夜雨聆风
夜雨聆风在 AI 技术快速普及的今天,LM Studio 以 “本地运行、隐私优先、极简操作” 为核心,成为个人与企业部署大语言模型(LLM)的首选桌面应用。它彻底摆脱云端依赖,让普通用户无需专业代码能力,即可在个人电脑上解锁 AI 模型的全部能力,兼顾数据安全、响应速度与使用灵活性(毕竟可以兼容GGUF格式,全图形化调参也降低使用者难度)。
它将复杂的模型部署流程可视化,整合 Hugging Face 模型库,支持 GGUF、MLX 等主流模型格式,实现 “一键下载、即装即用”。
核心功能
- 零代码模型管理
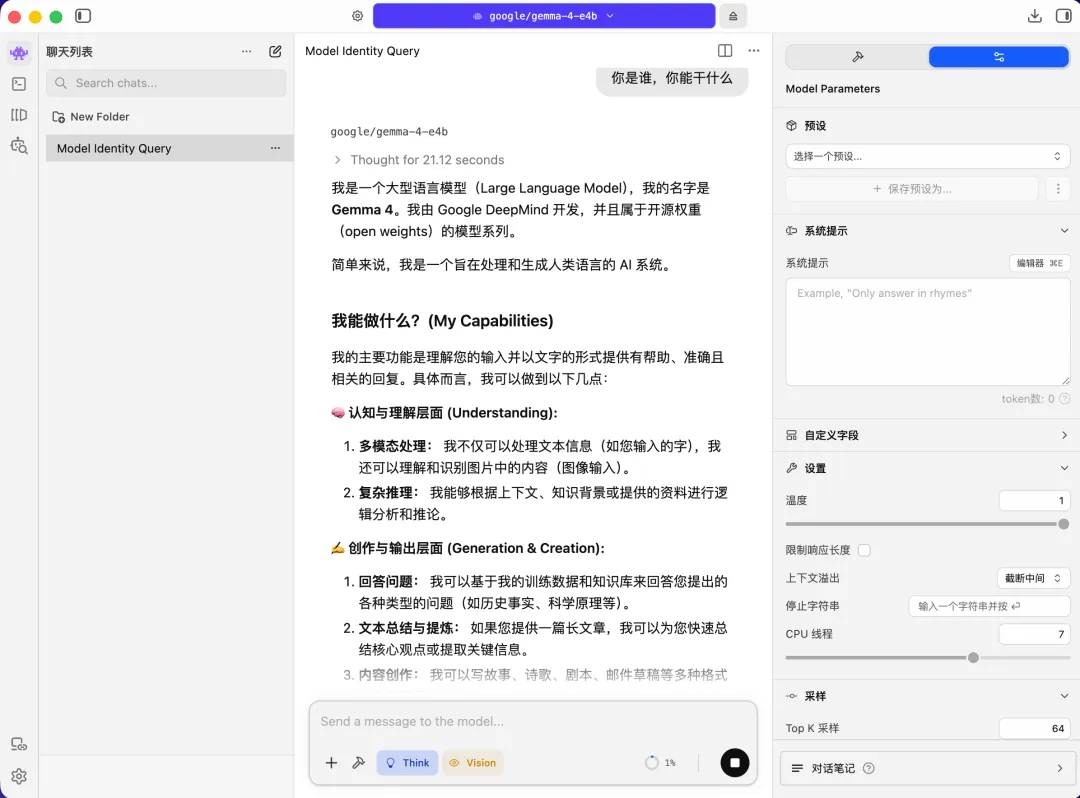
内置可视化模型商店,支持按参数规模、用途(聊天 / 编程 / 创作)、硬件适配性筛选,一键下载并自动配置环境,告别命令行操作。 - 原生对话交互
类 ChatGPT 的聊天界面,支持多会话管理、文件夹归类,可自定义温度值、上下文窗口、重复惩罚等参数,精准控制模型输出风格。 - 本地 RAG 文档交互
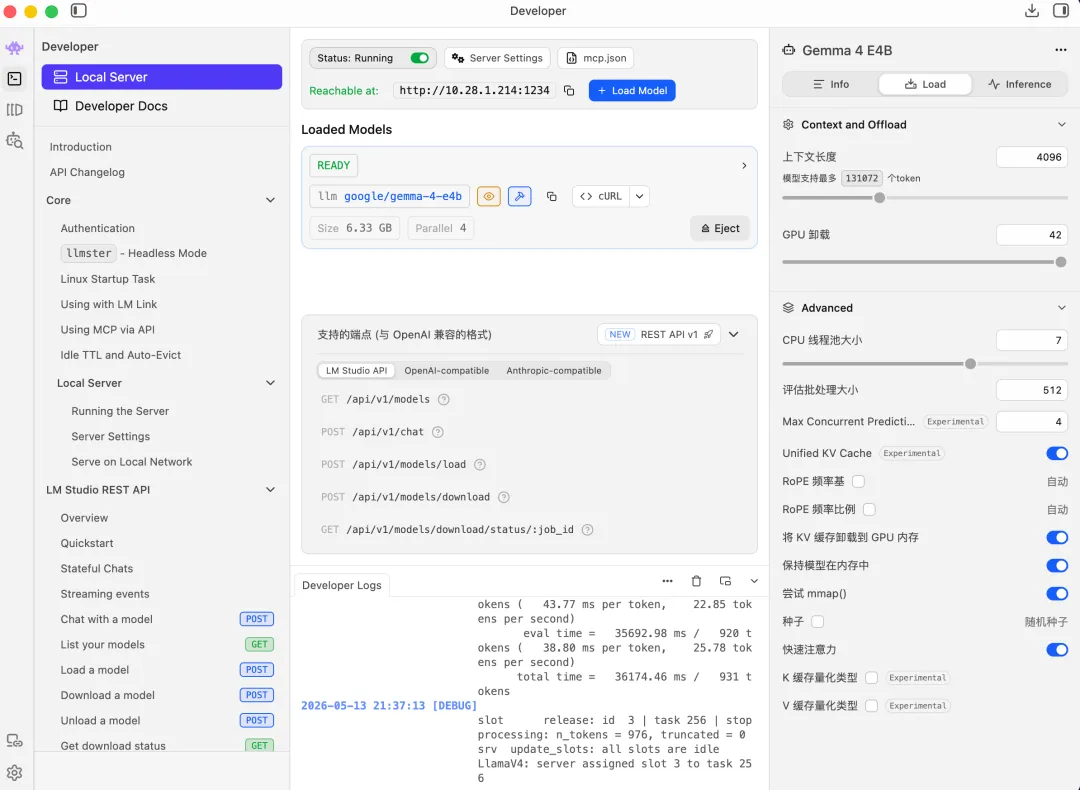
完全离线加载 PDF、Markdown 等文档,实现 “文档问答、内容摘要、信息提取”,敏感数据无需上传云端LM Studio(离线可用)。 - OpenAI 兼容 API
内置本地 API 服务器,端口默认 1234,兼容 OpenAI 接口规范,可无缝对接第三方工具(如写作软件、开发插件),将本地模型转为私有 API 服务。 - 多模型并行运行
支持同时加载多个模型,分屏对比输出效果,适配模型测试、方案选型等场景LM Studio。
针对 Mac 设备(尤其是 Apple Silicon M系列),LM Studio 做了深度适配与性能优化,充分释放 M 系列芯片的统一内存与算力优势,是 Mac 用户本地运行 AI 模型的最优选择。
1. 原生适配,极简安装
