 夜雨聆风
夜雨聆风有人用 Claude Code 做规划和实现,用 Codex 做异步审查,半天就上线了一个带支付功能的 Garmin 数据转换工具。这篇文章拆解他的工作流,也聊聊我自己踩过的坑。
◉ ◉ ◉
事情是这样的
上周在 dev.to 上看到一篇帖子,标题很直白——"I shipped a paid web app in half a day using Claude Code + Codex"。
作者做了一个 Garmin 数据转换工具:把 Garmin Connect 导出的运动、睡眠、健康数据转成干净的 CSV 文件,方便丢给 ChatGPT、Gemini 或 Claude 去做分析。工具本身不复杂,但有几个点让我停下来认真看了——
他半天之内完成了:前端、后端、文件处理逻辑、支付集成(Square)、部署上线。一个人。
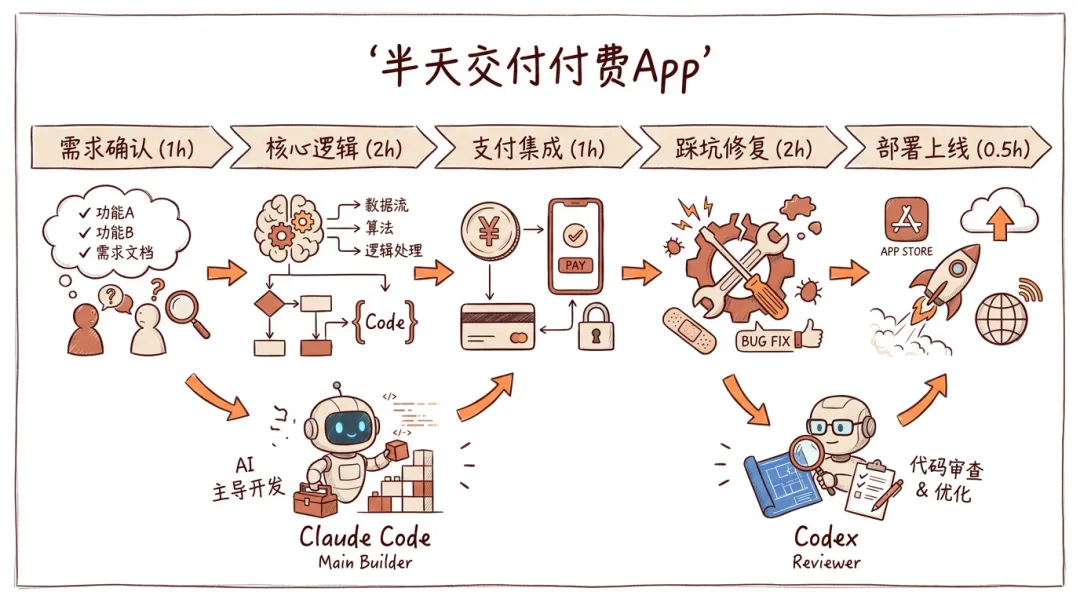
半天交付付费App的工作流
用的技术栈是 Claude Code(Opus 4.7)+ OpenAI Codex(GPT-5 Codex),两个 AI agent 分工协作。不是说"AI 帮我写了点代码"这种程度——他让两个 agent 各自负责不同的活。
我觉得这个案例值得好好拆一下。
◉ ◉ ◉
两个 Agent 怎么分工
这是最有意思的部分。
作者没有只用一个工具干到底。他给 Claude Code 和 Codex 安排了完全不同的角色:
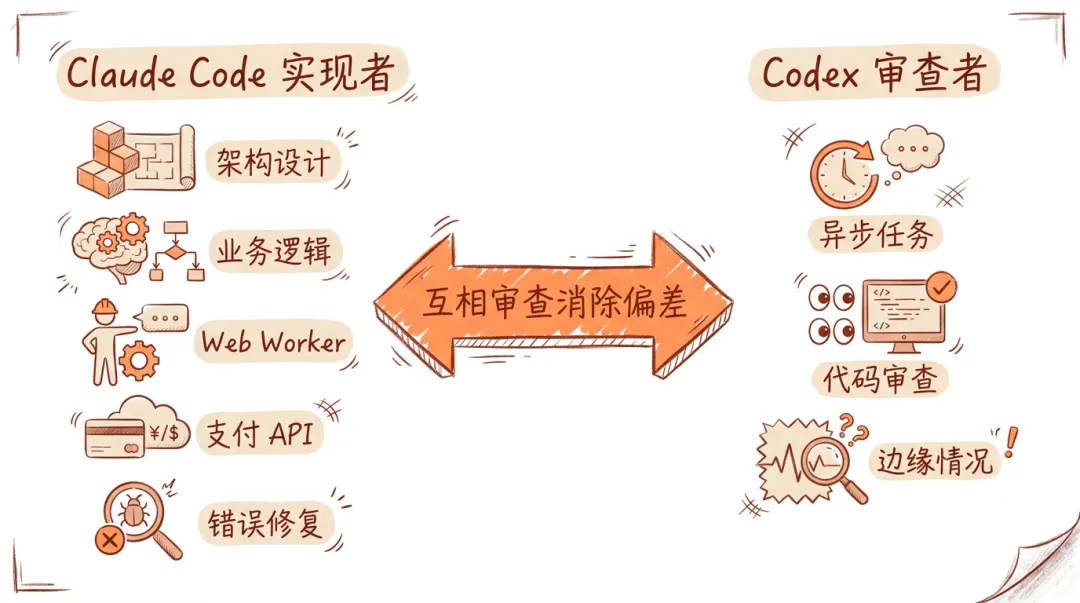
Claude Code和Codex分工示意
Claude Code(主力实现者):
- ❋负责整体架构设计
- ❋写核心业务逻辑(Garmin 数据解析、CSV 转换)
- ❋实现 Web Worker 来保持主线程响应
- ❋处理支付集成(跟 Square API 对接)
