夜雨聆风
夜雨聆风去年我参与一个 LLM 推理优化项目,团队一开始全部用 Python 写原型。
逻辑很简单:加载模型、分词、前向传播、生成文本。本地测试没问题,代码也很优雅。结果一上压力测试,吞吐量惨不忍睹。100 个并发打进来,延迟直接飙到几十秒。
我们第一反应是加机器。但老板问了一句:同样规模的模型,别人为什么只用你三分之一的卡?
我去看了一圈开源推理框架的源码,比如 vLLM、llama.cpp。然后发现一件很尴尬的事——真正干活的代码,几乎全是 C++。
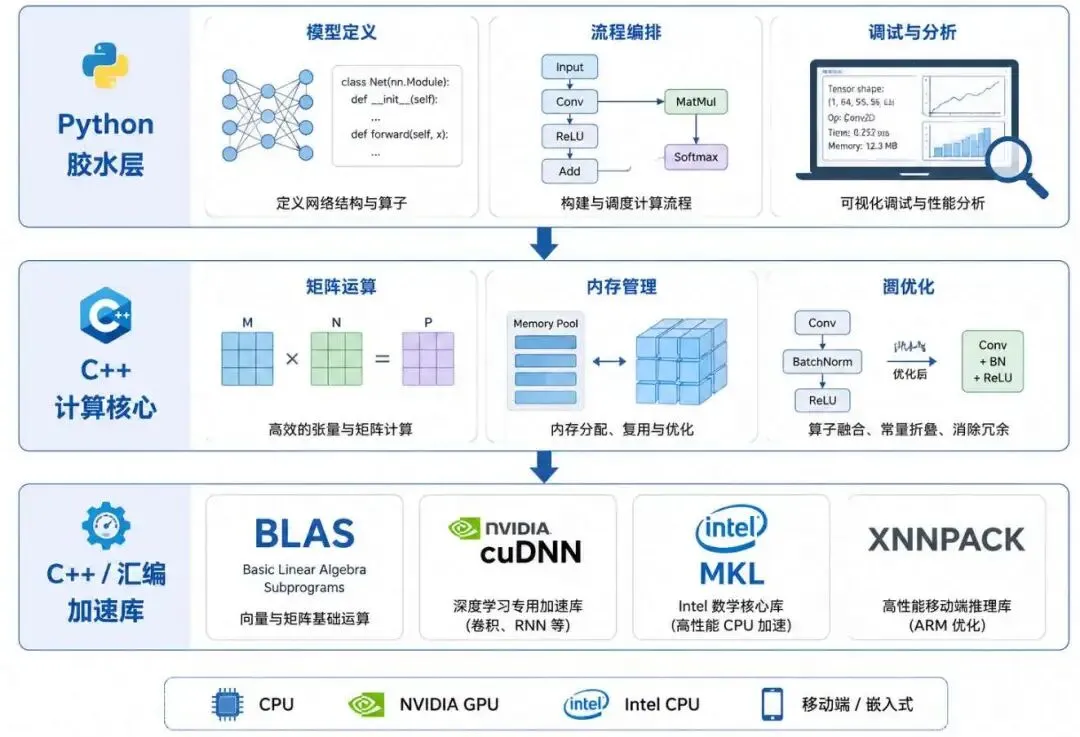
Python 只是那层薄薄的胶水。
最近上线了一套【AI Coding实战课程】,把用AI做开发的整套方法都拆开讲清楚了,如果你也在用AI写代码,但感觉用不顺,想系统提升AI编程能力,可以看下方海报了解详情👇

AI 推理的速度瓶颈,到底卡在哪?
AI 推理本质上就是大量矩阵运算。以 Transformer 为例,一次前向传播涉及成百上千个矩阵乘法(GEMM)。每个 GEMM 又是数以亿计的浮点运算。
Python 本身做这种计算,不是慢,是根本没法做。
原因很直接:Python 是解释型语言,有 GIL(全局解释器锁),还有动态类型带来的运行时开销。你写一个纯 Python 的矩阵乘法,速度可能比 C++ 慢 100 到 1000 倍。
所以业界的路径很清晰:
你用的 PyTorch?它的底层计算引擎 ATen 是 C++ 写的。你用的 Transformers 库?调用的是 C++ 实现的算子。你用的 ONNX Runtime?核心推理引擎也是 C++。
Python 负责让你写得爽,C++ 负责让你跑得动
但这只是表面原因。真正让 C++ 不可替代的,是它对硬件的极致掌控。
我举个例子。有一次我在优化一个注意力模块,发现同样的算法,用 C++ 手写和用 PyTorch 高层 API,速度差了将近 3 倍。
差在哪?

