 夜雨聆风
夜雨聆风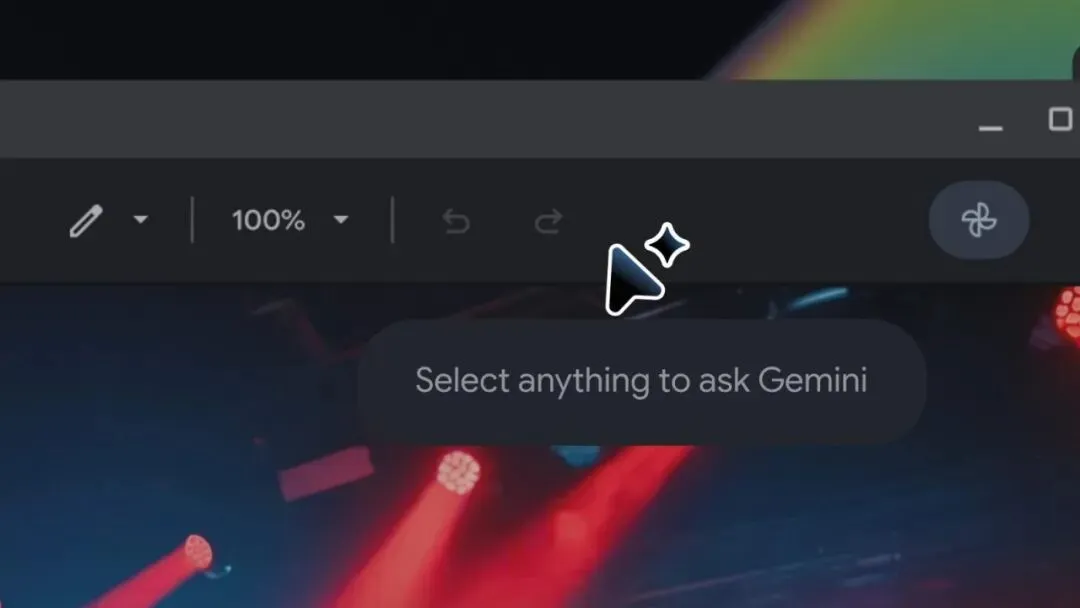
AI 的下一个战场:不是更强的模型,是更大的带宽
两个月前 OpenClaw 爆火的时候,我不明白为什么,明明都是 Claude Code 在半年前就能做到的事情,为什么反响这么大。后来我想清楚了,OpenClaw 的突破不是 Agent(可以和环境交互)、不是记忆人格什么的,是交互方式。因为人不想一整天都呆在电脑前面,人希望随时随地都能接触到他的 Agent,例如手机上的 IM,这是全世界人机交互最广泛最自然的方式(尽管这不是 Agent 接受 Context 最好的方式,所以在大部分习惯了 ClaudeCode 的人中评价并不高)。当时我有一个判断,人既然不想被困在电脑屏幕前,也一定不想被困在手机屏幕前,所以交互的革新还没有完成,人机带宽仍然有显著的瓶颈。
这篇文章想聊聊,这个瓶颈正在被哪些人、以什么方式打破。
两个问题,同一个答案
当前人机交互的瓶颈,可以拆成两个问题:
问题一:AI 怎么知道我在说什么? 用 AI 之前,你得先用语言描述清楚上下文——这个网页、这段文字、这张图、这个日期。你得把世界"翻译"给 AI 听。
问题二:AI 怎么跟我一起工作? 当前的 AI 是回合制的——你说完它才想,它说完你才能说。像在用对讲机,不像在共处一室。
这周,两个重要的发布撞在了一起,恰好各自回答了其中一个问题:
Google Magic Pointer:解决问题一。让指针理解"你在指什么",AI 不需要你描述上下文。 Thinking Machines Lab Interaction Models:解决问题二。消灭回合制,AI 同时听、说、看、想。
两者加在一起,才构成完整的新交互范式。
Google Magic Pointer:让 AI 看到你在看什么
鼠标指针在过去五十年只做一件事:告诉计算机你的光标在哪个像素坐标上。Google DeepMind 的 Magic Pointer 让它多了一件事:理解你指的那个东西是什么。
四个设计原则:
保持流程不中断:AI 能力跨所有应用原地生效。指向 PDF 段落要摘要、悬停统计表要饼图、高亮食谱要双倍配料——不切换工具。 指+说:AI 自动捕获指针周围的视觉和语义上下文。不需要写 prompt 描述"我在看第三段第二句话"——指一下就够了。 拥抱"这个"和"那个":人类日常对话就是"修一下这个""把这个移过去"。Magic Pointer 理解"指针+语音+上下文"的组合,用最短的自然语言完成复杂请求。 像素变实体:手写便签→可勾选待办清单,旅行视频暂停画面里的餐厅→预订链接。屏幕上的静态内容变成可交互的。
产品落地:Gemini in Chrome 已开始推送(框选商品对比、指向客厅位置可视化新沙发),Googlebook 笔记本即将以 Magic Pointer 为核心交互方式。
本质上,Magic Pointer 做的是消灭"翻译层"——以前你的交互流程是"看到→描述→输入 prompt",现在是"看到→指一下→说一句"。省掉的那一步,就是认知负荷。
Thinking Machines Interaction Models:让 AI 像人一样协作
