 夜雨聆风
夜雨聆风danielmiessler/Personal_AI_Infrastructure ⭐13,153 | v5.0.0 | 今日 GitHub Trending
2016年,一个网络安全专家写了一本没人在意的小册子,预言了"每个人都将拥有一个私人数字助理"。
那时距离 ChatGPT 还有整整6年。
今天,这个人叫 Daniel Miessler,他把那个预言,一行一行地写成了代码。
项目名叫 Personal AI Infrastructure,简称 PAI。今天登上 GitHub Trending,当前版本 v5.0.0,13,153 颗星,1,850 个 Fork。
他是谁?
Daniel Miessler 不是典型的 AI 创业者。
他的起点是网络安全。2012年,他的第一个 GitHub 项目是 SecLists——一个渗透测试字典文件合集,把散落在各处的测试材料集中起来,至今 70,891 星,是全球网络安全工程师的日常武器。他的职业生涯从"如何攻破系统"开始,这让他天然对"系统如何失败"有着异乎寻常的敏感。
2024年,他推出了 Fabric,一套把 Prompt 工程化的命令行框架,迅速收获 41,686 星。Fabric 的逻辑很简单:把好用的 Prompt 变成可复用的"Pattern",像管道一样调用 AI 能力——extract_wisdom、create_summary、analyze_paper……直接拼接,没有废话。
但 Fabric 只是他在 AI 时代的第一步。
Personal_AI_Infrastructure(PAI),才是他真正想做的东西。他在 GitHub 自我描述只有一句话:"⚒️ Building AI that ᴜᴘɢʀᴀᴅᴇs humans."
那本2016年的预言之书
2016年,Miessler 写了《The Real Internet of Things》(简称 TRIOT)。
当时"物联网"是烂大街的热词,大家谈的都是智能冰箱、联网门锁。Miessler 的视角完全不同——他不从技术出发,而从人类10万年不变的欲望出发反向推演。他认为技术只是容器,容器的形式会变,但人类对亲密关系、影响力、变得更强大的渴望是永恒的。
书里有一段话,是 PAI 整个项目的情感原点:
有很多进入上层阶级的人指出,没有什么比拥有一个优秀的私人助理更能放大一个人的生产力和个人效能。
私人助理,从来是少数人的特权。顶级 CEO 能同时推进十件事,不是因为他们更聪明,而是因为有人替他们处理信息、安排日程、跟进细节。普通人没有这个资源,所以强者越强。
Miessler 的结论:AI 的历史意义,就是把这个特权民主化。
他在书里预言了四件事:
- • 每人一个数字助理(DA)——不是 App,不是网站,是一个了解你、代表你、替你行动的实体
- • 万物 API 化——每个物体、每个人、每个服务都有可交互的数字接口
- • DA 动态生成你的界面——不再有固定 App,DA 在需要时即时组装你需要的视图
- • 你定义理想状态,AI 帮你实现——人负责定义"好",AI 负责执行
今天回头看,这四件事正在同时发生。而 PAI,是他把这四件事写成代码的尝试。
从 v2 到 v5:一部浓缩的进化史
PAI 的版本演进本身就是一个故事。
| 版本 | 时间 | 关键转变 |
|---|---|---|
| v2.0.0 | 2025-12-28 | 第一个正式发布版,模块化架构,Claude Code 原生设计 |
| v2.3.0 | 2026-01-15 | 引入持续学习系统,捕捉显式/隐式评分信号 |
| v2.4.0 | 2026-01-23 | The Algorithm 诞生,引入 ISC(理想态标准)追踪,首次定义"Euphoric Surprise"作为输出质量指标 |
| v2.5.0 | 2026-01-30 | 思考工具集成(Council、RedTeam、FirstPrinciples) |
| v3.0.0 | 2026-02-15 | Algorithm 成熟,持久化项目文档,完整安装向导,Agent 团队/蜂群支持 |
| v4.0.0 | 2026-02-27 | "精简与强悍"——38个扁平 Skill 目录重组,Algorithm 从 v1.4 跃升至 v3.5 |
| v5.0.0 | 2026-04-30 | "生命操作系统"——Pulse 统一守护进程、DA 身份层、Algorithm v6.3.0、ISA 原语,45 个 Skills |
三个阶段清晰可见:
- • 工具阶段(v2.x):模块化 Prompt 工程 + 记忆系统
- • 系统阶段(v3.x–v4.x):算法驱动 + 安全加固
- • 操作系统阶段(v5.x):从"帮你干活"升华为"帮你成为你想成为的人"
PAI 不是一个工具,是一个操作系统
v5.0.0 的 README 正中央有一行字:
AI should magnify everyone—not just the top 1%.
