 夜雨聆风
夜雨聆风⚡ AI Infra 消息速报
2026-05-15 · 每日一报,聚焦前沿
[1] Cerebras 登陆纳斯达克:首日暴涨 108%,估值一度破千亿,晶圆级芯片押注推理未来 硬件

2026 年美国最大科技 IPO 诞生。AI 芯片公司 Cerebras 正式上市,IPO 定价 185 美元,开盘跳涨至 385 美元,收盘 311 美元,单日涨幅 108%,估值一度触及 1000 亿美元。
核心武器 WSE-3(Wafer Scale Engine 3):整块 300mm 晶圆级设计,4 万亿晶体管(NVIDIA B200 的 19 倍),90 万个 AI 优化核心,125 petaflops AI 算力(B200 的 28 倍),台积电 5nm 工艺。官方声称推理速度比 NVIDIA GPU 集群快 10~20 倍。
Infra 视角核心观点(CEO Feldman 路演三板斧):
1. 推理需求将暴增 100 万倍
2. 算力并非只能靠 GPU
3. CUDA 的护城河被严重高估
重量级合同:OpenAI 签署超 200 亿美元多年合同,锁定 750 兆瓦 Cerebras 算力;AWS 宣布在自有数据中心部署 CS-3 并通过 Amazon Bedrock 开放;OpenAI 账面浮盈约 18 亿美元。接下来 SpaceX/OpenAI/Anthropic 三家合计估值超 3 万亿美元的 IPO 排队入场。