第一,内存布局。
C++ 让你精确控制数据在内存中的排列。比如 Row-Major 还是 Column-Major,数据是否对齐到 64 字节缓存行。这些细节直接影响 CPU 缓存命中率。缓存 miss 一次,代价可能是几百个时钟周期。
Python 的 torch.Tensor 虽然底层也是连续内存,但一旦你在 Python 层做切片、转置、拼接,很容易引入不连续的内存布局。C++ 层可以手动 contiguous()、预分配缓冲区、复用内存,把分配开销压到最低。
第二,零开销抽象。
C++ 的模板和内联函数,可以在编译期把高层抽象完全抹掉。一个 std::transform 循环,编译器可以优化成和手写汇编几乎一样的机器码。
Python 做不到这一点。你写一个 Python 的 for 循环做向量加法,每次迭代都要做类型检查、边界检查、引用计数。C++ 的 for 循环编译后就是几条 SIMD 指令。
第三,SIMD 和向量化。

现代 CPU 支持 AVX2、AVX-512,一条指令能同时处理 8 个甚至 16 个浮点数。C++ 可以直接内联汇编或者使用编译器 intrinsic 调用这些指令。Python 只能依赖底层库帮你做这件事,而很多细粒度场景底层库覆盖不到。
聊一个更具体的例子
llama.cpp 这个项目,很多人用来在本地跑大模型。它的核心思路不是什么神秘算法,而是把 Transformer 推理的每一个环节都用 C++ 手工优化了一遍。
用 ggml自定义张量格式,内存对齐、量化压缩。用 OpenMP 多线程并行,手动调度线程亲和性。 用 SIMD 指令加速 attention 计算。 甚至针对 Apple Silicon 的 NEON 指令集单独优化。
结果是,一台 MacBook 就能流畅跑 7B 参数的模型。如果你用纯 Python 实现同样的逻辑,可能连加载模型都费劲。
这背后没有魔法,就是 C++ 对硬件资源的精细化控制。
那 CUDA 呢?GPU 编程不也是 C++ 吗?
没错。CUDA 的核函数(Kernel)本质上就是 C++ 的扩展语法。你写 __global__ void kernel(...),编译器把它转成 GPU 可以执行的机器码。
为什么不用 Python 直接写 GPU 代码?因为 GPU 编程对内存访问模式、线程块划分、共享内存利用的要求极其苛刻。这些细节必须交给能够精确控制内存和线程的语言。
C++ 在这方面是天然的载体。它既有高级语言的抽象能力,又能下沉到寄存器、缓存、显存这一层。
面试题小结
这类问题在面试里属于「系统认知」考察,经常出现在后端/Infra 岗位的进阶轮次。
核心要点记住:
Python 是胶水,C++ 是引擎:AI 框架的 Python 层负责易用性,C++ 层负责性能。 内存布局决定缓存效率:C++ 可以精确控制数据对齐和内存复用。 零开销抽象:模板和内联让高层代码编译成高效机器码,没有运行时损耗。 SIMD / 多线程 / GPU:C++ 是直接操控这些硬件加速能力的标准语言。 量化与定制优化:如 llama.cpp 所示,C++ 允许针对特定硬件做极致优化。
AI 推理的速度,从来不是凭空变出来的。你看到的「一键推理」背后,是大量 C++ 代码在精确调度 CPU 缓存、GPU 显存、SIMD 指令和多线程资源。
Python 让 AI 变得平民化,这很伟大。但如果你想让模型在生产环境里跑得快、成本低、延迟低,最终还是要回到 C++ 这层硬逻辑上来。
这不是语言偏好问题,是工程现实。速度从来都不是白来的,每一毫秒的优化,都是有人在底层替你扛了脏活。
一个专为校招、社招跳槽的同学打造的1v1 项目实战训练营,提供量身定制训练计划、导师每日代码review,简历优化,大厂强度模拟面试等服务,已助力上百位学员斩获大厂offer!
想要了解训练营详细介绍,可以联系小助手(vx: cppmiao24)。