 夜雨聆风
夜雨聆风
公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
当大模型开始“扮演”人类参与社会调研,你会放心把问卷交给它们吗?这篇来自约克大学的论文没有停留在“能或不能”的口水仗上,而是用严谨的实验给了我们一份详尽的“使用说明书”。它不仅告诉我们数字人在哪里表现好(群体趋势预测),更明确指出其核心短板(个体预测和多变量结构)。对于那些想用AI辅助社会研究的朋友,这篇文章绝对是必读的避坑指南,实用性拉满。
原论文信息如下:
When Can Digital Personas Reliably Approximate Human Survey Findings?
2026年05月
约克大学 (York University), 大学健康网络 (University Health Network)
https://arxiv.org/pdf/2605.10659v1.pdf
当AI成为“你”:数字角色到底靠不靠谱?
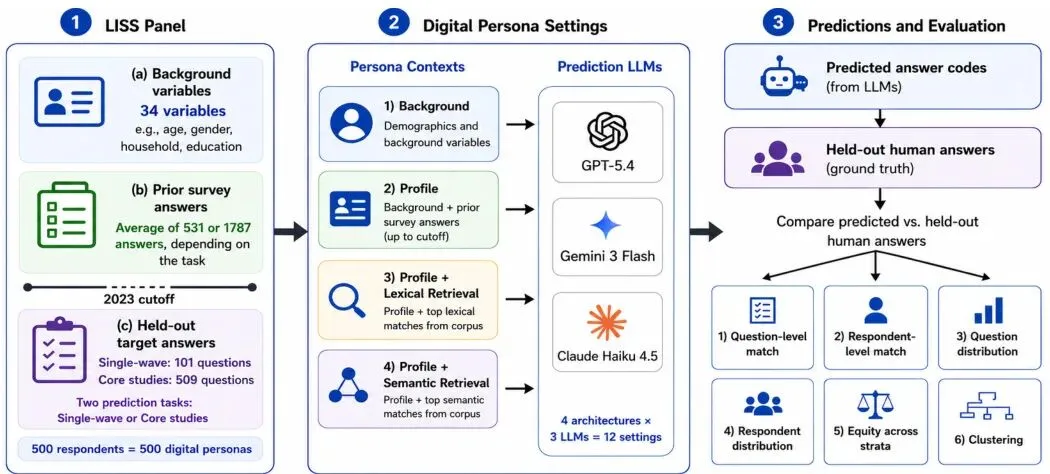

多维评测:不只是看角色“蒙对”了没
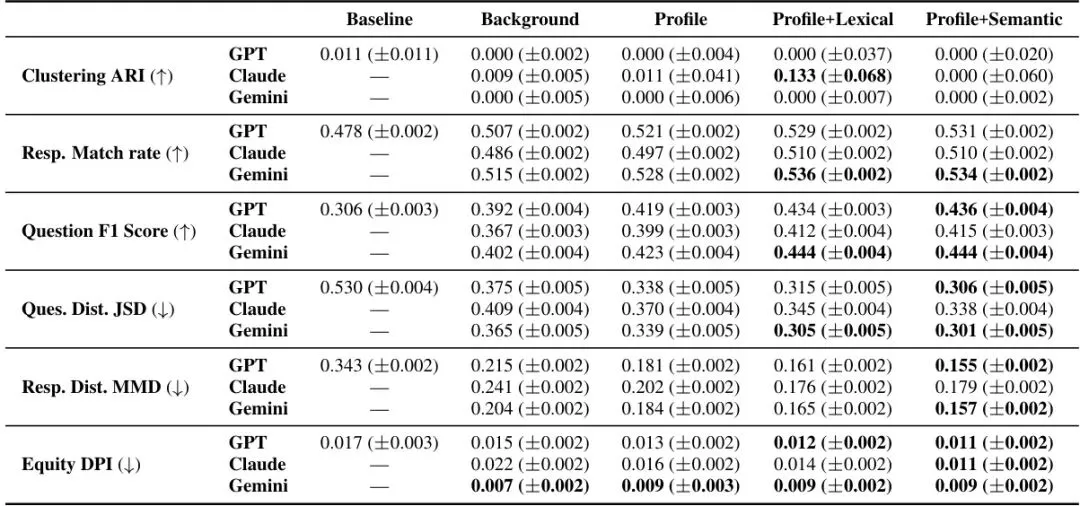
🔹 问题维度(Question-level match)——对每个调查问题,看AI给出准确答案的比例(加权F1分数)。
🔹 受访者维度(Respondent-level match)——看AI还原某个特定受访者整个回答集的能力(精确匹配率)。
🔹 问题分布维度(Question-level distribution)——AI生成的回答分布与真实人群分布有多像?用Jensen-Shannon散度(JSD)衡量(数值越低越好)。
🔹 受访者分布维度(Respondent-level distribution)——AI生成的单个受访者的回答模式是否与真人接近?用最大均值差异(MMD)衡量。
🔹 公平性维度(Equity)——AI在不同性别、年龄、家庭阶段的人群中,表现是否存在系统性差异?用人口统计公平指数(Demographic Parity Index,DPI)的均值绝对偏差来检测。
🔹 聚类维度(Clustering)——如果要根据回答把一群人的AI版和真人群进行“分类”,得到的分类结果一样吗?用调整兰德指数(Adjusted Rand Index, ARI)衡量。
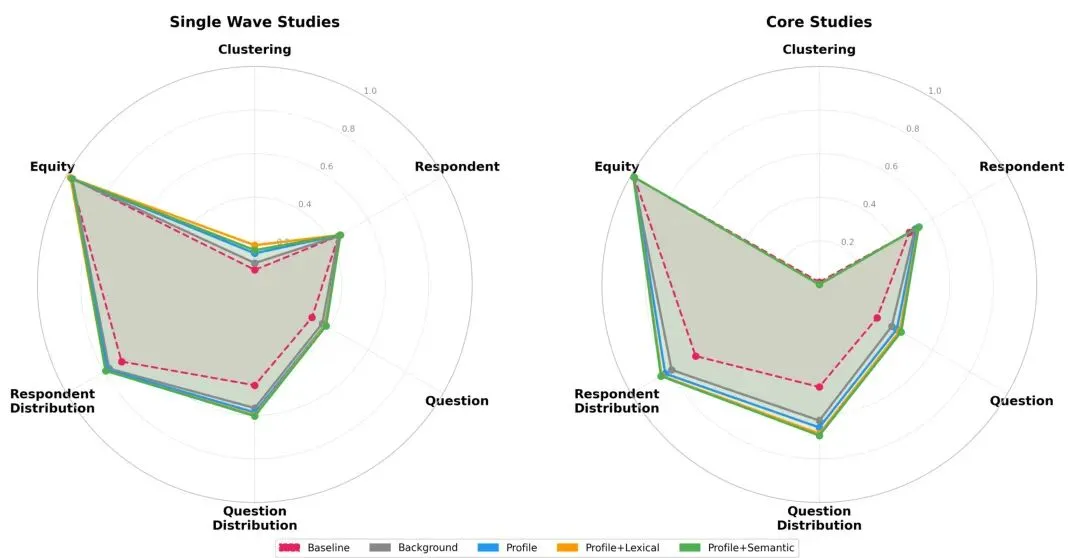
