 夜雨聆风
夜雨聆风我看了太多创业公司,一上来就想着把所有AI能力都扔到云上。好像不上云就不够“先进”,不上云就没法规模化。但今天,我想说句实话:对于文档处理这种场景,一股脑全上云,可能是最笨、最烧钱的做法。

我的判断很直接:未来AI应用的架构,一定是“本地优先,云端协同”的。尤其在文档处理这个领域,把大量推理任务放在本地或边缘,才是真正高性价比的玩法。这不是技术倒退,而是产品思维和商业逻辑的胜利。
很多人没想明白一个基本事实:AI推理的成本,大头在算力消耗和数据传输。你把一份100页的PDF传到云上,让大模型读完、分析、再传回结果,这个过程里,真正有价值的“思考”时间可能只有几秒,但“上传下载”的等待和花费,却可能占了大头。这就像为了喝一杯牛奶,非要养一头奶牛在千里之外,每天用专机给你空运过来。
太蠢了。是时候换种思路了。
本地推理,不是替代云,而是解放云
我听到最多的质疑是:本地设备算力够吗?模型效果能比得上云端大模型吗?

问这个问题的人,可能还停留在两年前的思维。现在的局面已经变了。小型化、高性能的推理模型层出不穷,7B、13B参数级别的模型,在消费级显卡甚至高性能CPU上已经跑得非常流畅。它们处理文档总结、信息提取、格式转换这些任务,精度完全够用。
关键是,你要想清楚云端大模型的核心价值是什么。我的观点是:云上大模型的优势在于“广博的知识”和“复杂的逻辑推理”,而不是所有琐碎的“体力活”。
举个例子。你让AI处理一份公司财报,本地的小模型完全可以胜任:把PDF里的表格提取出来、把关键财务数据摘录整理、甚至生成一个结构化的摘要。这些是“确定性的、模式化的”任务。只有当你需要结合当前股市行情、行业趋势,去深度分析这份财报的潜在影响时,你才需要调用云端那个见识更广、逻辑更强的大模型。
所以,本地推理的角色,是把云端大模型从繁重的“预处理”工作中解放出来。让云端只做它最擅长、附加值最高的那部分工作。这样,云端服务的调用次数会大幅下降,成本自然就下来了。同时,因为大量数据在本地就处理完了,响应速度会更快,用户体验也上去了。
这不就是最好的产品思维吗?把合适的任务,分配给合适的“人”。
算一笔账:成本究竟差在哪里?
我们别空谈,直接算笔经济账。这是所有商业决策的基础。
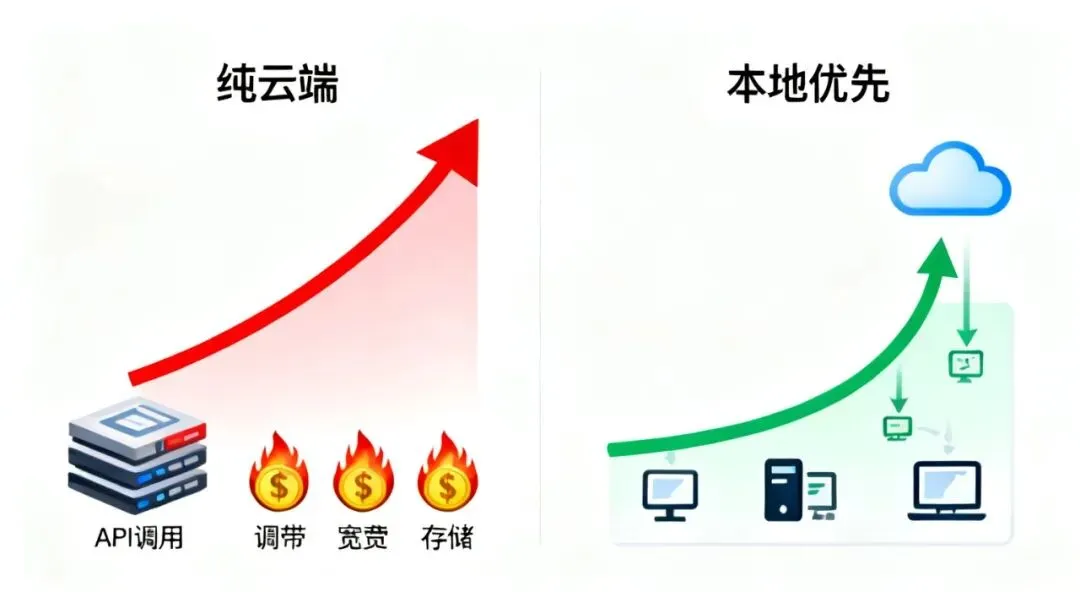
假设你是一家SaaS公司,为中小企业提供智能文档处理服务。采用纯云端架构意味着:用户每上传一个文档,你的服务器就要接收、调用昂贵的云上API、然后返回结果。这里面的成本包括:
1. API调用费:按Token数计费,文档越长越贵。
2. 网络带宽成本:文档上传下载的流量。
3. 存储成本:临时存储文档产生的费用。
如果你的用户量起来,每天处理十万份文档,这个成本会像雪球一样滚起来,压得你喘不过气。很多AI创业公司死掉,不是产品没人用,而是用的人太多,把自己“用破产”了。
换成“本地优先”的架构呢?核心逻辑变了。你把一个轻量级的推理模型(比如经过精调的7B模型)内置到客户端或者部署在客户的企业边缘服务器上。
当用户处理文档时:
* 第一步(本地):文档解析、基础信息提取、简单QA,这些任务在本地瞬间完成。零云端成本,零网络延迟。
* 第二步(按需上云):只有遇到本地模型解决不了的复杂问题,比如需要最新知识、跨文档深度推理,才去调用云端大模型。这时,传输的已经不再是原始文档,可能只是一个提炼过的问题和几段关键文本,数据量小了百倍,API调用也精准了很多。
成本差异立竿见影。云端从“主力劳动者”变成了“专家顾问”,只处理最棘手的10%的问题。总体成本可能降低70%以上。对于创业公司,这省下的就是生命线。对于大企业,这意味着规模化应用真正成为可能。
产品架构的胜利:从“功能堆砌”到“体验设计”
成本只是一方面。更重要的是,这种架构带来的是产品体验的质变。

