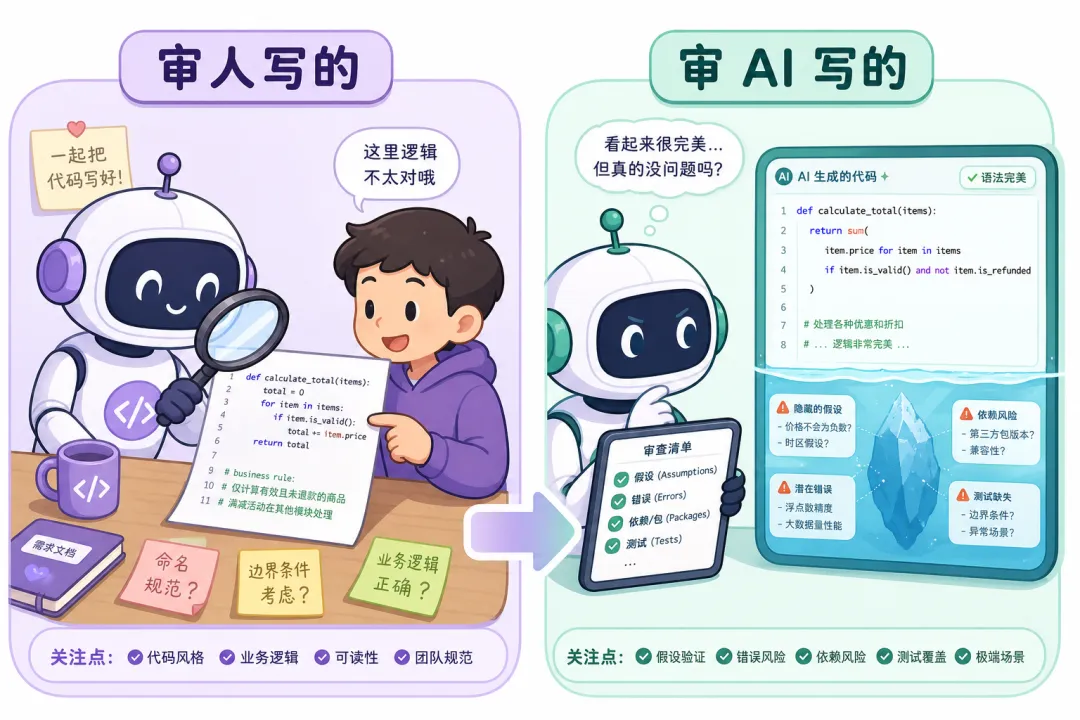
我发现审 AI 写的代码,和审同事的根本不该用同一套 checklist!!!ps:"checklist直译就是核对清单:一张纸或一页文档上列出要做哪几件事、按什么顺序、做完打勾,防止漏步、忘验证。"人写的代码, reviewer(审稿的人)心里有默认画像:这人会偷懒、会抄片段、会漏边界,但很少「一本正经地编造世界」。AI 写的代码反过来:语法往往更整齐,注释可能更勤快,却更容易在你看不见的地方「替你做决定」——把假设写进逻辑里、把失败吞掉、把不存在的依赖写得像真的一样。所以我把审 AI diff(一次改动里新增的代码片段)的流程,单独拉成一套 checklist。下面这几条,是我自己被坑过、也见过团队里重复踩的盲点。01 为什么说「用同一套标准」会翻车?
审同事的代码,你常问的是:「这段业务规则谁拍板的?异常怎么处理?有没有幂等(重复提交同一次操作,结果还一致)?」审 AI 的代码,你还要多问一层:「这些前提到底是谁写的字?」模型不会故意骗你,但它会补全——把「通常在教程里成立」当成「在你这台机器、这个版本、这份数据上一定成立」。代码看起来能跑通 happy path(最顺利的主流程),却在真实环境里无声歪掉。反面例子(简化但真实的一类):接口返回里 `user` 可能为空,人写的时候多半会愣一下、去翻文档;AI 有时直接写 `user.getProfile()`,再套一层「拿不到就返回默认值」。你一跑演示数据没问题,一上生产遇到空对象,要么静默失败(下面专讲),要么把默认当真理写进库。02 盲点一:假设过多(“常识”写进了 if)
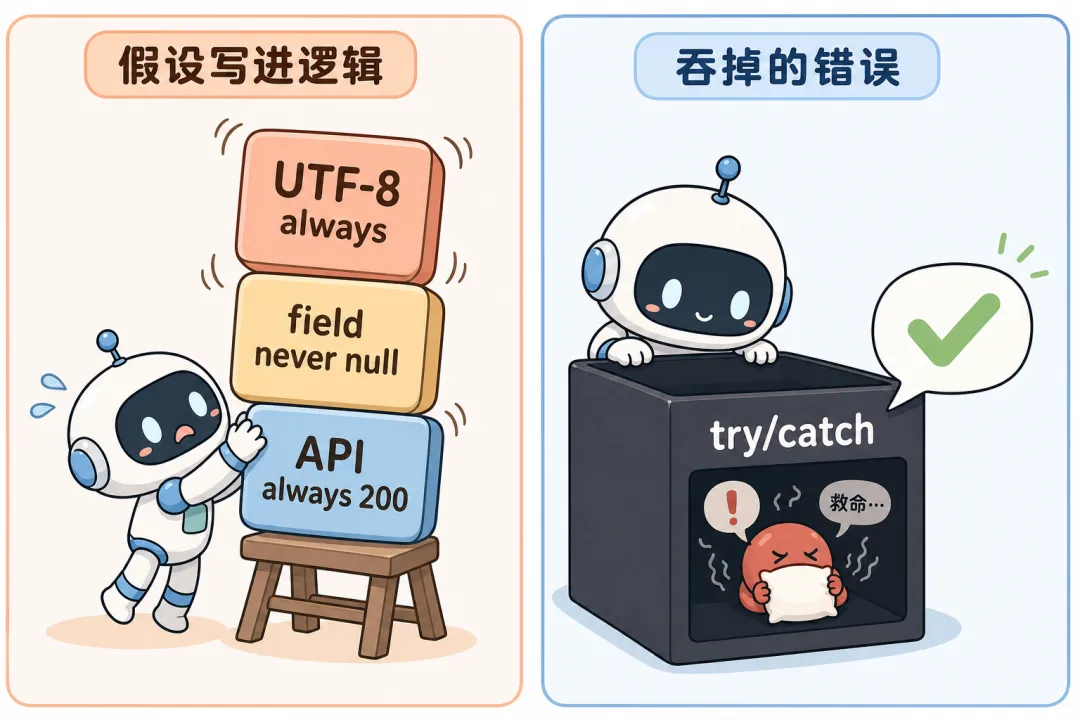
重点不是问「它写得对不对」,而是问:它假设了哪些「常识」。- 文件路径永远在、编码永远是 UTF-8、时区永远是 UTC 或本地
- 网络请求一次成功、超时永远可重试、重试绝不放大事故
把每个「理所当然」列成一条,能指到文档或配置,才算过关对外部输入(API / 文件 / 用户)默认「会坏、会缺、会变」空值、边界长度、重复请求,至少过一眼有没有显式分支
03 盲点二:silent failure(看起来像“成功”)