谁能答得更好?答案藏在问题本身里
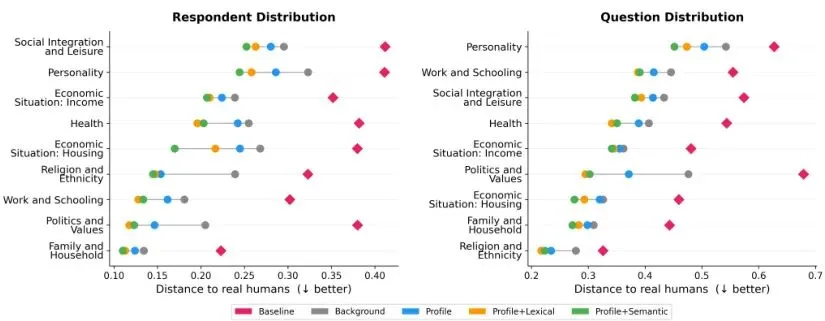
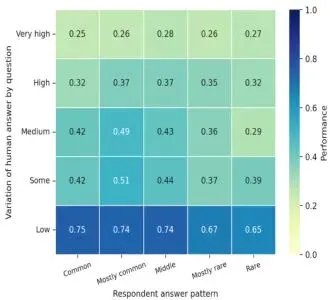
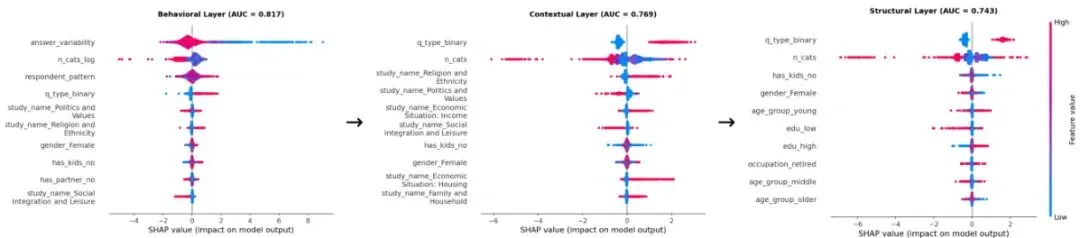 图6:基于XGBoost模型的数字角色准确率前十预测因子(三个特征层)。
图6:基于XGBoost模型的数字角色准确率前十预测因子(三个特征层)。
扎实的框架,但有局限
背景版——只给34个背景变量(性别、年龄、收入等),不给任何历史答题记录。
画像版——背景变量 + 一段用GPT-5.4生成的文字摘要(总结受访者的历史答案特征)。
画像+词汇检索版——画像版基础上,从历史答案中检索出与当前问题最词汇相似的若干条答案。
画像+语义检索版——用嵌入向量做语义相似度检索,找到与当前问题最“意合”的历史答案。
他们还用了三个不同的LLM作为预测模型:GPT-5.4、Gemini 3 Flash、Claude Haiku 4.5。加上一个没有受访者信息的基线模型(只给问题文本,不给任何个人信息)。
给AI调研的实用指南
✅ 可以放心用的场景:
想快速预判一个调查工具在群体层面的答案分布,特别是当问题答案空间小(比如二选一)且人类回答很可能集中时。例如:人口统计类问题(“你结婚了吗?”“你有孩子吗?”)、价值观类问题(“你同意这句话吗?”用同意/不同意两分法)、宗教和政治倾向等稳定领域。在这些任务上,数字角色可以节省大量前期测试成本。
⚠️ 需要谨慎使用的场景:
当你想预测某个具体个体的回答(比如“老张会不会对这个新产品感兴趣”),或者当调查内容高度依赖个人经历、主观感受(比如“你有多幸福?”“你最近感到孤独吗?”),又或者你想做人群细分、识别潜类别时——数字角色基本不靠谱。聚类分数接近于零的信号非常强烈。
💡 关键发现:
检索增强(Retrieval-Augmented Generation, RAG)的架构确实有帮助,但更重要的是,在回答结构本身就很稳定的问题上,不同LLM之间的表现差异很小。所以别把精力花在换模型上,而应该先去判断问题的“可预测性”。
龙迷三问
这篇论文解决的核心问题是什么?它回答了一个很实际的问题:在什么条件下,大模型生成的“数字角色”可以替代真实的人类受访者进行社会调查?它没有给出一个简单的“能”或“不能”,而是给出了具体的适用条件清单。