支持 macOS 13.6+ 系统,兼容 M1/M2/M3/M4 全系列芯片,同时适配英特尔芯片 Mac LM Studio(但是性能肯定不急M系列)。
2. MLX 引擎加速,性能拉满
独家支持 Apple 自研 MLX 框架(专为 Apple Silicon 优化的 AI 计算栈),相比通用的 llama.cpp 引擎,推理速度提升 20%-50%,功耗更低、散热更少,Mac 运行更安静。 充分利用统一内存架构:M 系列芯片的 CPU、GPU、神经网络引擎共享内存,无需数据拷贝,16GB 内存可流畅运行 7B-8B 模型,32GB 可驱动 13B-14B 模型,48GB + 可稳定运行 30B 大模型(我16G内存跑9B GGUF格式没什么压力,25.78token/s的效率适应性很强)。
1. 通用聊天模型(日常对话 / 助手)
- Llama 3.1/3.2(Meta)
主流通用模型,7B/8B 参数适配 16GB 内存,13B 参数适配 32GB 内存,对话流畅、逻辑清晰,支持多轮长上下文交互。 - Qwen2.5/3(通义千问)
国产标杆模型,7B/8B/14B 参数全适配,中文理解能力极强,支持方言、成语、复杂句式,适合中文日常聊天与办公辅助。 - Gemma(Google)
轻量高性能模型,2B/7B 参数,体积小、速度快,适合低配置 Mac(8GB 内存),对话简洁、无冗余内容。 - Phi-3(微软)
超小参数高性能模型,3B/4B 参数,16GB 内存可流畅运行,推理速度极快,适合实时对话、移动端场景。
2. 编程开发模型(代码生成 / 调试)
- Qwen3-Coder(通义千问)
编程专用模型,8B/14B 参数,支持 Python/Java/Go/ 前端等多语言,长代码上下文处理强,适合开发辅助、脚本生成。 - DeepSeek-Coder
代码能力顶尖,7B/33B 参数,支持复杂算法、框架开发、代码调试,32GB 内存可运行 14B 版本,适配专业开发场景。 - StarCoder2