- ❋做最终的 bug 修复
Codex(异步审查者 + 并行任务):
- ❋被安排去处理一些可以异步跑的任务
- ❋做代码审查(review Claude Code 写的代码)
- ❋处理边缘场景和兼容性问题
关键来了:作者特意指出了一个问题。当 Claude Code 自己审查自己写的代码时,会产生"自我确认偏差"——它倾向于觉得自己写的代码没问题。所以他让 Codex 来做审查,两个不同的模型互相看,误差更容易被揪出来。
这个发现对我来说不意外,但他把它实际落地了。
◉ ◉ ◉
踩坑记录(这才是真实战)
帖子里列了几个具体的坑,我觉得比他的成功更有参考价值。
坑一:JSZip 的未文档化内部 API
处理 Garmin 导出文件需要解压 ZIP,他用了 JSZip 这个库。结果发现要处理的某些场景需要调用 JSZip 的内部 API,而这个 API 没有类型定义、没有文档。Claude Code 硬生生摸出了调用方法,但过程不顺——"没有 TypeScript 类型定义的第三方库内部 API"是 AI 编程最容易翻车的场景之一。
坑二:iOS Safari 的支付跳转问题
Square 支付链接在 iOS Safari 上有个特殊行为——跳转后回调 URL 的处理跟 Chrome 不一样。这种平台特异性的 bug,不管是人还是 AI 都很难提前预判,必须真机测了才知道。
坑三:大文件处理的内存问题
Garmin 的健康数据导出文件可以很大。最初的实现把整个文件读进内存,处理几百 MB 的文件时浏览器直接卡死。后来用 Web Worker 把重活移到后台线程,主线程才恢复响应。
这三个坑加起来,大概就是"半天"里的大头时间。核心逻辑写完可能只要一两个小时,剩下都在跟这些边缘问题搏斗。
◉ ◉ ◉
