 夜雨聆风
夜雨聆风
无论是学生还是AI,偷懒的永远比不上认真的
文/logo毕业生
本次登场的嘉宾有:豆包(专家)、千问(3.5思考)、ChatGPT(5.4thinking)。它们分别代表了当下几种有代表性的大模型:有国内c端用户霸主,有企业级ai服务专家,还有至今仍被很多人视作标杆的闭源王者。(开源DeppseekV4仍不开放识图)

但对于学生来说,问题其实没有那么复杂。他们并不关心参数、架构,也不关心谁在发布会上更会讲故事,指标登了几个顶。真正重要的只有一件事:这些AI,哪个更适合拿来实战。
这也是这次测试想回答的问题。
不过,我们不能直接拿高考题看谁做得正确率高,因为厂商大概率会对这类题做针对性处理,测出来的就不再是模型真实的现场能力,而是厂商有没有提前为这类题做好准备。
所以本次测试,选取题目时避开了以往的知名试卷,转而去选了一些更新的模考题和原创题,想看看这些模型离开题库答案解析之后,表现会发生什么变化。
一共选了六套题,分别是4月14号的高三佛山二模数物选填,4月济南二模,4月初上海老师原创数学试题,2月底广东top4联考,4月初北京名师原创数学试题。至于为什么不包括文科类和大题,因为这还只是这个专题的第一篇文章,之后会针对文科类和大题,对思路展开质量,回答质量,引导水平等因素展开测评,敬请期待。
话不多说,测评开始。

对比
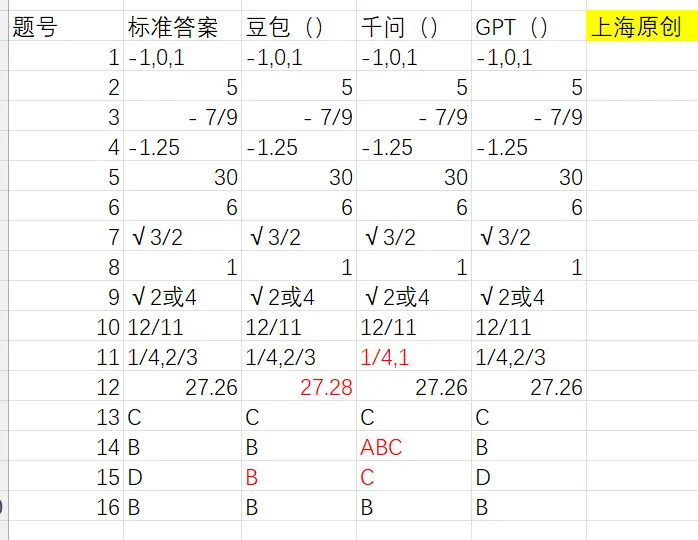
第一战面对的是上周的佛山二模数学和物理卷,挑战结果如图。
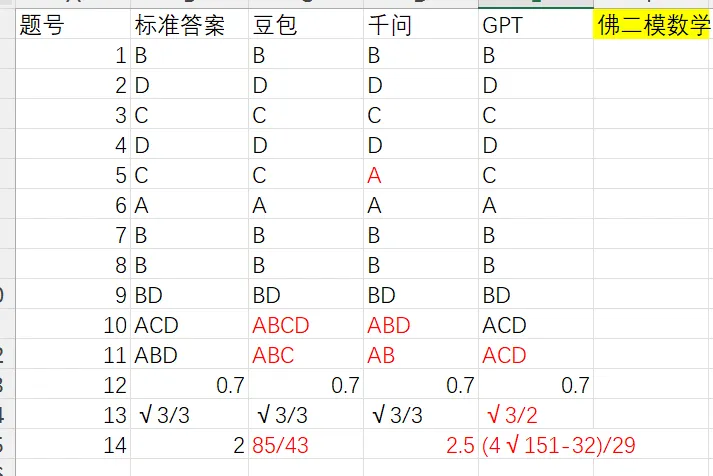
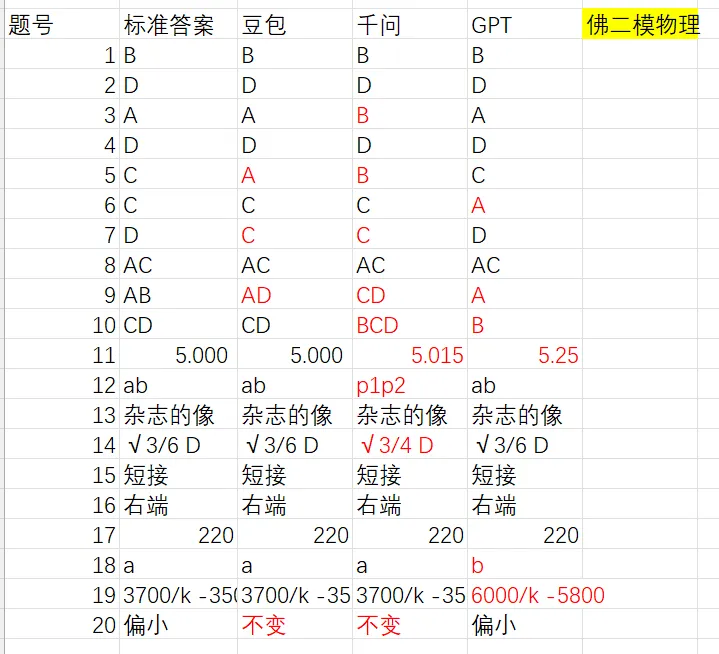
在测评开始之前,其实笔者在心里已经给它们做了个大概排名,大概是GPT>千问>豆包,因为按照权威官方测试的榜单,千问经常是国产AI的领头羊,长期刷榜,而豆包比较下沉,可万万没想到,首次的测试中豆包表现最佳,而千问表现最不理想。
为什么屡次刷榜的千问会掉到后面,而豆包又为什么能一下子冲到前面,是单纯的模型能力波动导致的吗?

