 夜雨聆风
夜雨聆风上周,Anthropic 把自己在金融行业做 AI 的全套模板开源了。Agent 工作流、垂直插件、数据接入层、部署配置——从设计到上线,有非常全面的四层。消息一出,不少同行转发的标题都是"拿来就用"。但说实话,在我看来,国内大部分企业现在拿到这套东西,多半用不起来。不是模板不好用,是我们还没走到那一步。
这套模板真正值得学的,是它背后的架构方法。
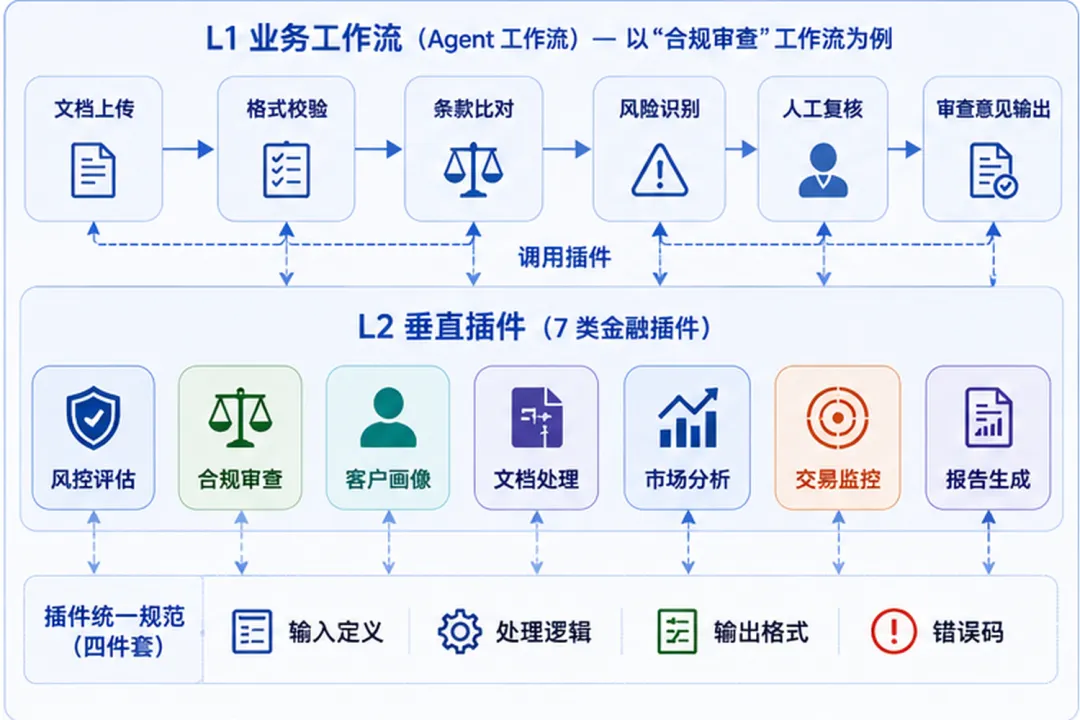
我仔细看了一遍这套模板的结构。从外到内,大致分四层:最外面是 Agent 工作流,定义"AI 在什么业务节点做什么动作";第二层是垂直插件,把金融行业的常见任务封装成可复用的功能模块;第三层是数据接入层,解决"AI 从哪里读数据、怎么读"的问题;最底下是部署配置,管环境、权限、监控。
四层之间有明确的边界。工作流不直接碰数据库,插件不管部署,每一层只做自己该做的事。
这个分层思路,跟我们在项目实践中积累的经验高度吻合。下面逐层说说,每一层到底有什么值得学。
先说第一层:业务工作流设计。
在 Anthropic 的模板里,Agent 工作流不是一个"对话框"。它是一条完整的业务链路——从触发条件、到中间的判断分支、到最终的动作输出,每一步都定好了。
拿它的"合规审查"工作流举例:文档进来,先做格式校验,再做条款比对,最后输出审查意见。整个过程里,AI 做的事情、人工介入的节点、异常处理的路径,全部写在流程定义里。
这跟很多企业现在做 AI 的方式完全不同。
我见过不少团队的做法是:上了一个大模型,开了个接口,然后让业务部门自己想怎么用。结果就是——大家只会拿它问问题,问完了觉得回答不够专业,然后说"AI 没用"。
问题不在模型,在于没有设计业务工作流。AI 在哪个环节介入、接收什么输入、输出什么结果、异常了谁来兜底——这些没定好,模型能力再强也发挥不出来。
这套模板最值得学的第一件事:把"AI 能力"嵌入到"业务动作"里,而不是让 AI 独立存在。
第二层:垂直插件封装。
模板里提供了 7 类金融行业插件,覆盖风控评估、合规审查、客户画像、文档处理、市场分析、交易监控、报告生成。每个插件的结构一样:输入定义、处理逻辑、输出格式、错误码,四件套。
这种封装方式的好处是——业务部门不需要懂 AI,只需要知道"这个插件能做什么、要喂什么数据、会给出什么结果"。
从我以往的经验来看,这才是企业级 AI 落地的正确做法。