我自己在用 Claude Code 做项目时也有类似经历。上个月做一个微信公众号自动化工具,核心功能(调 API、生成文章、上传图片)一下午搞定了。但是处理微信 CDN 的防盗链、处理 HTML 排版在不同微信客户端的渲染差异、处理图片上传的并发限制——这些"脏活"又花了两天。
所以我的经验总结是这样的:AI 把"写代码"这件事加速了 5-10 倍,但"踩坑"这件事一点没变快。
◉ ◉ ◉
我自己的 Claude Code + Codex 搭配方式
看完那篇帖子后,我重新梳理了一下自己的工具搭配。跟大家分享下目前用得最顺手的模式。
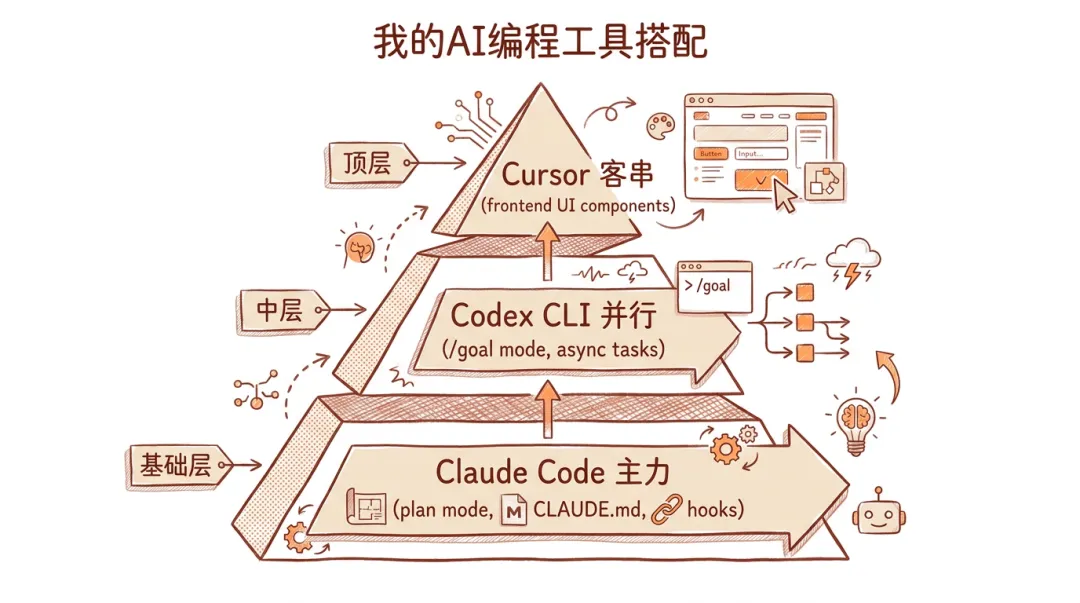
我的AI编程工具搭配
日常主力:Claude Code
说实话,大部分时间我只开 Claude Code。它的优势在于:
- ❋能看到整个项目上下文,跨文件改东西很顺
- ❋plan mode 先让它出方案,确认了再动手,减少返工
- ❋
CLAUDE.md文件可以把项目约定(技术栈、命名规范、禁止事项)固化下来,每次新 session 自动加载 - ❋hooks 机制可以强制执行一些规则——比如编辑完自动格式化、提交前自动跑 lint
我在 CLAUDE.md 里写的东西大概长这样(简化版):
## 技术栈 - Python 3.11, requests, pyyaml - 不要用 async,这个项目全是同步的 - 图片处理用 PIL,不要引入 opencv ## 命名规范 - 变量名 snake_case - 文件名也是 snake_case - commit message 中文,一句话说清楚改了什么 ## 禁止事项 - 不要在代码里硬编码 API key - 不要动 wechat-publisher.yaml(那是密钥文件)
这几行字省了我无数次"不是让你别动这个文件吗"的抓狂。
并行任务:Codex CLI
Codex 我主要用来跑"我知道要做什么但不想等"的任务。比如:
- ❋让它去另一个分支上写测试,我继续在主分支写功能