纯云端方案有一个致命伤:延迟和依赖。网络一卡,整个服务就卡。用户看着上传进度条,耐心一点点被消磨。这不符合一个好产品的标准。
本地优先的架构,实现了真正的“瞬时响应”。点开文档,摘要瞬间生成;提问关于文档的问题,答案秒出。这种流畅感,是云端方案无论如何优化网络都难以企及的。它把AI能力变成了像本地搜索一样的基础设施,随时可用,毫无感知。
同时,它更好地解决了隐私和安全这个“老大难”问题。敏感文档不出本地,从物理上断绝了数据泄露的风险。这对金融、法律、政府等领域的客户来说,是比任何技术承诺都更硬的卖点。你可以直接告诉客户:“您的数据,永远在您自己的设备里打转。” 这句话的杀伤力,远超你吹嘘自己用了多牛的加密技术。
所以,这不仅仅是技术架构的选择,更是产品哲学的体现。你是想做一个“看起来高大上”但又慢又贵的技术演示,还是想做一个“真正好用”且让客户用得起的生产力工具?我的选择永远是后者。
未来的战场:混合智能架构
所以,我的结论很清楚:在AI应用,特别是工具型、垂直型应用的下半场,竞争的焦点将不再是“谁能调用最大的模型”,而是“谁能设计出最聪明、最经济的混合智能架构”。

这个架构的核心是任务调度与路由的智慧。系统需要能自动判断:这个任务,是该本地的小模型处理,还是该请云端的“老专家”出马?这背后需要的是对业务场景的深度理解,对模型能力的精确把握。
未来的AI应用引擎,会像一个经验丰富的经理,手下既有执行力强的基层员工(本地小模型),也有视野开阔的智库专家(云端大模型)。它的本事,就在于知人善任,把合适的任务派给合适的人,用最低的成本、最高的效率达成目标。
那些还在盲目追求“全云端”、“大模型通吃”的团队,很可能在不久的将来,被成本和体验两座大山压垮。而真正理解“本地优先,云端协同”价值的团队,正在悄悄构筑自己的护城河——一条由极致性价比、瞬时响应和绝对隐私构成的护城河。
技术终将普惠。而让技术普惠的关键一步,就是让它变得更便宜、更快、更安全。本地优先的AI推理,正在这条正确的道路上。
别被“云原生”的概念绑住了手脚。商业的本质是创造价值,而不是堆砌技术。有时候,后退一步,让计算发生在离数据最近的地方,反而是最前瞻、最凶猛的一步。

本文由 写作鹅 创作