这不是营销口号,是一种政治宣言。
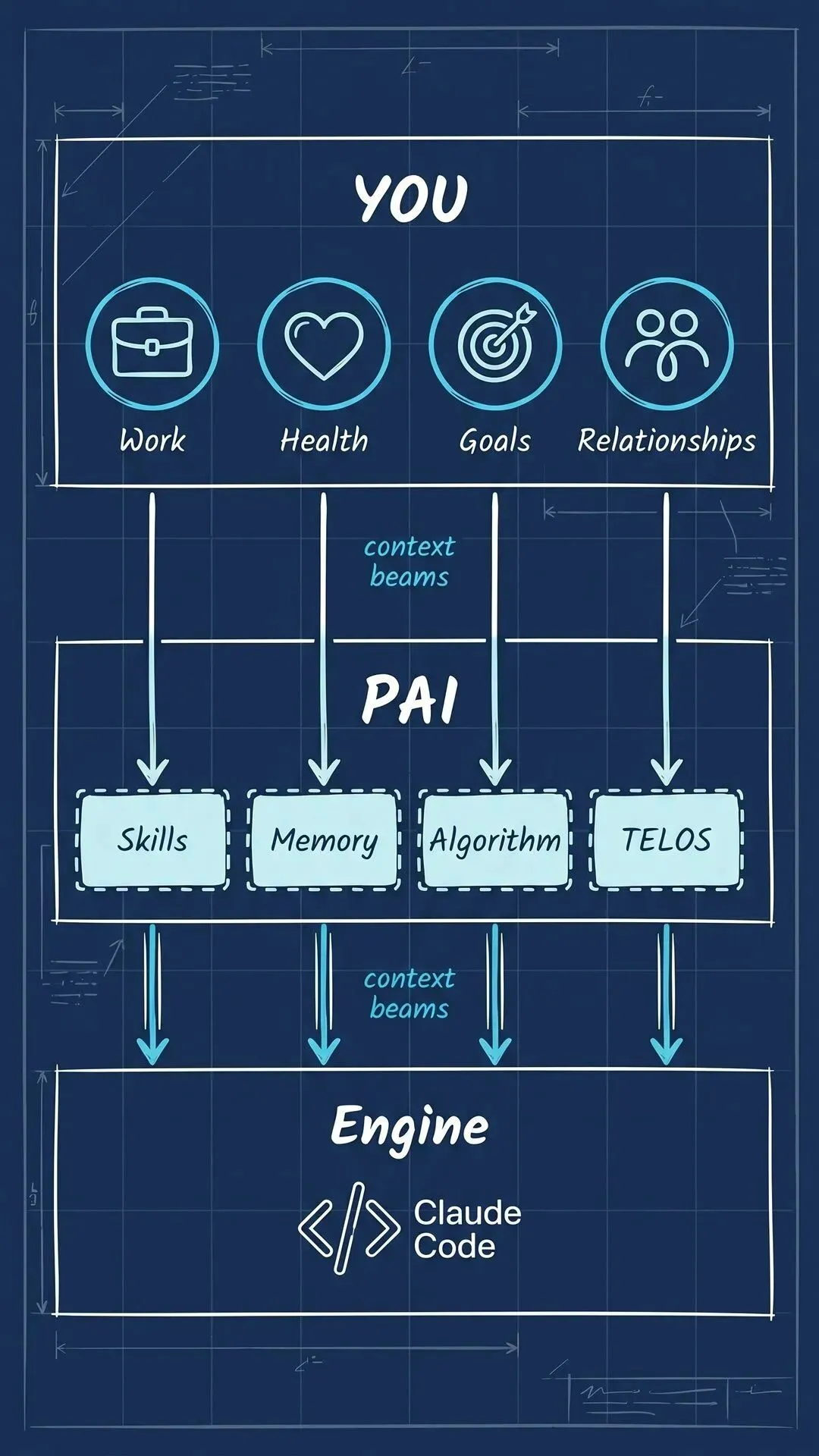
PAI 的自我定位是 Life Operating System(生命操作系统)。它的三层架构让这个说法不再是玄学:
你(Work / Health / Goals / Relationships / Finances / Learning)
↑ context beams(上下文光束)↑
PAI(OS 本体:Skills + Memory + Algorithm + TELOS)
↑ context beams(上下文光束)↑
底层引擎(Claude Code / OpenCode / Pi)第一层:PAI 本体,是操作系统的内核。45个 Skills、171个 Workflows、37个 Hooks,以及最重要的:你的 TELOS——你的人生使命、目标、信念、智慧的结晶文件。系统里所有的优化,都指向这里定义的"理想态"。
第二层:Pulse,是守护进程。单一 Bun 进程,端口 31337,替代 v4.x 时期所有分散的语音/监控/调度脚本。它开机自启,作为 macOS launchd 服务(com.pai.pulse)在后台运行,并带有一个菜单栏 App。
第三层:DA,是你的数字助理。它有名字,有 ElevenLabs 的声音,有个性,有颜色。安装完成后,你运行 /interview,DA 会引导你为它命名,设置声音,然后采集你的 TELOS。
官方说得很直白:"Without TELOS, your DA has nothing to optimize against."