我们之前做过一个项目,也是把 AI 能力拆成了模块化的"能力单元"。当时的逻辑跟这套插件思路很像:每个能力单元有标准的输入输出接口,业务部门按需调用,不需要关心底层模型是什么。
但 Anthropic 做得更规范的地方在于——它把插件的边界定得非常严格。每个插件只做一件事,不越界。风控插件不碰客户画像的事,文档处理插件不管市场分析。
我见过的常见问题恰恰相反:一个模块越做越大,什么都往里塞,最后变成一个谁都说不清楚的"万能接口"。维护成本高,出了问题很难定位。
插件封装这件事,学的不是"金融行业要做哪 7 个插件",而是"怎么划边界、怎么定接口、怎么做到一个插件只管一件事"。
行业不同,插件的内容会完全不同。但设计方法是通用的。
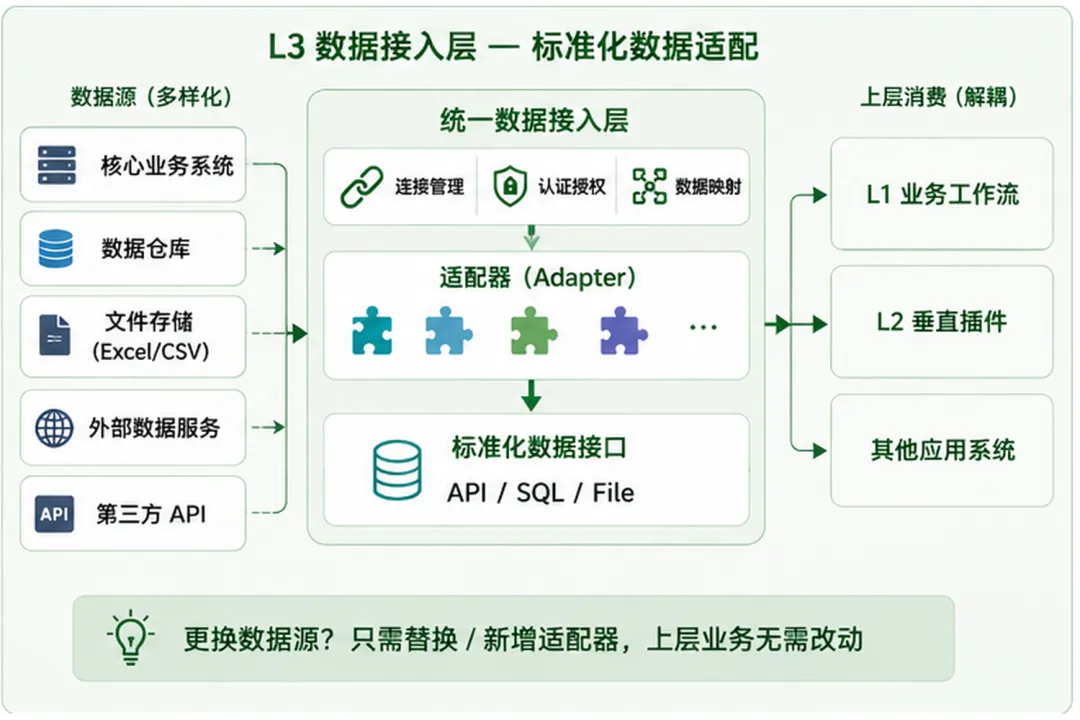
第三层:数据接入标准化。
这一层解决的问题是:AI 从哪里拿数据。
Anthropic 的做法是在工作流和插件之间加了一个独立的数据接入层。所有的数据读取都走这一层,上面的业务逻辑不直接连数据库。
这意味着什么?换一个数据源的时候,不需要改工作流,不需要改插件,只改数据接入层的适配器就行。
这个设计在我们的实际项目里有过深刻教训。
之前给一个地方做了套系统,想直接移植到另一个地方用。到了现场才发现,数据口径不一样,字段名不一样,甚至数据存储格式都不一样。原来的代码里,业务逻辑和数据读取是混在一起的,改一个字段要在十几处同步改。最后几乎重做了一半。
如果当初有一个独立的数据接入层,移植的工作量至少能减少一半。
数据接入标准化不是新概念,但它在 AI 项目里的重要性被很多团队低估了。 大家的注意力都在"模型选哪个""提示词怎么写""流程怎么设计"上面,反而忽略了最基础的一层——数据从哪来、格式统不统一。
第四层:部署配置。
这一层我反而觉得参考价值最低。
Anthropic 的部署配置是基于自家的 Claude 模型和海外云服务搭建的。权限模型、监控方案、日志格式,都跟它的技术栈绑定。国内的部署环境差异太大——有的在私有云,有的在政务云,有的连外网都不通。直接照搬这套部署配置,基本不现实。
但有一个原则可以借鉴:部署和业务完全解耦。 上面三层的任何改动都不需要动部署配置,部署环境换了也不影响业务逻辑。这个架构原则是通用的,不受技术栈限制。
说回现实。
我为什么说国内大部分企业现在多半用不起来?