AI 很偏爱 try/catch 一大片然后 pass、catch 里只打一行 log、或者 返回 null / 空列表让调用方猜。这在 demo 里特别省心,在运维里特别要命:监控探针(检查服务是否健康的那套机制)不报警,业务指标却慢慢烂掉。反面例子:拉取第三方配额失败时 catch 住,返回 `quota = 0`,于是流程继续走「认为还有额度」。当天下午一切正常,半夜任务堆积你才发现从没有真正扣成功。异常是「必须被人看见」还是「可以吞」?吞的话业务状态有没有显式标记空结果语义:是没数据、失败、还是没权限?别让下游猜日志里能不能拼出 requestId / 关键字段,方便事后验尸
04 盲点三:依赖幻觉(包名像真的,世界不然)
模型推荐的 import、函数名、甚至「某某版本开始支持某参数」,有时会语法正确但事实不存在。人写 import 错了,编译器或 linter(静态检查工具)立刻打脸;AI 混在一大片新文件里,你一眼扫过去很容易漏。每个新依赖:lockfile(锁定版本的依赖清单)里真的出现吗?版本区间合理吗关键 API:对着官方文档点一下,别信“我记得是这样”升级/废弃:有没有 @Deprecated、breaking change(破坏性更新)说明
05 盲点四:测试缺口(只盖住了演示路径)
AI 生成测试很快,但常见模式是:照顾了当前输入,没照顾等价类(同一类该同样处理的输入)和反转条件。失败路径至少和成功路径一样「有名字」:超时、4xx/5xx、非法 JSON、部分字段缺失并发、重试、双写:有没有最小复现或压测笔记(哪怕很丑)快照测试(把输出整张截图式记下来对比)有没有把无关噪音也锁死,改一行文案就全红
06 一份可直接收藏的「审 AI Diff」短清单
可以把下面整块丢进备忘录,以后每次看 AI 改动按顺序勾:依赖:每个新包、新 API 是否真实存在、版本是否对齐测试:失败路径与边界是否有名有姓,而不只是 happy path安全:秘密进 env(环境变量)了吗?日志会不会泄 token可观测:关键步骤有没有可追溯的 log/metric(指标)最后补一条心态:审 AI 代码要更像审「新同事首次提交的 PR(一次合并请求)」——礼貌、鼓励,但标准要更硬一点。写到最后
同一套职业操守,两套细节标准:人写代码,你防的是经验和粗心;AI 写代码,你防的是过度自信式的补全。把 checklist 单独抄一份,不是为了否定工具,而是为了别让「看起来很工整」骗过你的眼睛。
如果你认同这样的表达,欢迎把文章转发给身边正在学习 AI 的朋友。愿每一次阅读,都不是信息的堆积,而是真正理解的开始。
 夜雨聆风
夜雨聆风