没有目标,AI 优化的方向就是空的。
TELOS:先告诉 AI 你想成为谁
TELOS 是 PAI 里最不像"技术概念"的技术概念。
它是一个目录(PAI/USER/TELOS/),里面存放着你的使命(Mission)、目标(Goals)、信念(Beliefs)、智慧(Wisdom)、挑战(Challenges)和叙事(Narratives)。
安装 PAI 后,/interview 命令会带你经历四个阶段:
- 1. TELOS 采集:你的使命是什么?你正在努力实现什么目标?你遇到的最大挑战是什么?
- 2. 理想态描述:对你来说,成功是什么样的?
- 3. 偏好采集:工具、惯例、工作风格
- 4. DA 身份调优:DA 的个性最终定型
两份核心文件在每次 Session 启动时自动加载:
- •
PAI/USER/PRINCIPAL_IDENTITY.md——"你是谁":姓名、角色、地点、世界观、偏好、工作模式 - •
PAI/USER/DA_IDENTITY.md——"DA 是谁":名字、声音 ID、个性、写作风格、喜欢什么、不喜欢什么
这个设计说明了 PAI 和普通 AI 工具的本质区别:普通工具每次从零开始,PAI 永远知道你是谁、要去哪里。
Algorithm v6.3.0:把 AI 的主观判断变成确定性流程
PAI 最核心的创新不在于功能数量,而在于一套叫 The Algorithm 的执行协议。
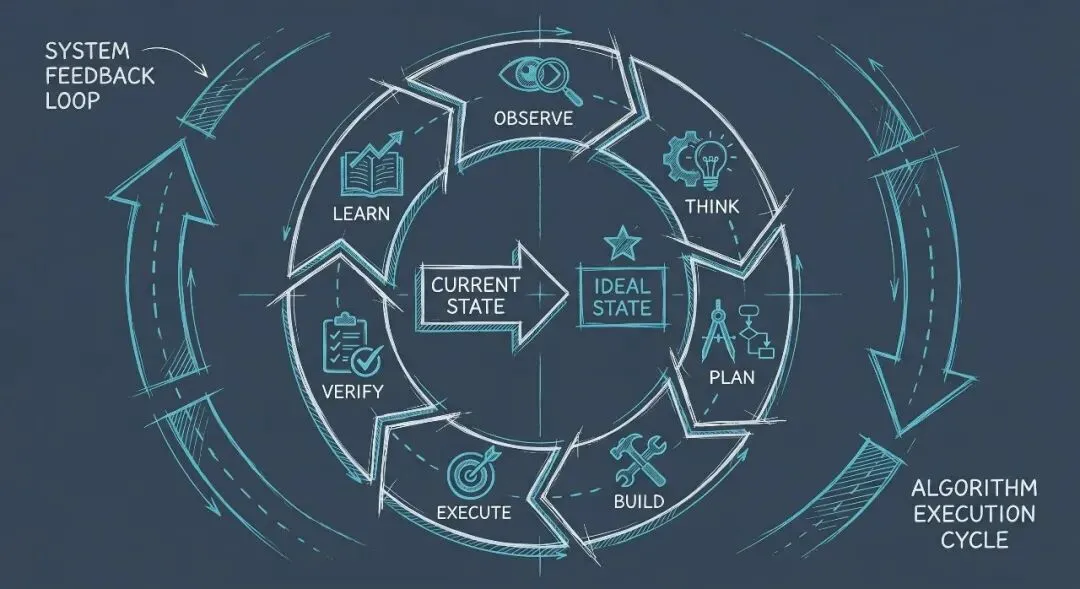
任何"非平凡任务"都必须经历七个阶段:
OBSERVE → THINK → PLAN → BUILD → EXECUTE → VERIFY → LEARN这不是新鲜概念——类似科学方法的循环。真正独特的,是 PAI 怎么强制执行它。
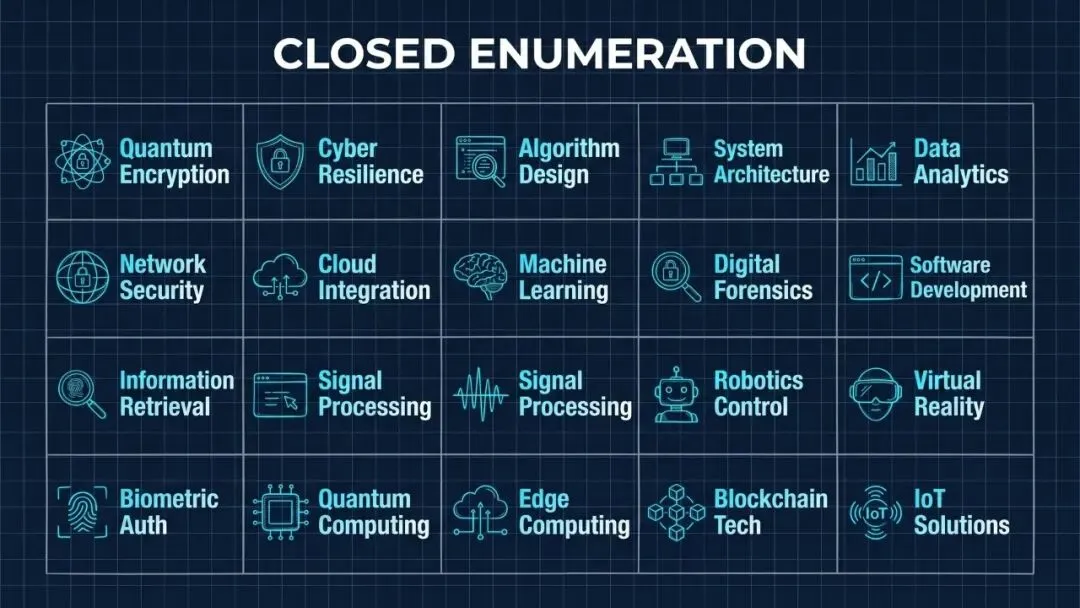
封闭的能力词汇表
v6.3.0 规定,AI 在 THINK 阶段选择"思考能力"时,只能从19个固定名字里选:
IterativeDepth / ApertureOscillation / FirstPrinciples / SystemsThinking / RootCauseAnalysis / Council / RedTeam / Science / BeCreative / Ideate / BitterPillEngineering / Evals / WorldThreatModel / FeedbackMemoryConsult / Advisor / ReReadCheck / ContextSearch / ISA / Fabric patterns
任何不在列表里的名字,比如"deep reasoning"、"structured thinking"、"first-principles decomposition",都是"幽灵能力"(phantom capability),属于 CRITICAL FAILURE,不计入任何评分。
这个设计的妙处在于:它把 AI 的能力选择从"模糊的自我描述"变成了"可审计的精确声明"。你可以查日志,看 AI 到底调用了什么。
Sonnet 分类器:不让执行者自己判断
每次用户提交请求,PromptProcessing.hook.ts 先调用 Sonnet 模型分类:
- • MINIMAL:打招呼、一个字回答
- • NATIVE:查一个事实、改一行代码