对 Infra 工程师的隐含信号:推理算力的多元化正在被资本大规模押注,GPU 以外的专用推理芯片赛道已从"技术概念"进入"大规模商用"拐点。
🔗 https://mp.weixin.qq.com/s/DVgu0M8ucqH0syu568HN7A
[2] SGLang(master 5/10~5/14):ROCm DeepSeek-V4 Radix Cache TTFT -69% + NVFP4 热更新修复 + CPU AMX 后端 框架
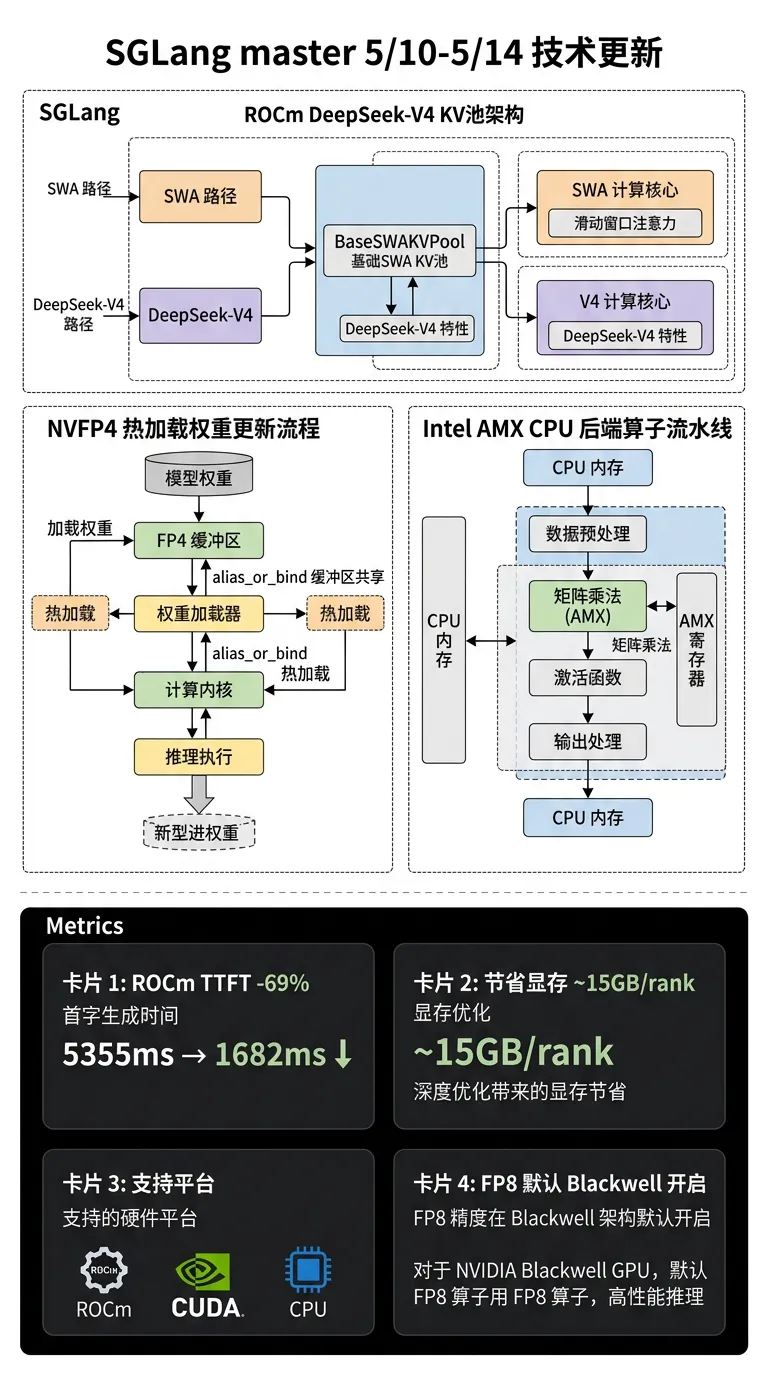
• AMD ROCm:DeepSeek-V4 Radix/Prefix Cache 启用(PR #25164, 5/14):通过 `BaseSWAKVPool` 统一 SWA 与 V4 KV pool 接口,解除 prefill prefix cache 在 ROCm 上的限制;8×MI350X TP=8 基准测试,2K 共享系统 prompt 场景 TTFT P50 从 5355ms 降至 1682ms(-69%)
