 夜雨聆风
夜雨聆风
Hermes是我第二次被AI能力震惊到的瞬间,第一次是去年三四月作为非技术出身的人首次用trae做vibe coding。
这一年来,我的AI工具一直在演化:trae——cursor+manus+gpt+dify——codex+claudecode+manus——hermes+codex+claudecode。我用codex可以完成coding、数据分析、skills等等工作之中和工作之外的事情,额度告急就用cc接国产模型api,好像没有什么做不到的。
而想用hermes的缘起很简单,我实在想知道公司里经常讲的自迭代到底是个啥……
于是我花了一周+一百多元+上亿token+买了一个VPS,解锁了26个hermes的成就,设置了3个cron定时任务,诞生了n个skills。
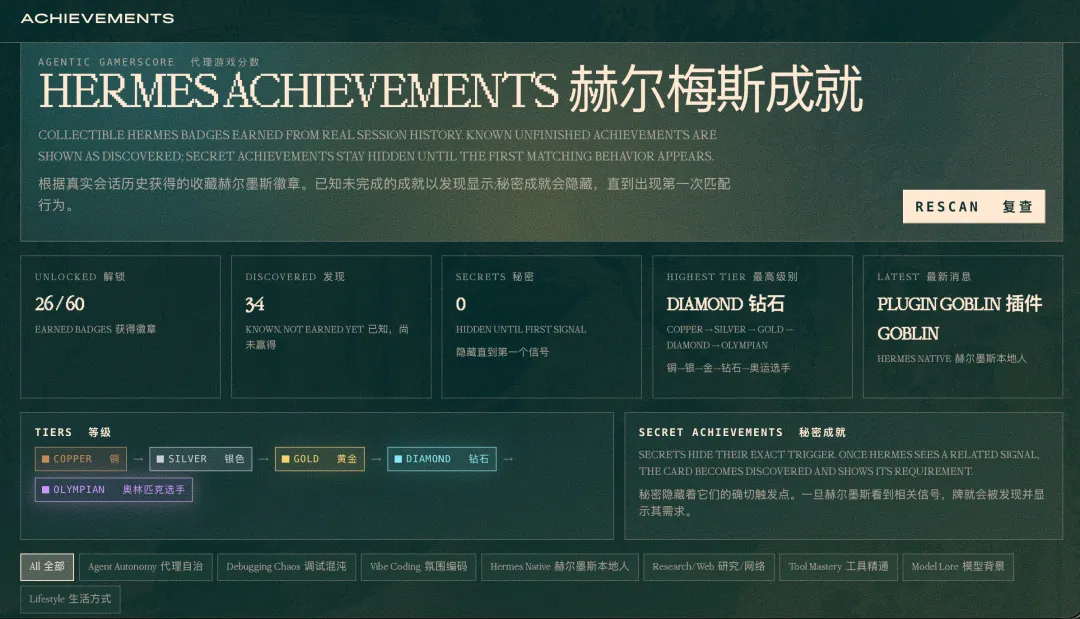
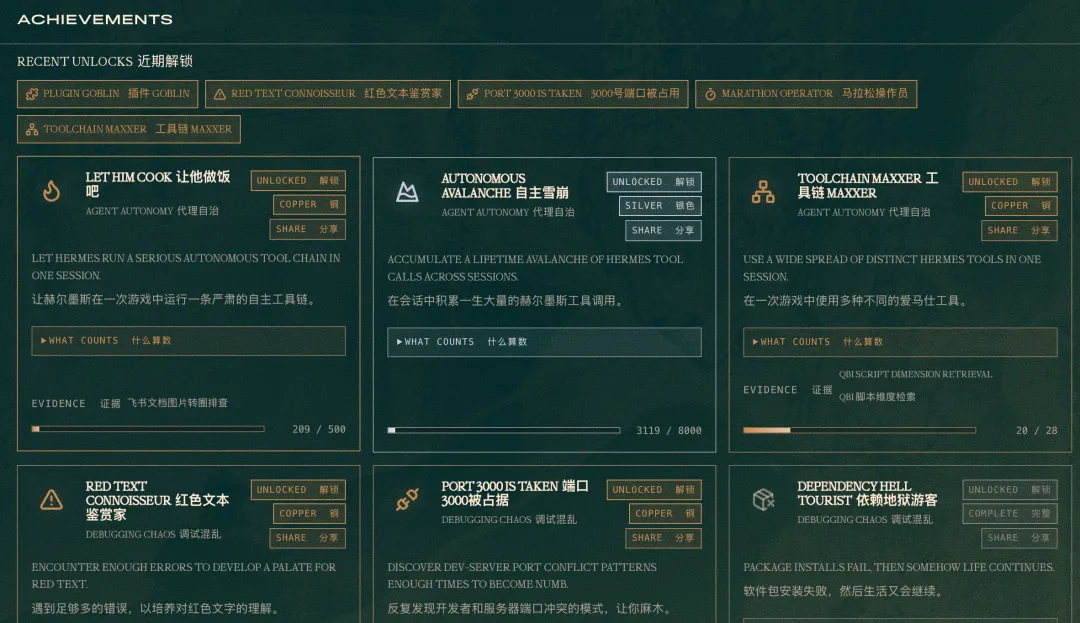
5.6 安装hermes,给自己做了一个飞书的产品灵感收集助手
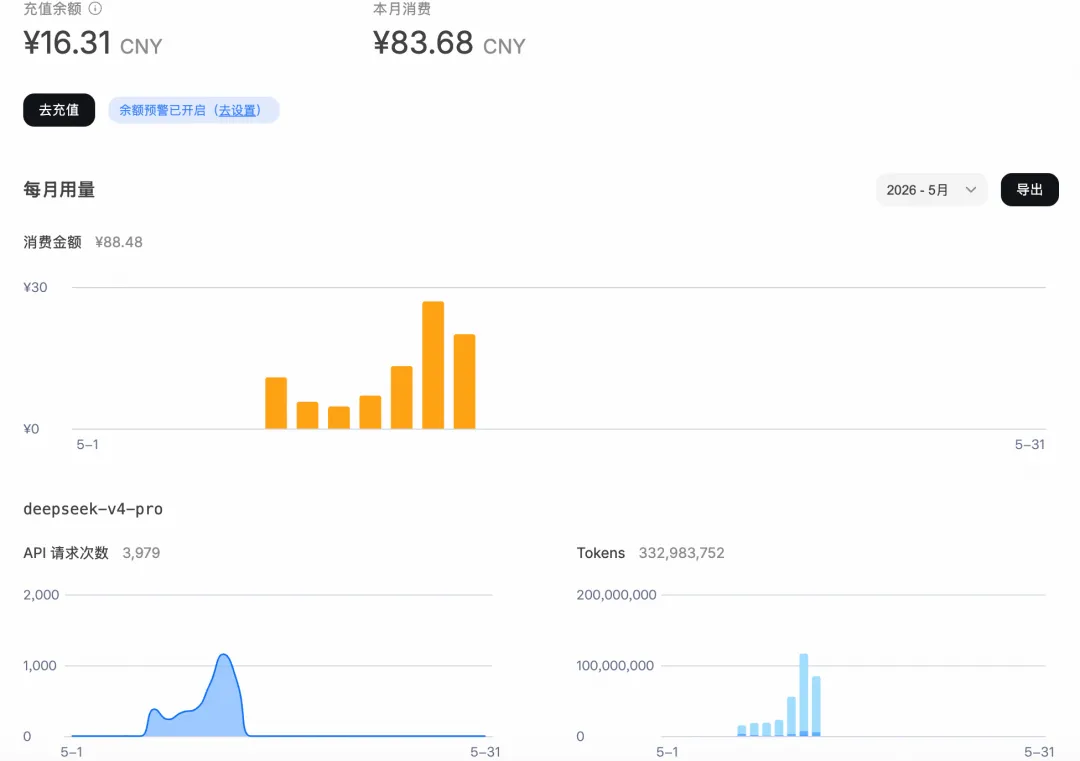
5.7 发现成就系统,发现openrouter开销过大,换成正在折扣的deepseek v4pro,并且想尽办法找到成本高的原因去解决
做了一个token成本分析的skill来对账
做了一个状态栏插件,用来提示上下文窗口、对话轮次、开销成本、成就数量,做了handoff后/new自动读取压缩内容,才意识到codex原来把这些体验做得如此丝滑、交互如此简洁!!