- • ALGORITHM:其他一切
同时判断努力等级(E1–E5),写入上下文:
MODE: ALGORITHM
TIER: E3
REASON: multi-file refactoring task
SOURCE: classifier执行者严格听从分类器,不做自己的判断。如果分类器超时(25秒),默认 ALGORITHM E3——保守失败,不是乐观失败。
努力等级与资源下限
| 等级 | 时间预算 | ISC 最低数量 | 思考能力(不可豁免) |
|---|---|---|---|
| E1 | <90秒 | 无 | 0-1 |
| E2 | <3分钟 | ≥16 | ≥2 |
| E3 | <10分钟 | ≥32 | ≥4 |
| E4 | <30分钟 | ≥128 | ≥6 |
| E5 | <2小时+ | ≥256 | ≥8 |
验证铁律:不许说"should work"
VERIFY 阶段有四条不可豁免的规则:
- 1. 所有用户可见的制品,必须 live-probe——截图、curl、实际输出
- 2. 多步骤 ISA 的承诺边界须调用 Advisor(第二意见)
- 3. E4/E5 还需 Cato(GPT cross-vendor 审计),给出 pass / concerns / fail 三级判定
- 4. 实验结果与 Advisor 矛盾时,不得静默切换,须带冲突重新调用
"should work"、"expected to"、"done"——没有工具证据时,这些词是禁语。
这套机制解决了 AI 使用中最常见的问题:AI 不知道什么叫"完成"。 Algorithm 通过 ISC(Ideal State Criteria)把"完成"变成可验证的二元列表——每条 ISC 未经工具调用证明,不得打勾。
ISA:把 PRD 变成一个五合一文件
PAI v5.0.0 最难理解、也最值得深挖的概念,叫 ISA(Ideal State Artifact,理想态制品)。
传统的工作流是:写需求文档 → 写测试计划 → 验收 → 归档。四份文件,各自独立,经常对不上。
ISA 把这四件事坍缩为一份文档,同时扮演五个角色:
- 1. 理想态阐述——用 David Deutsch "难以变动的解释" 标准描述"完成"是什么样
- 2. 测试框架——每条 ISC 都是一个带具名工具探针的测试用例
- 3. 构建验证——通过 ISC = 验证了构建物
- 4. 完成条件——所有 ISC 通过 = 任务完成
- 5. 系统记录——该事物的规范性真相来源
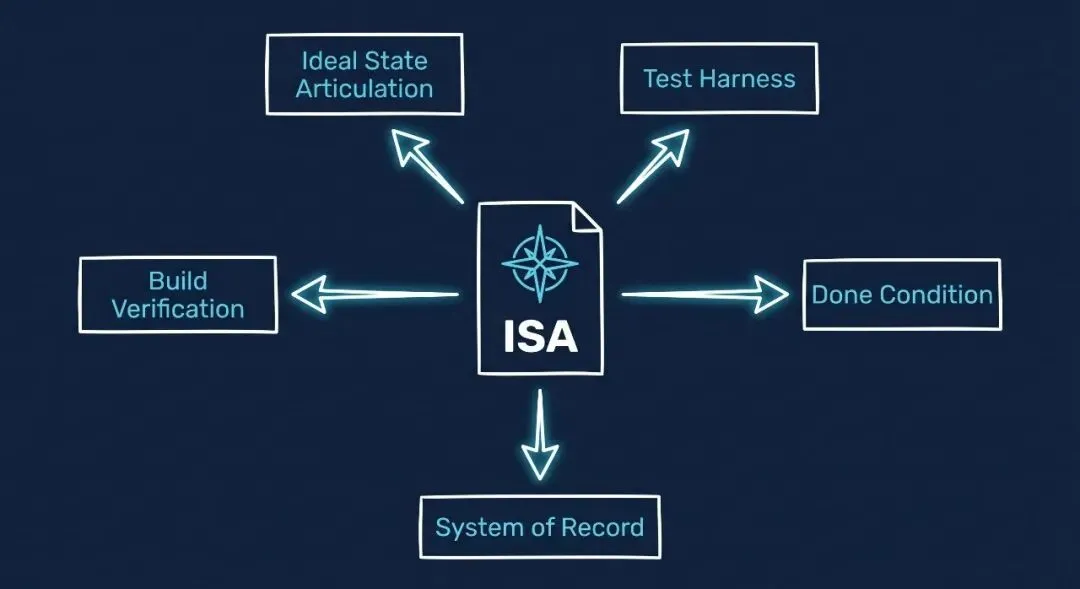
ISA 有12个固定章节,顺序不可更改:
Problem → Vision → Out of Scope → Principles → Constraints → Goal → Criteria → Test Strategy → Features → Decisions → Changelog → Verification
注意 Out of Scope 排在第三位——在描述目标之前,先声明不做什么。这是一个反常识但极其重要的设计:反愿景比愿景更能防止范围蔓延。
ISC 的编号有严格的稳定性规则:永不重排。分裂变为 ISC-N.M,删除变为墓碑标记(- [ ] ISC-N: [DROPPED — see Decisions])。这样你可以追溯每一个决策变化的完整历史,而不会因为编号变动破坏引用。