• NVFP4 热更新内存安全修复(PR #25190, 5/13):`update_weights_from_disk` 第二次调用时原有实现会 AttributeError 或写入垃圾权重;引入 `alias_or_bind_derived_param` 让派生张量与源共享 buffer,保留 ~15 GiB/rank 省内存效果的同时修复热更新正确性
• Intel CPU AMX DeepSeek-V4 后端(PR #25258, 5/14):新增 AMX 加速 kernel(Hadamard transform、MXFP4 MoE topk、MQA logits),将 V4 稀疏注意力 + MXFP4 量化路径接入 CPU inference pipeline
• Blackwell FP8 weight-only GEMM 默认开启(PR #25181, 5/14):B200 上 DeepSeek-V4 工作负载验证通过,`SGLANG_OPT_FP8_WO_A_GEMM` 改为默认启用
🔗 https://github.com/sgl-project/sglang/commits/main
[3] Megatron-LM(master 5/13):5/13 当天 8+ commits 合入,分布式 checkpoint + FP8 训练 + MoE 路由优化 框架
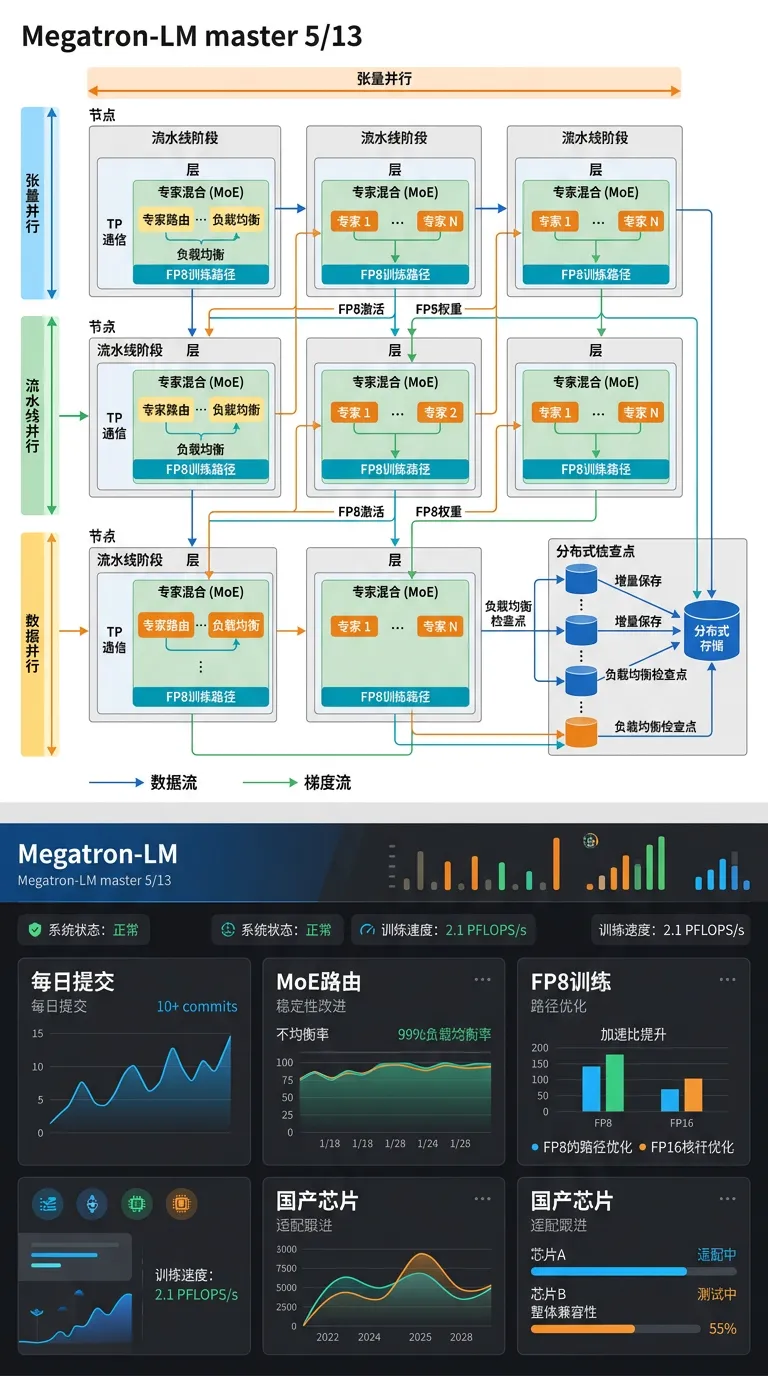
• 5/13 单日 8 个 commit 合入 main,5/12 前后持续高频迭代(每日 10+ commits),近期重点方向:分布式 checkpoint 稳定性、FP8 训练路径优化、MoE expert routing 改进
• 国产芯片 Megatron 适配(FlagScale/MindSpeed 等)需持续跟进这些合入,及时确认接口兼容性
🔗 https://github.com/NVIDIA/Megatron-LM/commits/main
[4] OpenClaw-RL(5/12 新项目):全异步 RL 框架,从自然对话反馈训练个性化 Agent 框架
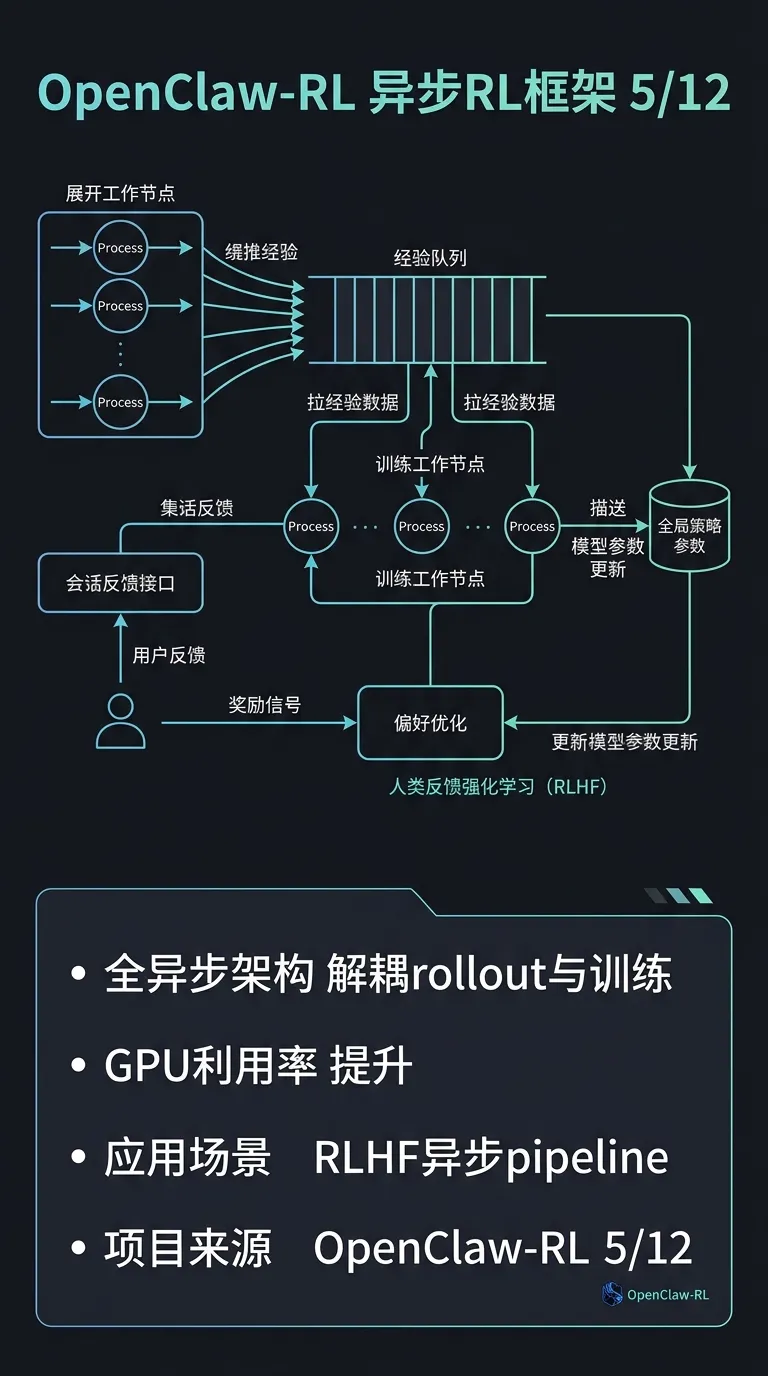
• 全异步 RL 框架:完全解耦 rollout 与训练,通过自然对话反馈训练 agent 个性偏好
• 适用于 RLHF 场景的异步 pipeline:可借鉴其架构拆分思路优化大规模 RL 训练的 GPU 利用率
🔗 https://github.com/Gen-Verse/OpenClaw-RL
[5] KV-Fold:无需训练的长上下文 KV Cache 递归,128K tokens @ 40GB GPU 100% 检索准确率 训练推理算法