不是因为技术差距。Anthropic 这套模板用到的技术,国内的大模型厂商基本都能支持。Agent 工作流、插件化、接口标准化,这些概念也不新。
核心障碍在两个地方。
第一,业务流程没有清晰的数字化定义。 很多企业连"我们的业务流程到底长什么样"都说不清楚。流程在老员工的脑子里,在领导的审批习惯里,在"一直以来就这么干"的惯性里。AI 工作流的前提是——得先有一个可以被写成流程图的业务定义,然后才能决定 AI 在哪个节点介入。
第二,数据基础没打好。 数据散在不同系统里,格式不统一,口径不一致,有的甚至还在 Excel 里。在这种条件下搞"数据接入标准化",一动手就会卡在数据源头上。
这就是国内很多企业数字化的现实阶段。过去十年,不少单位上了一堆系统,但系统之间不通、数据之间不通。AI 要在这个基础上跑起来,第一步不是选模型,是先把数据理清楚。
那这套模板对我们到底有什么用?
按照我的理解,有三个层次。
学架构思维。 四层分离、插件化封装、数据接入独立——这些架构原则跟行业无关,跟技术栈无关。不管做金融还是做其他行业,不管用 Claude 还是用国产模型,分层解耦的逻辑都适用。看一遍这套模板的结构,再回头审视自己的方案,多半能发现一些设计上的盲区。
学设计规范。 插件怎么定义输入输出、工作流怎么设定异常处理路径、数据接入层怎么做适配——这些细节层面的设计规范可以直接参考。不需要照抄代码,但可以对照着检查自己的方案有没有遗漏。特别是异常处理这一块,很多方案在"正常流程"上想得很周全,一到"出错了怎么办"就含糊过去了。
给决策层看方向。 如果正在推动一个 AI 项目立项,这套模板可以作为"行业标杆实践"拿给领导看——"Anthropic 做金融 AI 是这么分层的,我们的方案也采用了类似的架构思路。"有个国际头部厂商的开源实践做背书,立项汇报时底气会足很多。
总结一下。
Anthropic 开源这套金融 AI 模板,最大的价值不在代码本身。
真正值得花时间看的,是它背后的三件事:怎么设计业务工作流、怎么封装垂直插件、怎么做数据接入标准化。
这三件事,恰恰是很多企业在 AI 落地过程中最容易跳过的环节。大家都在比"用了什么模型""接了多少数据",反而忽略了中间这一层架构设计。
模板是终局,但不是起点。对大部分企业来说,现在最该做的,不是急着找一个好用的大模型和模板,而是回头看看——我们的业务流程理清楚了吗?数据基础打好了吗?
这两个问题答不上来,再好的大模型放在面前,也只能用它的皮毛。