Changelog 的格式也有严格规定,必须包含四部分:
conjectured(我们猜测的)
refuted_by(被什么推翻)
learned(学到的)
criterion_now(标准现在是什么)这是 Deutsch 的认识论——知识增长不是积累,而是猜想与反驳的循环。PAI 把这个哲学直接写进了工程规范。
ISA 有两个"家":
- • 项目 ISA:
<project>/ISA.md——有持续身份的事物(App、CLI 工具、内容管线),迭代项目 = 迭代 ISA - • 任务 ISA:
MEMORY/WORK/{slug}/ISA.md——一次性任务
ISA Skill 提供六个工作流:Scaffold(从 prompt 生成)、Interview(对话采集)、CheckCompleteness(完整性验证)、Reconcile(临时文件合并)、Seed(已有项目初始化)、Append(规范追加)。
Memory:三层记忆,复利增长
PAI 的记忆系统是它与一次性 AI 工具最根本的分野。
记忆分三层:
- • WORK(工作记忆):
MEMORY/WORK/{slug}/,每个任务的 ISA、草稿、工具输出,任务完成后归档 - • KNOWLEDGE(知识库):
MEMORY/KNOWLEDGE/,整理后的领域知识,用rg(ripgrep)全文检索 - • LEARNING(学习记录):
MEMORY/LEARNING/,显式评分信号、隐式满意度捕捉、Algorithm 反思
每个 Session 结束后的 LEARN 阶段,新知识按类型路由
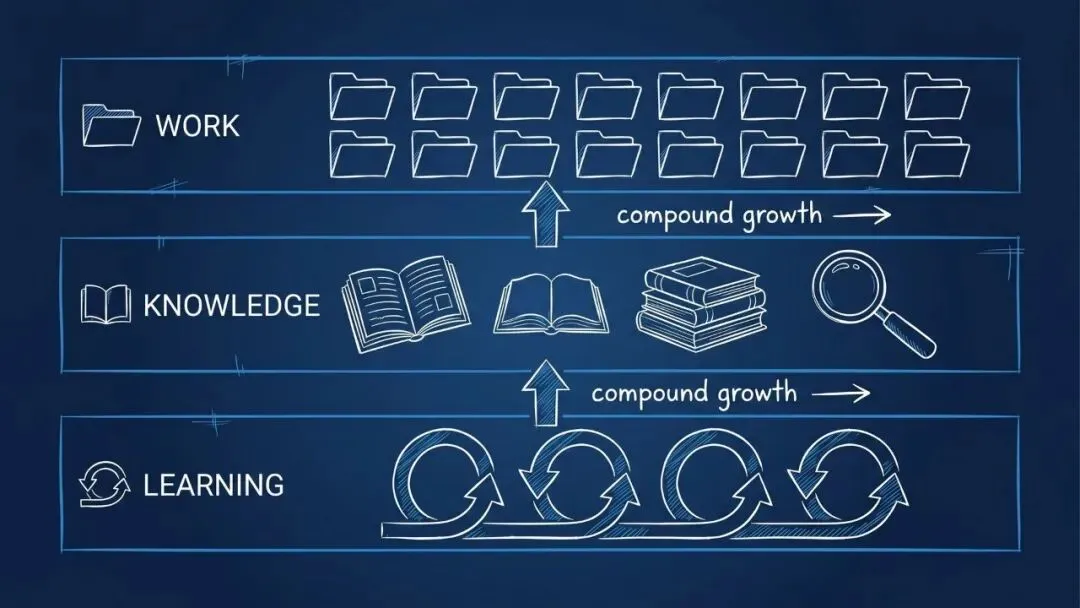 :
:knowledge → 写入 KNOWLEDGE 库;rule → 追加到 CLAUDE.md;pattern → 归入可复用模式库。
还有一个 typed knowledge graph,横跨 people(人)/ companies(公司)/ ideas(想法)/ research(研究)四类实体,用纯文本 Markdown + 交叉引用维护,不用数据库,不用 RAG,rg 搜索比嵌入检索更快、更准确。
这就是 README 里那句话的含义:"Filesystem as context, no RAG." PAI 自2025年6月就放弃了 RAG——它认为有交叉引用的富文本 + fast search,已经覆盖了 RAG 能做的一切,而且没有嵌入复杂度、检索不稳定性、保真度损失的代价。
Pulse:你的 AI 守护进程,端口 31337
Pulse 是 v5.0.0 里最"有形"的新东西——你能直接看到、听到、摸到它。
一个 Bun 进程,一个端口(31337),一个 launchd plist,一个日志文件。它替代了 v4.x 时期所有分散的语音/可观测性/Hook 脚本。功能清单:
| 模块 | 说明 |
|---|---|
| Voice Notifications | ElevenLabs TTS,/notify 端点,每个 Algorithm 阶段切换时播报语音 |
| Hook Execution | 管理整个 PAI 生命周期的 Hook(SessionStart / PreToolUse / PostToolUse / Stop 等) |