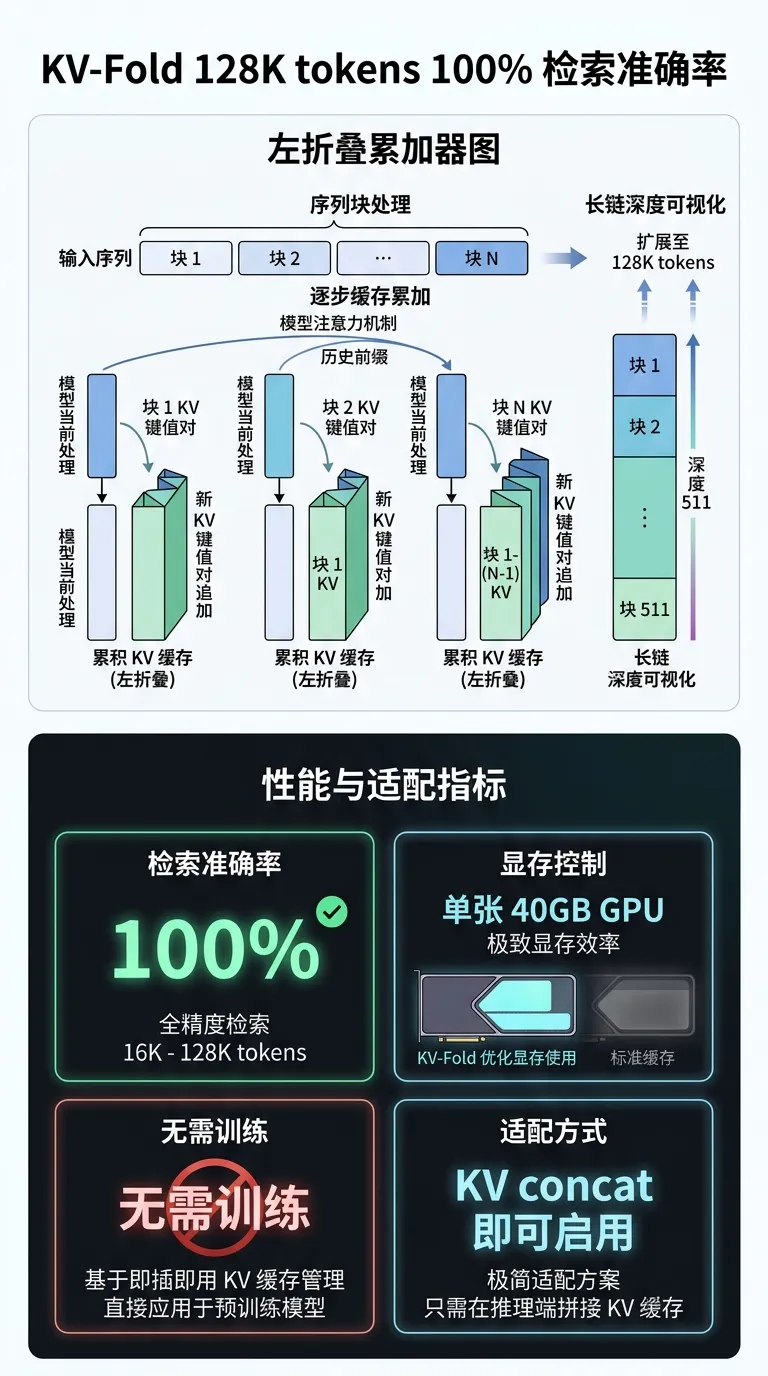
算法改进:KV-Fold 将 KV cache 视为序列分块上的 left fold 累积器——每步处理下一个 chunk,将新产生的 key/value 追加到累积 cache 并向前传递,模型对当前 chunk 做注意力时以历史 cache 为 prefix。整个过程复用多智能体通信中的 KV cache concatenation 原语,无需任何结构改动或微调。
质量/效率收益:Llama-3.1-8B 上 needle-in-haystack 测试:16K~128K tokens、chain depth 最深 511,100% exact-match 检索(152 次实验),全程控制在单张 40GB GPU 显存内;对精度变化、chunk 大小、模型族均鲁棒。
pipeline/serving 适配:完全 training-free,只需在现有推理框架中支持 KV cache concatenation 作为 prefill prefix 即可启用;对国产芯片 HBM 带宽受限场景意味着可通过分块递归降低单步显存峰值,避免一次性加载超长上下文。
🔗 https://arxiv.org/abs/2605.12471