模型定位
抱着这个疑问,笔者继续进行了测试,然而结果却大致类似,这种差异不再只是偶然波动,开始呈现出一定的稳定性,笔者慢慢冒出一个猜想:这背后是不是不代表模型能力本身的问题,而是和几款产品各自服务的用户、竞争的方向有关:
千问这些年更重的一直是企业服务能力,很多资源、优化方向,都更偏向To B场景:强调可接入性、业务适配、行业方案、企业级落地。而豆包的路径则明显更偏大众用户,面对的是更高频、更直接、也更残酷的C端竞争。所以,在这种前提下,厂家对“用户侧体验”的投入重点,可能天然就会不会一样。换句话来讲,To C产品要的是留存、活跃和体感,用户问一句,模型最好立刻给出一个像样、完整、还最好别太容易出错的答案;而To B产品很多时候先要解决的,反而是交付、稳定、接口、成本和企业侧的复杂需求,两者本身的产品定位可能就不一样。
因此,笔者很难不产生一个结论:在面向普通用户的算力分配上,千问也许没有豆包那样“舍得”,它可能在成本、响应和能力之间做了更保守的平衡。


千问和豆包官网宣传页面中的“客户”明显指代不同
当然,需要强调一下,这些都是笔者的猜测,没有肯定的证据,而且模型能力随时会因为厂家的产品策略而改变。

题出错了?
后面的测试继续。
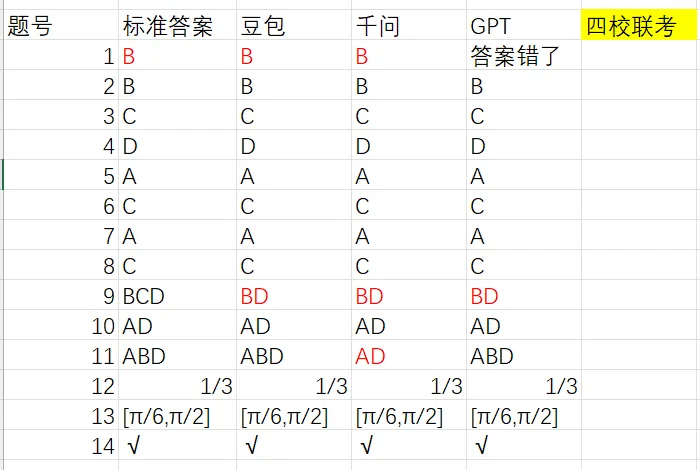
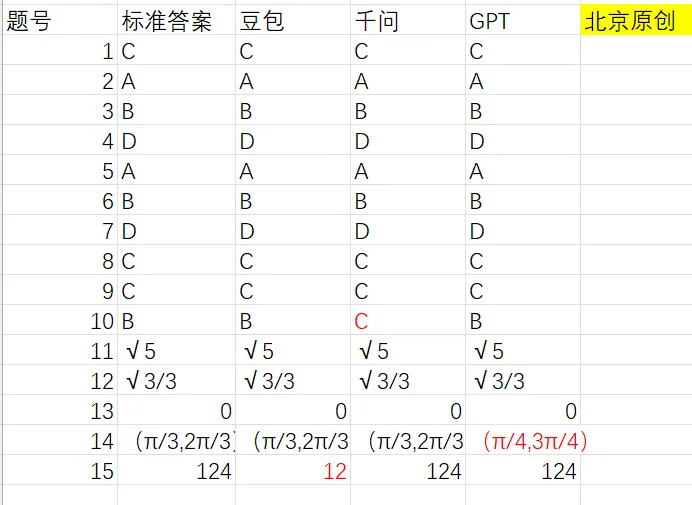
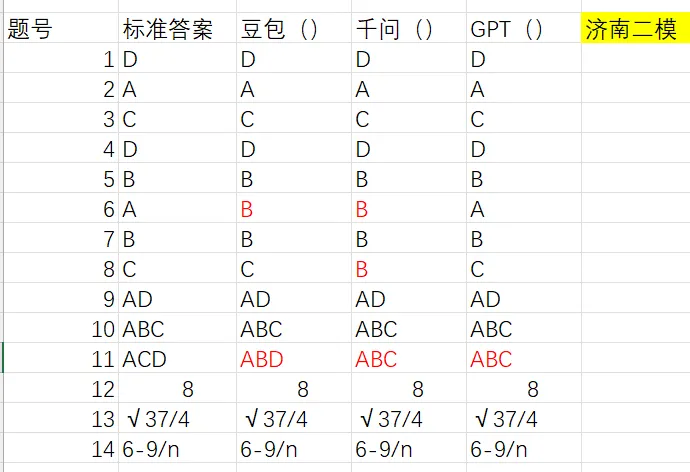
左右滑动查看更多
做着做着,新的异常冒了出来。