| Observability | 工具活动追踪、失败记录、满意度信号、Algorithm 反思日志 |
| Cron Scheduling | 常规任务和循环作业的定时调度 |
| Life Dashboard | http://localhost:31337,Next.js 应用,22 条路由 |
| Wiki API | 通过 HTTP 暴露 KNOWLEDGE 知识档案 + 系统文档 |
| DA Messaging | Telegram bot、iMessage 桥接、DA 主动触达通道 |
Life Dashboard 的 22 个路由页面值得单独说一下:Life、Health、Finances、Business、Work、Telos、Goals、Air、Performance、Hooks、Skills、Agents、Security、Knowledge、Knowledge Graph、System Docs、System Graph、Arbol、Ladder、Novelty、Assistant、root。
这已经不是一个"工具"的概念了。这是一个仪表盘,覆盖了你生活的每一个维度。
45 个 Skills:一个知道什么时候用锤子的大脑
Fabric 有数百个 Prompt Pattern(锤子),PAI 有45个 Skills(知道什么时候用锤子的大脑)。
Fabric 是你叫它干什么它就干什么,PAI 的 Skills 是自激活的——Algorithm 在 OBSERVE 阶段根据任务意图自动选择能力。
Skills 的设计层级:
代码(实际执行逻辑)
↑
CLI(调用代码的命令行接口)
↑
Workflows(Prompt 序列)
↑
SKILL.md(前门路由器)核心原则:Prompts 包装代码,代码不包装 Prompts。 能用确定性代码解决的事,绝不用不确定的提示驱动。
45个 Skills 按集群分布:
THINKING(思维工具)
- • Council:多智能体协作辩论,可见的逐轮发言记录,让分歧真实呈现
- • RedTeam:32个对抗 Agent 压力测试,找出你看不到的漏洞
- • ApertureOscillation:三遍视角振荡——战术 → 战略 → 综合,在每个缩放层级上保持问题不变
- • FirstPrinciples:物理学风格的解构/挑战/重建
- • WorldThreatModel:11个视野的威胁压力测试
CONTENT(内容生成)
- • Art:图片/Mermaid 图表/技术架构图/分类矩阵,集成 Flux、GPT-Image-1
- • WriteStory:结构化叙事创作
- • Fabric 集成:240+内置 Pattern,直接通过
Skill("Fabric", "extract_wisdom")调用 - • ExtractWisdom:从任意内容中提取结构化洞察
RESEARCH(研究工具)
- • Research:4种深度模式(fast / standard / deep / comprehensive)
- • ArXiv:搜索论文 + AlphaXiv 增强的 AI 概述
- • Knowledge:从 KNOWLEDGE 库中检索先验知识
- • Investigation / PrivateInvestigator:深度调查流程
AGENTS(智能体编排)
- • Agents:8种预定义功能团队(工程/架构/营销/设计/安全/研究/内容/战略)+ 自定义 Agent 组合