什么是“数字角色”(Digital Persona)?它是一个为大模型准备的提示词上下文,包含了某个受访者的背景信息(如年龄、性别、收入)以及ta过去对调查问题的回答历史,目的是让LLM模拟该受访者回答新的调查问题。论文中探索了四种构建方式,从最简单的只给背景变量,到最复杂的检索增强画像。
这篇论文与之前的相关研究有什么不同?之前的很多研究要么只用聚合指标评估,要么没有使用同一人时间分割的严格检验,要么没有评估公平性和聚类。本文同时结合了纵向面板数据、时序留出验证、多维度评估、多种角色构建策略和多种LLM,综合程度是前所未有的。一句话:之前的工作就像只测了身高,这篇论文做了全身CT。
龙哥点评
论文创新性分数:★★★★☆
提出了六维评估框架,并与纵向面板数据结合,这种系统性在现有文献中少见。虽然每个维度都不是全新概念,但整合设计有创新。实验合理度:★★★★★
使用同一人时间切分的严格检验,多种角色架构和LLM对比,统计稳健性(bootstrap置信区间),总体设计非常严谨。学术研究价值:★★★★☆
为AI模拟人类调查的可靠性研究提供了实证基础和方法论框架。未来类似研究可以照搬这个六维评估体系,学术影响力较大。稳定性:★★★☆☆
在个体预测和聚类维度上表现不稳定,依赖于问题特性和受访者模式。但公平性维度表现出较高的稳定性。综合看中等。适应性以及泛化能力:★★☆☆☆
仅在一个国家(荷兰)的封闭式问题上验证,其他文化、语言、开放式题型未知。泛化能力需要更多研究确认。硬件需求及成本:★★★☆☆
需要调用GPT-5.4等大型API(预计有较高的推理成本),尤其是检索增强版本需要额外嵌入和检索成本。不过对于企业级调研来说仍在可接受范围内。复现难度:★★★☆☆
LISS面板数据是需要申请使用的(非即开即用),且实验设计复杂(分层抽样、多种角色配置、多轮预测)。代码和数据未公开,复现有一定门槛。产品化成熟度:★★☆☆☆
目前更偏向研究结论,距离直接产品落地还有距离。企业如果要在自己的问卷系统中集成数字角色,需要谨慎验证,尤其是在个体层面和聚类层面几乎不可用。可能的问题:
论文的实验范围仅限于荷兰的封闭式选择题,且每个任务只用了500人。虽然作者坦诚了局限,但在结论推广时要小心。另外,检索增强的增益虽然统计显著,但实际幅度并不惊人,不少场景下简单背景版就能达到差不多的分布对齐效果。主要参考文献
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!