在头部四校的联考测试题的第一题,豆包和千问几乎都是秒级给出了同一个答案B,语气相当笃定;而另一边,ChatGPT不仅思考了足足一分钟,最后还认为答案错了。于是,笔者重新解了一遍题,解出来发现,ChatGPT的确是对的,是答案错了。为了把这件事再确认一遍,笔者甚至去找了985好友再次验证,最后得到的结论也一样:
这道题答案本身真的错了。
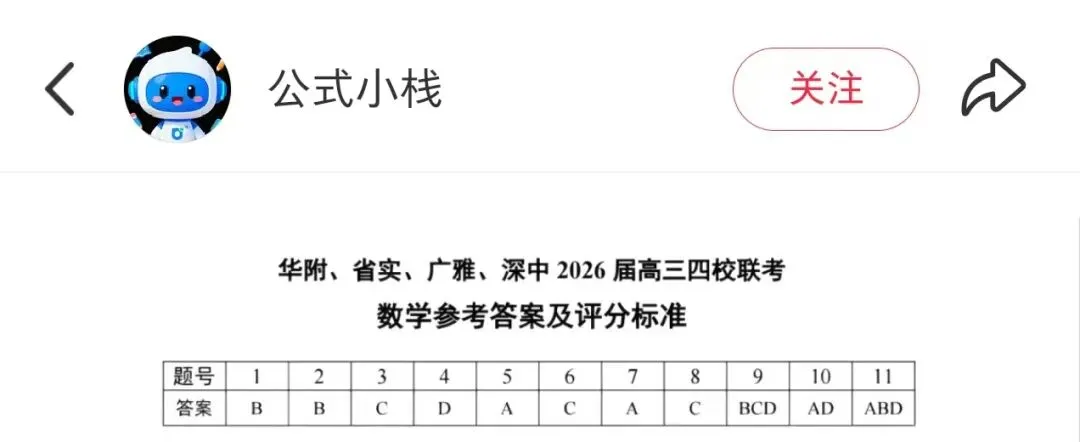
接下来,我又在第九题的测试过程中,第一次发现千问竟然直接能够匹配上该题原题的讲解视频,且打开时并没有显示外部引用来源,疑似直接消化了其他平台的视频,再化为自己的输出视频。

到这里,再回头看豆包和千问在第一题上的一致表现,感觉它们已经不只是“做错了一题”,而是太像直接接住了一个答案,即从网上命中了一个结果,再把它输出成了回答。
笔者这时候冒出一个更偏产品层面的想法。
回顾今年春节,大模型用户争夺战异常激烈,过年期间,各大厂甚至发钱抢用户。而对大多数普通用户来说,最先感知模型水平的第一印象从来不是模型推理深度,而是两个更直接的东西:回得快不快,准确率高不高。所以,厂商为了留住用户,不得已被夹在这两个目标之间:既不能真的全力释放推理能力(避免高峰期卡顿,影响用户第一印象),又不能让用户明显感觉到“它不行”。最后最容易出现的,就是一种很典型的折中——在普通场景里尽量把答案做得快、做得像对的,哪怕有时候这背后靠的不是完整推理,而是更高效的答案匹配和结果组织。
而现在距离春节仅仅过去了两个多月,厂商的算力释放策略有没有改,我们不得而知。

总结
测完了6套卷后,从测试结果可以看出,至少在正确率层面,几款AI的差距已经比较明显和稳定了。
豆包的表现明显强于千问,ChatGPT则略微领先于豆包,但领先的幅度不算太多。因此,本文可以大胆下一个结论:在日常生活以及学习中,豆包已经不是那个可以被轻易低估的“娱乐app”了。再加上Kimi需要付费,Deepseek没有识图能力,ChatGPT需要魔法,元宝的AI研发团队才刚步入正轨一年,文心一言赶了个早集却近乎原地踏步,最后胜出的,竟然还是我们的“国民级”AI豆包。
这篇文章写到这里,其实还只完成了一半。本篇更偏向是在看几款AI“能不能把答案做出来”;至于它们给出的思路清不清楚,解析质量和引导水平到底怎么样,这些更接近“适不适合学习”的部分,但由于这些写完会导致文章过长,所以笔者将把它们分开来讲。
下一篇会继续沿着这个方向,专门测一测AI解析题目的能力。欢迎点赞,留言,订阅,我们下篇见。
END