- • Delegation:6种并行化模式的路由表(内置 Agent / Worktrees / 后台 Agent / 自定义 Agent / Agent 团队 / Agent OS)
- • Browser:持久化认证的无头浏览器
BUILD(构建工具)
- • ISA:理想态制品的全生命周期管理
- • CreateSkill:新 Skill 脚手架 + 规范化 + 有效性测试
- • CreateCLI:生产级 TypeScript CLI 生成
- • Loop:迭代构建循环
- • Evals:代码/模型/人工评分器
数量演进:v3.0 有 41 个,v4.0.3 有 36 个叶技能,v5.0.0 有 45 个独立顶层 Skills,每一个都可以独立调用。
隐私是结构性的,不是口头承诺
PAI 对隐私的处理方式,让安全背景出身的 Miessler 本色尽显。
隐私不是靠 README 里的"我们尊重你的隐私",而是用文件系统约束强制执行:
- • :TypeScript 模块,声明每个目录的隐私区域,是前瞻性和回溯性执行的单一真相来源
- • (PreToolUse Hook):拦截任何会把敏感内容写到区域外的 Write/Edit/MultiEdit 操作
- • :公开发布构建器,必须通过 12道安全门控:
G1 区域删除 → G2 身份信息扫描 → G3 Cloudflare ID 扫描 → G4 trufflehog 密钥检测 → G5 .env 文件检查 → G6 私有 token 扫描 → G7 引用完整性验证 → G8 私有 Skill 引用检查 → G9 用户名路径扫描 → G10 暂存启动测试 → G11 Dashboard 泄露检查 → G12 USER/MEMORY 模板验证
- • 两阶段发布:Stage 1 暂存并通过全部12道门,Stage 2 发布 GitHub,两阶段永不自动串联——人工确认才能走到 Stage 2
这套设计的逻辑:你在 PAI 里存放的是最私密的东西——人生目标、人际关系、财务状况。这些信息不能靠"相信我们不会泄露"来保护,要靠代码在发布流程里物理隔离。
PAI vs 同类项目:一张对比表
| PAI | Fabric | mattpocock/skills | obra/superpowers | |
|---|---|---|---|---|
| Stars | 13k | 42k | 78k | 189k |
| 定位 | Life OS | Prompt 工具库 | Claude Code 最佳配置 | Agent 开发方法论 |
| 持久记忆 | ✅ 三层复利 | ❌ | ❌ | ❌ |
| 适用范围 | 整个人生 | 具体任务 | 软件开发 | 软件开发 |
| 安装复杂度 | 高 | 低 | 低 | 低 |
| 自改进 | ✅ | ❌ | ❌ | ❌ |
| 哲学框架 | TELOS / Ideal State | 无 | 无 | 无 |
Star 数的反差揭示了一个市场现实:"帮我写更好的代码"的受众,远比"帮我实现人生理想状态"的受众广。
obra/superpowers 的189k星不是 PAI 的对手,而是不同产品服务不同需求的佐证。