增加解锁成就时在terminal对话窗口提示的彩蛋效果,我的心情会更好
5.9 发现cron定时调度任务的问题,买了5美金一个月的vps
5.11 查看周度token成本复盘的报告,发现复盘token成本也是锻炼数据思维的方式
5.12 还在改产品灵感收集助手的问题。又搞了一个codex/claudecode/hermes等agent产品动态追踪的cron任务
5.13 安装了hermes新出的computer use插件,并且解决了一个codex上没有解决的工作问题,做了数据分析
这个过程让我想起罗福莉在播客上讲她春节用 OpenClaw 的经历。她先用 Claude Opus 改 OpenClaw 的 agent 架构,改到好用了再换成中层模型——然后发现中层模型也能把任务执行得很好。直到我自己用开源的hermes玩得不亦乐乎,我才理解原来build的成本可以这么低:用开源半成品自己亲手踩一遍坑来学习,再像做陶器一样打磨成适合自己的形状。
02 产品怎么用Hermes?
(1)Hermes会在无感的情况下自己更新记忆、创建并更新skills,所以适合用来沉淀自己的工作流。
我在反复修改产品灵感助手的时候,突然看到terminal窗口有一条写入常见缺陷的记录。点开skills.md,绷不住那最后一部分「常见陷阱」里20条密密麻麻都是踩过的坑。每一条有日期、有根因、有修复方案,有的还标注了「当前状态」和「理想方案待实现」。
那它怎么判断什么时候是该存记忆还是skills?什么时候更新skills?记忆达到上限时怎么更新?我在这里粘贴一下它的回复:
> **Hermes**:好问题——这涉及 Hermes 三层知识的分类逻辑。不在代码里,在 system prompt 的规则里。
> `prompt_builder.py` 注入了三条自然语言规则,LLM 每次读完后自行判断:
> **Memory** — 持久事实,每次对话都注入:
> 「User preferences and recurring corrections matter more than procedural task details. Do NOT save task progress, session outcomes... If a fact will be stale in a week, it does not belong in memory. Write memories as declarative facts, not instructions to yourself.」
> **Skill** — 可复用工作流,任务触发时才加载:
> 「After completing a complex task (5+ tool calls), fixing a tricky error, or discovering a non-trivial workflow, save the approach as a skill. When using a skill and finding it outdated, incomplete, or wrong, patch it immediately.」
> **Session Search** — 临时任务状态,不持久化:
> 「Use session_search to recall those from past transcripts.」
> 所以没有硬编码的分类逻辑。Agent 靠这三个规则做运行时判断:用户偏好去 Memory,可复用工作流去 Skill,会过时的东西不存、用 session_search 回查。
我觉得C 端用户产品反而很难被AI蒸馏,有太多经验、直觉、决策来自模糊的、定性的、非结构化的那部分。在AI出现之前,依靠古法调研我虽然做了一些dirtywork,但也扎扎实实打下了基本功,能判断我该在什么时候做什么分析预期得到什么结论、是不是伪需求PMF是什么、该用什么产品形态做。
所以我首先去复刻了实习时做过的事情——用户session分析skill、用户反馈分析skill、搜索词分析skill、竞品追踪skill、各种数据分析skill。但是这只是单点的分析,并且从洞察分析到需求定义、判断需求价值还有很远的路径,持续的思考和经验的积累才能汇集成近乎直觉的判断力。这或许还需要群体智慧。
目前我摸索出来的一个方式是,把Hermes当成实习生用钉钉文档/飞书云文档来协作,批注、编辑你认为需要改的地方,让它记住为什么这么改、为什么这么决策判断。然后这些决策经验先积累下来看看会发生什么。
(2)学习agent架构并在它的基础上build
其实之前我不太在意token成本,codex这种订阅制确实省心。我也不了解上下文管理的技巧,毕竟codex自己就自动压缩了,还有圆环提示上下文窗口。但直到我在hermes自己花钱买的token开始肉疼了,才算真正接触一些原理。
就像我前面说的,有这么多好的开源或闭源的agent在以周维度更新迭代,社区有无数贡献。这简直就是知识的海洋……完全可以用hermes自己复刻功能来学习。另外本身这也是一种需求场景,你自己为了顺手做的改动和小功能还可以开源分享到github。
后续将持续把我使用hermes的经验和感想build in public~欢迎关注讨论