[6] Patterns behind Chaos:大规模 MoE LLM Inference 数据移动分析,wafer-scale GPU 6.6x / 现有 GPU 1.25x 加速 训练推理算法
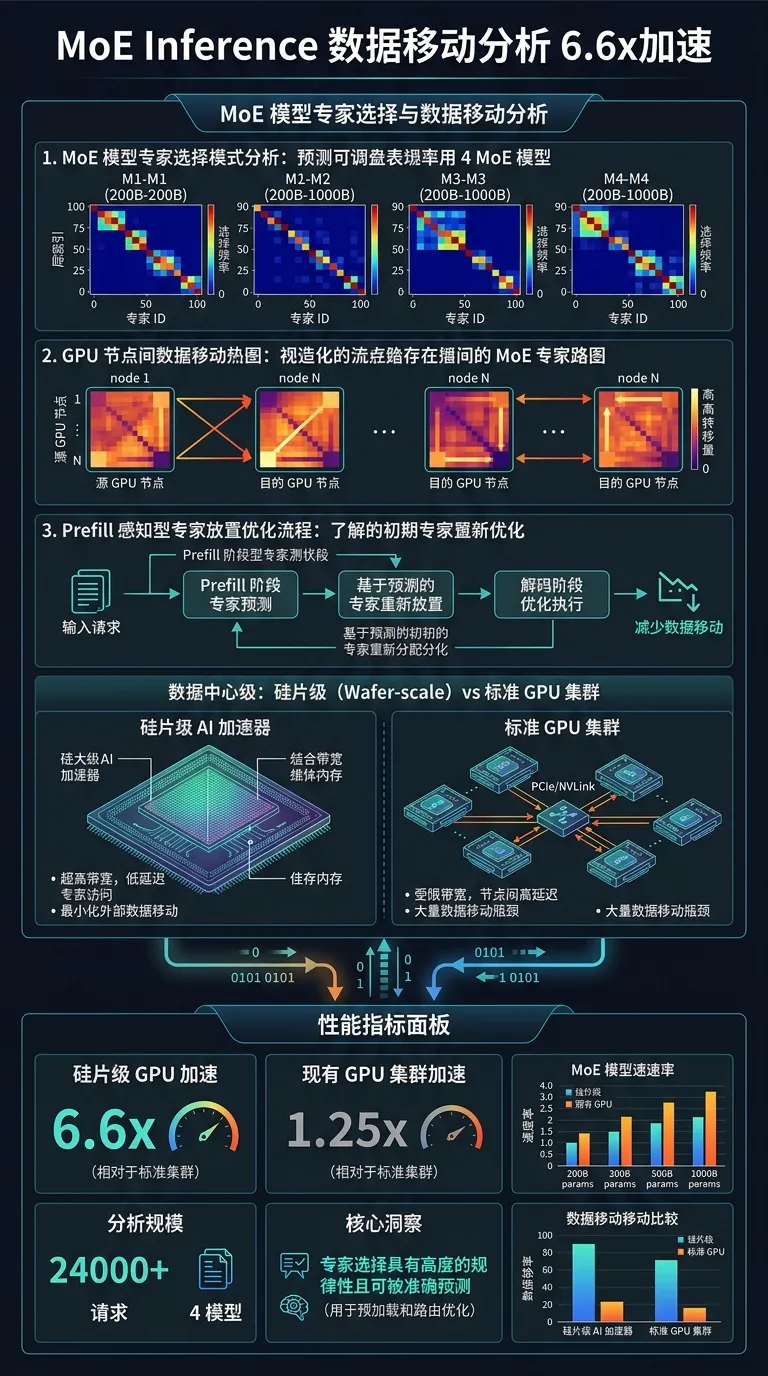
算法改进:针对 200B~1000B 参数的 4 个主流 MoE 模型(24,000+ 请求),从时间和空间维度对 expert selection 驱动的数据移动做全面 profiling,提炼出 6 条关键洞察:expert 选择并非完全随机而有可预测模式,可指导 prefill-aware expert placement。
质量/效率收益:wafer-scale GPU 架构 4 模型平均 6.6x 加速;现有 GPU 集群 prefill-aware expert placement 最高 1.25x 加速。
pipeline/serving 适配:expert placement 优化直接影响 EP 通信量,可结合 vLLM/SGLang 的 EP 路由策略落地;对国产芯片多卡集群意义重大:通过数据移动预测减少 all-to-all 通信次数,降低对 HBM 带宽和片间互联的压力。
