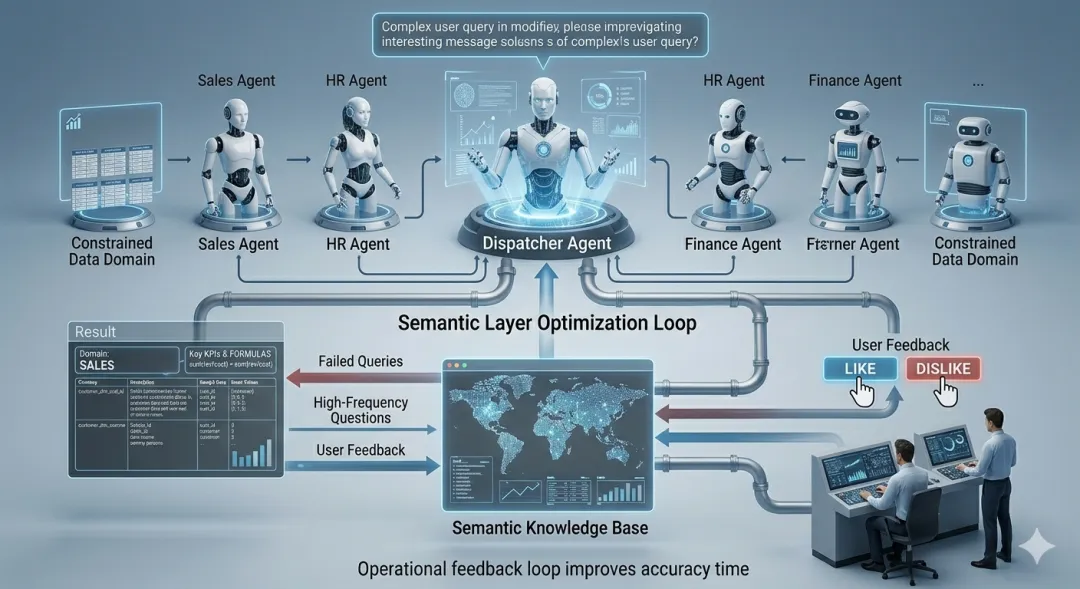
下面有机会的话会分享下具体的架构设计,有兴趣的同学可以关注