- ❋让它去做文档更新
- ❋让它做代码审查(review 完我回来看结论就行)
Codex 的 /goal 模式特别适合这种场景——你给它一个高阶目标("把这个模块的测试覆盖率从 40% 提到 80%"),然后去忙别的。过一会儿回来看结果。
偶尔客串:Cursor
写前端组件的时候我会切到 Cursor,因为它的 Composer 模式在 VS Code 里改 UI 代码有即时预览,体感比在终端里盲改舒服。但大部分后端和脚本工作还是在 Claude Code 里完成。
◉ ◉ ◉
几条实操建议(都是花钱买来的教训)
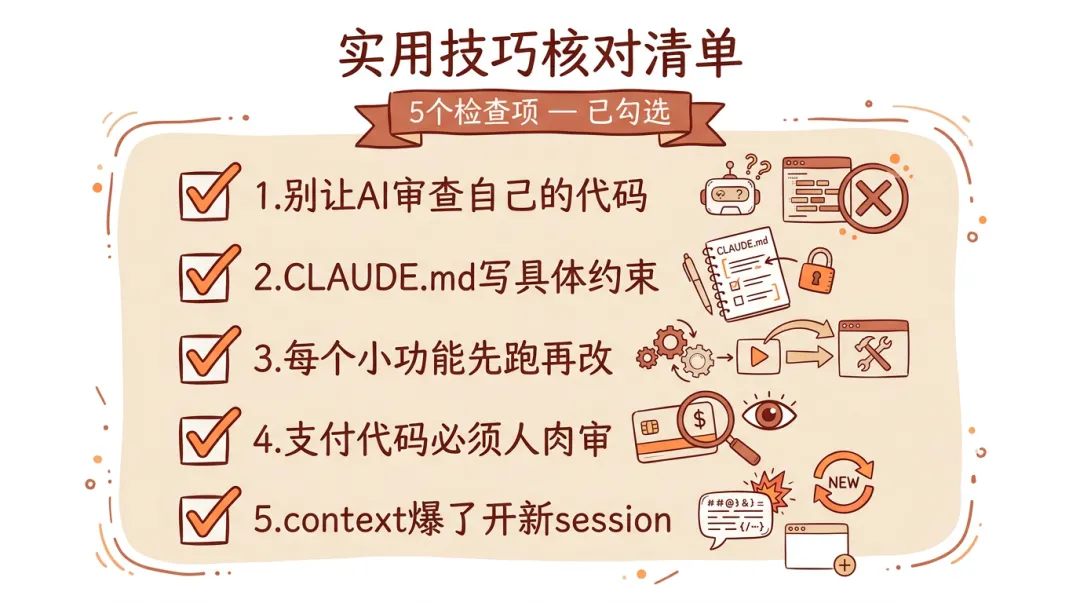
实操经验清单
写了这么多,压缩几条最实用的:
1. 别让 AI 审查自己的代码
前面说了,自我确认偏差是真实存在的。如果你用 Claude Code 写代码,让 Codex 来审查——反过来也行。两个不同的模型互相看,能揪出更多问题。我试过让同一个 Claude Code session 先写再审,它真的会说"代码看起来没问题"然后实际跑起来炸了。
2. CLAUDE.md 写具体,别写废话
"请保持代码整洁"——这种话写了等于没写。要写具体的约束:"函数不超过 50 行"、"不要用 any 类型"、"这个目录下的文件不要动"。
3. 先跑一次再让 AI 修
AI 生成的代码不经测试就直接往下走,是最大的时间黑洞。我现在的习惯是:每完成一个小功能就手动跑一次。如果有问题,把错误信息直接贴给 Claude Code,它修起来比你描述问题快得多。
4. 支付和安全相关的代码,必须人肉过一遍
那个 Garmin 工具的作者也说了——唯一的服务端代码就是 Square 支付链接的 API route。这种涉及到钱的代码,不管 AI 写得多好,你都得自己逐行看一遍。
5. context 快爆了就开新 session