Fabric 和 PAI 来自同一位作者,官方的区分很清晰:Fabric 是"你问什么、AI 做什么"(What to ask);PAI 是"你的 DA 怎么运作"(How your DA operates)。Fabric 是工具,PAI 是系统。两者可以互补——PAI 用户可以把 Fabric 的 Pattern 集成进自己的 Skills。
他在 README 里说:
"模型的重要性不如围绕它的东西(The model matters less than what surrounds it)。"
这不只是技术观点,是一种平权宣言:好的基础设施让人人都能用好 AI,不必依赖最贵的模型。
局限性:清醒地说几句
PAI 是一个哲学雄心极大、但门槛也极高的系统。
绑定 Claude Code,没有退路:PAI 明确只支持 Claude Code,README 里写着"designed to stay that way"。这意味着必须订阅 Anthropic,未来如果 Claude Code 架构变化,PAI 需要大规模重构。
安装极复杂:v5.0.0 官方直接警告"这不是补丁,是不同的系统"。从 v4 升级到 v5 需要完整迁移。理解 TELOS、ISA、Algorithm 的哲学需要时间,门槛远高于 git clone 即用的工具。
过度私人化,几乎无法移植:你在 PAI 里建立的一切——TELOS、记忆、DA 身份——都是高度个人化的,换一个人用就得从头重建。这是设计使然,但也是现实局限。
需要先想清楚人生目标:安装后必须填写 TELOS。对想快速上手的人来说,这是负担;对想认真经营 AI 关系的人来说,这恰恰是最大的价值。
Star 数反差是市场信号:189k vs 13k,绝大多数人想要的是立即可用的工具,不是先建立人生哲学框架。PAI 的目标用户,是那批愿意投入时间建立"属于自己的 AI"的极客。
怎么开始?
如果你想试试 PAI,一行命令:
curl -sSL https://ourpai.ai/install.sh | bash安装器会处理:Bun、Git、Claude Code 验证,ElevenLabs API 密钥(可选),DA 身份设置,Pulse launchd 注册,验证测试。
安装后:
open http://localhost:31337 # Life Dashboard然后在 Claude Code 里运行 /interview,你的 DA 会从这里开始认识你。
想先看看不安装?还有一个 Packs 系统——每个 Pack 是一个独立的、AI 可安装的能力单元,不需要安装完整 PAI,直接指向 Pack 目录让 DA 读取执行即可。目前有54个公开 Packs,包括 Agents、Council、ISA、Research、写作、安全……每一个都可以单独使用。
一句话总结
PAI 是一个安全专家用十年时间,把2016年写在小册子里的预言,一行一行敲成代码的产物。
它不是最流行的 Claude Code 配置(189k对13k),也不是最好上手的 AI 工具。但它可能是目前最接近"每人一个真正理解你的 AI 助手"这个目标的开源实现。
v5.0.0 的副标题是 Life Operating System。
这个说法,Daniel Miessler 已经准备了十年。
项目地址:https://github.com/danielmiessler/Personal_AI_Infrastructure 官方文档:https://docs.ourpai.ai 安装入口:https://ourpai.ai