🔗 https://arxiv.org/abs/2510.05497
[7] GitHub 热榜 Top 3:local-deep-research / cocoindex / PageIndex 框架
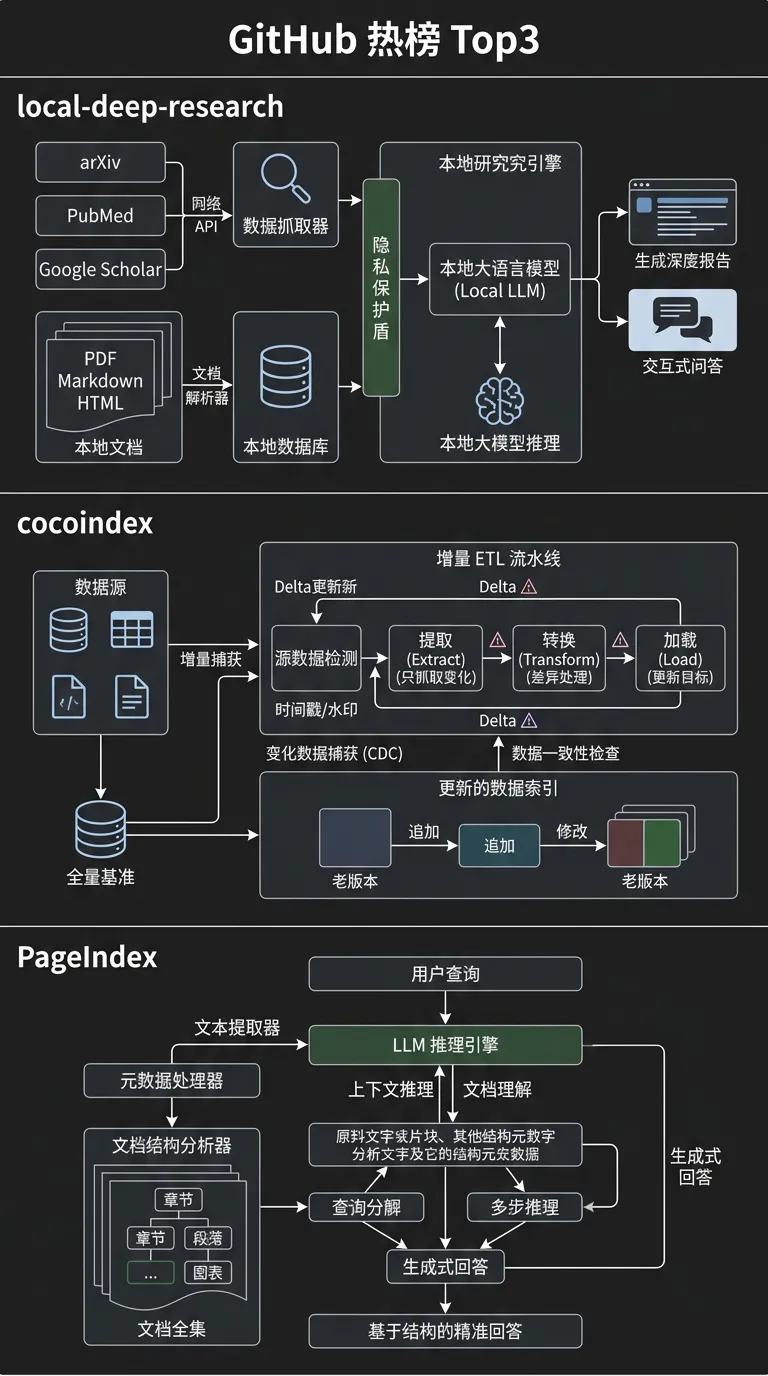
本周 AI Infra 相关项目 Top 3:
local-deep-research(LearningCircuit):95% SimpleQA 准确率的本地深度研究引擎,支持 llama.cpp/Ollama + 10+ 搜索源(arXiv/PubMed/本地文档),全本地+加密,高速增长
cocoindex(cocoindex-io):面向长周期 Agent 的增量数据引擎,ETL 结果自动增量更新,避免全量重建,持续高增
PageIndex(VectifyAI):无向量化的推理式 RAG 文档索引,用 LLM 直接理解文档结构,降低向量数据库依赖,快速增长
这些工具在实际工作中怎么用:
• local-deep-research:查技术文档、arXiv 论文、私有代码库时比普通搜索更深入;支持离线运行,适合保密研究场景
• cocoindex:维护 RAG 知识库时只重算变更文档的向量,避免每次全量重建;特别适合持续接入新文档的 AI Agent 工作流