我在 Claude Code 里遇到过好几次"越聊越糊涂"的情况。原因是 context window 塞满了早期的探索性对话,模型开始在过时的上下文里做决定。我的做法是:感觉不对劲了,直接开一个新 session,把到目前为止的结论写进 CLAUDE.md,让新 session 从干净的状态开始。
◉ ◉ ◉
◉ ◉ ◉
这个工作流的适用边界
我得说清楚——"半天做出付费 app"有它的前提条件。
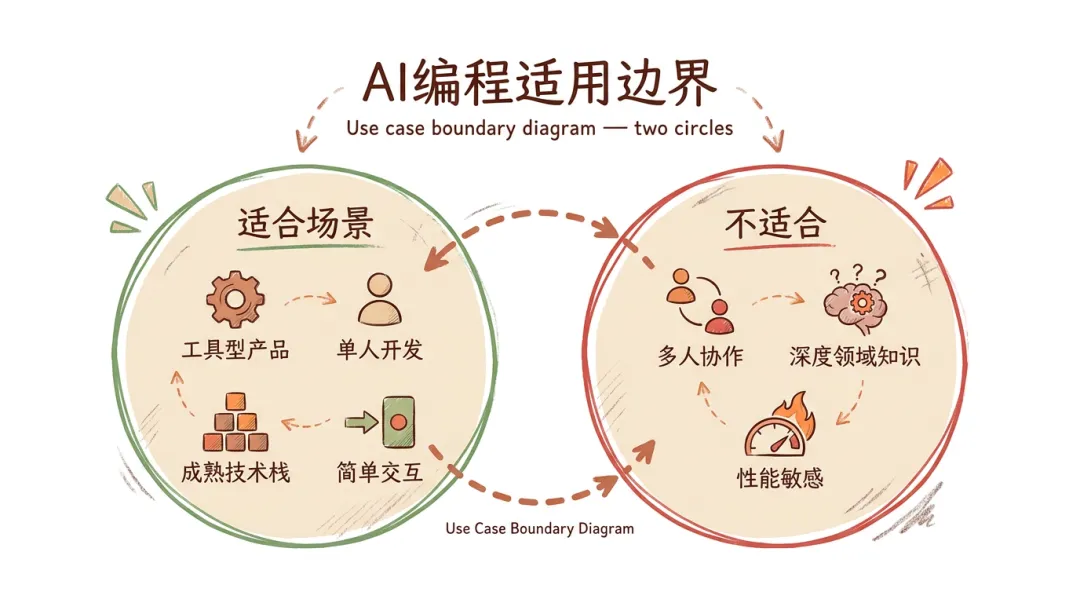
适用边界说明
适合这个工作流的场景:
- ❋工具型产品(输入 → 处理 → 输出,逻辑链短)
- ❋单人开发
- ❋技术栈成熟(Next.js / Vercel / Supabase / Stripe 这些 AI 训练数据里大量覆盖)
- ❋不需要复杂的用户交互(没有实时协作、没有复杂权限系统)
不适合的场景:
- ❋多人协作的大项目(AI 不擅长理解团队约定和沟通成本)
- ❋需要深度领域知识的场景(金融合规、医疗器械、法律文书)
- ❋性能敏感场景(高并发、低延迟、资源受限设备)
说白了,AI 编程工具目前最擅长的是:"一个有经验的开发者,做一个自己能独立搞定的小产品,但希望把实现速度提高 3-5 倍。"
如果你是这个描述的人——Claude Code + Codex 的搭配确实值得一试。
◉ ◉ ◉
写在最后
半天做出付费 app 不是什么神话。它的关键不在于"AI 很强",而在于工具搭配得当 + 人知道什么时候该介入。
2026 年做独立开发者,工具的丰富程度确实前所未有。但工具再强,踩坑还是免不了的——只是坑的种类变了。以前是"怎么写这段代码",现在是"怎么让 AI 别在这里犯蠢"。
如果你也在用 Claude Code 或者 Codex 做项目,欢迎在评论区分享你的工具搭配和踩坑经历。这种一线体验比任何评测文章都有价值。