如果说 Google 解决了"AI 怎么理解我的上下文",Thinking Machines Lab(Mira Murati 创立)解决的是更底层的问题:AI 怎么跟我一起工作,而不是等我发指令。
他们提出的概念叫"交互模型"(Interaction Models)。核心理念一句话:交互不应该是模型外面套的一层壳,交互就是模型本身。
为什么这很重要?当前所有实时语音 AI——包括 GPT-Realtime、Gemini Live——都是在普通文本模型外面套了一个"交互 harness":用 VAD(语音活动检测)判断谁在说话、用 ASR 转文字、用 TTS 念回答。问题是,这些外部组件的智商远低于模型本身。VAD 不知道你在写 bug 时需要被提醒,不知道你在切换语言时需要纠正,不知道视频里那个人开始做俯卧撑了需要数数。
TML 的做法是把交互能力直接训练进模型:
200ms 微轮次:输入和输出以 200ms 为粒度交替处理,没有人工定义的"轮到谁说话"边界。 全模态早期融合:音频、视频、文字从输入端就一起训练,不是各自编码再拼接。 双模型架构:276B MoE 交互模型持续在场保持实时响应(轮次延迟 0.40s vs GPT 的 1.18s),后台模型异步处理深度推理和工具调用,结果在合适时机织入对话。
效果是质变——他们测了几个"现有模型得零分"的能力维度:
| 能力 | TML | GPT-Realtime-2 | 是什么 |
|---|---|---|---|
| 每 4 秒提醒呼吸 | 64.7% | 4.3% | 时间感知 |
| 切换语言时纠正 | 81.7% | 2.9% | 主动监听+判断 |
| 看视频数俯卧撑 | 35.4% | ~0 | 视觉主动性 |
| 动作开始说 Start | 32.4 mIoU | 0 | 实时视觉跟踪 |
这些不是"做得更好",是现有模型根本"不存在"这些能力。因为它们的交互是靠外部 harness 拼出来的,而 harness 没有眼睛也没有时间感。
殊途同归:更大的带宽
Google 和 TML 的路线不同,但赌的是同一件事:人机交互的带宽正在成为瓶颈,而不是模型智商。
Google 从操作系统层切入——让指针理解语义,让界面感知上下文。TML 从模型架构层切入——让交互能力随模型 scaling 而增长,不是靠外部 patch。
两者合在一起指向一个未来:AI 不是"一个你需要去的地方",而是"你所到之处自然存在的能力"。
这个判断的另一个佐证:AI 正在从各种方向突破屏幕的边界。OpenAI 和 Anthropic 都在推语音实时交互,Meta 在做 AR 眼镜让 AI 看到你看到的东西,OpenAI 的 Codex /goals 命令让 Agent 在你走开之后继续工作。每一个方向,都是在拓宽人机之间的那条管道。
Hayek 在 1945 年写过一句话:"关于特定时空环境的知识,永远无法以统计形式进入任何中央决策者的大脑。"AI 时代的人机交互面临同样的问题——人类大量的隐性知识(这个项目为什么暂停过、那个客户上次聊了什么、这个设计决策背后的权衡)无法通过 prompt 传递给 AI。唯一的办法是让 AI 更深入地嵌入人类的工作流——你在哪里工作,它就在哪里观察和学习;你需要它的时候,不需要先去"召唤"它。
这就是"更大的带宽"——不仅是技术指标上的延迟和吞吐,更是人类知识和意图能够流向 AI 的通道有多宽。