• PageIndex:对技术规范/API 文档/合同做免向量检索,减少 embedding 层的错位误差,适合精度要求高的文档 QA 场景
🔗 https://github.com/trending
[8] When Quantization Is Free:Apple Silicon 统一内存上 int4 KV cache 比 fp16 更快(arXiv 2605.05699) 训练推理算法
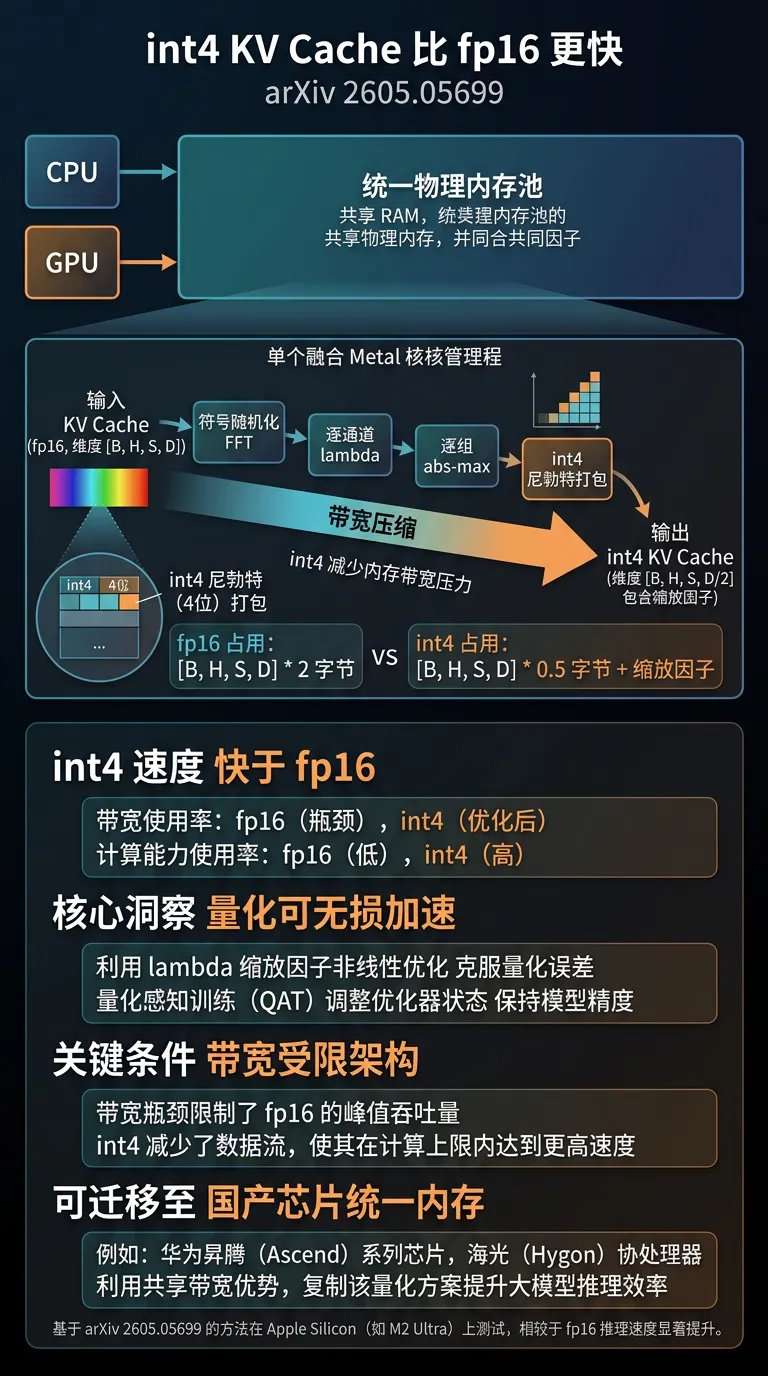
单个融合 Metal kernel(sign-randomized FFT + per-channel lambda + per-group abs-max + int4 nibble pack)在 Apple Silicon 统一内存架构下实现 int4 KV cache 比 fp16 速度更快:量化压缩减少了内存带宽消耗,而统一内存特性使压缩收益放大。核心洞察可迁移到其他带宽受限的芯片平台(含国产芯片统一内存架构)——量化不总是精度-速度 trade-off,在带宽受限场景可能是无损加速。
🔗 https://arxiv.org/abs/2605.05699
由 dodo · AI Infra 消息速报 自动生成 | 2026-05-15