开源编程模型,7B/15B 参数,支持多语言代码生成与补全,适配低配置设备,适合入门级开发学习。
3. 创意写作模型(文案 / 小说 / 诗歌)
- Llama 4(Meta)
创意生成能力突出,Scout/Maverick 变体,8B/14B 参数,支持小说创作、文案撰写、诗歌生成,风格自然、想象力丰富。 - Mistral 7B/8x7B
轻量高效,推理速度快,创意输出灵活,支持短篇故事、营销文案、短视频脚本生成,适配 16GB 内存设备。
4. 专业推理模型(逻辑 / 数学 / 数据分析)
- Qwen3-Reasoning
推理专用模型,8B/14B 参数,擅长数学计算、逻辑推理、数据分析、学术问答,适合学生、科研人员、职场数据分析场景。 - DeepSeek-R1
推理能力顶尖,14B/33B 参数,支持复杂数学题、逻辑论证、专业领域问答,32GB 内存可流畅运行,适配专业推理需求。
5. 工具调用模型(函数调用 / RAG / 自动化)
- Qwen2.5-Instruct
原生支持工具调用,7B 参数,适配 16GB 内存,可对接本地 RAG、API 接口、自动化脚本,适合构建私人 AI 助手。 - Llama 3.1-Instruct
工具调用能力强,8B/13B 参数,支持多工具并行调用,适配复杂自动化场景,可实现文档处理、数据查询、任务编排等功能。
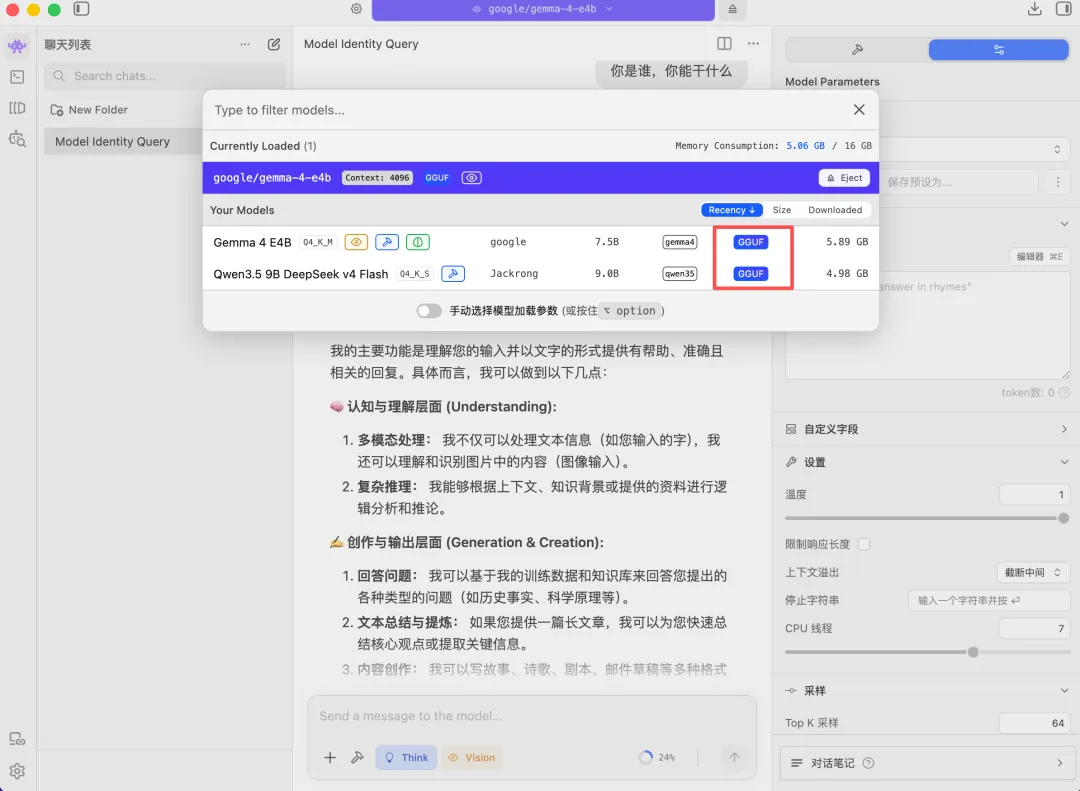
6. Apple Silicon 专属优化模型(MLX 格式)
专为 Mac M 系列芯片优化,推理速度比 GGUF 格式快 20%-50%,推荐优先选择:
- MLX-Qwen2.5-7B-Instruct-4bit
中文聊天首选,体积小、速度快。 - MLX-Llama 3.1-8B-Instruct-4bit
通用对话首选,适配 16GB 内存。 - MLX-DeepSeek-Coder-7B-4bit
Mac 编程开发首选,性能拉满。