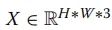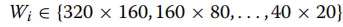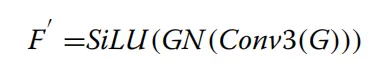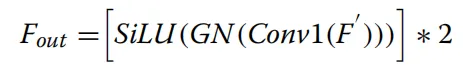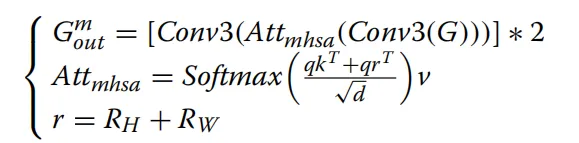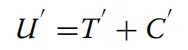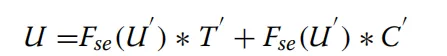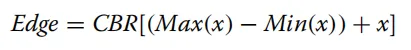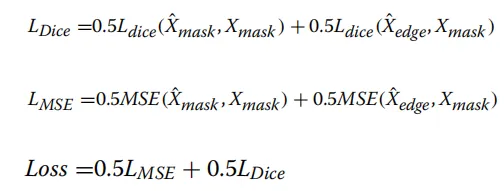让甲骨“说话”:AI如何精准识别三千年前的灼烧痕迹?论文题目:Gca-pvt-net: group convolutional attention and PVT dual-branch network for oracle bone drill chisel segmentation
作者:Guoqi Liu, Yiping Yang, Xueshan Li, Dong Liu, Linyuan Ru and Yanbiao Han
会议或期刊名:npj Heritage Science
单位:中国河南省新乡市河南师范大学计算机与信息工程学院、中国河南省新乡市,甲骨文骨智能计算实验室、中国河南省新乡市河南师范大学历史文化学院、中国河南师范大学教学资源与教育质量评估大数据工程实验室,河南省新乡市
发布日期:2024年 7 月 29 日
文章地址:https://www.nature.com/articles/s40494-024-01378-z#author-information
一、研究动机
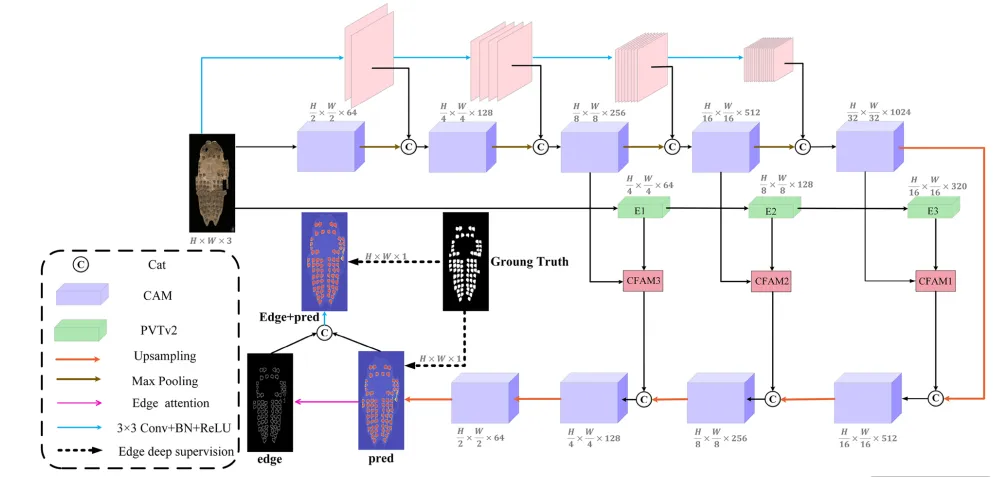
甲骨作为商代文明的核心载体,其表面的钻凿痕迹(Obdc)是除文字外判别甲骨年代与分期的关键非文字信息 。然而,甲骨在数千年的埋藏过程中普遍存在残损断裂,且钻凿区域因灼烧形成的边缘往往与背景对比度极低,加之形态各异、数量不一,给人工精确识别带来了极大挑战 。目前甲骨的分类主要依赖碑帖文字,但在文字缺失的情况下,非文字材料的自动化处理显得尤为迫切,而此前在甲骨钻凿的自动分割领域仍属空白 。因此,本研究旨在利用深度学习技术,克服甲骨图像复杂背景与细节丢失的问题,通过实现钻凿形态的精准分割,为考古学家提供更科学、高效的甲骨分期与断代辅助手段 。本文提出了一种高效的甲骨钻凿双分支分割网络 GCA-PVT-Net,如图 7 所示。该模型主要由三个关键组件构成:PVTv2 编码器、卷积注意力模块(CAM)以及通道特征聚合模块(CFAM。模型的设计逻辑是并行运行 CAM 编码器和视觉 Transformer(PVT)的分割分支,并利用 CFAM 模块将这两个分支产生的特征进行深度聚合。此外,本文在解码器的最后阶段引入了边缘深度监督策略,以确保在捕获全局上下文信息的同时,能够精准还原复杂的边缘细节。图7 所提出的GCA-PVT-Net架构由骨干PVT、CAM和CFAM组成。
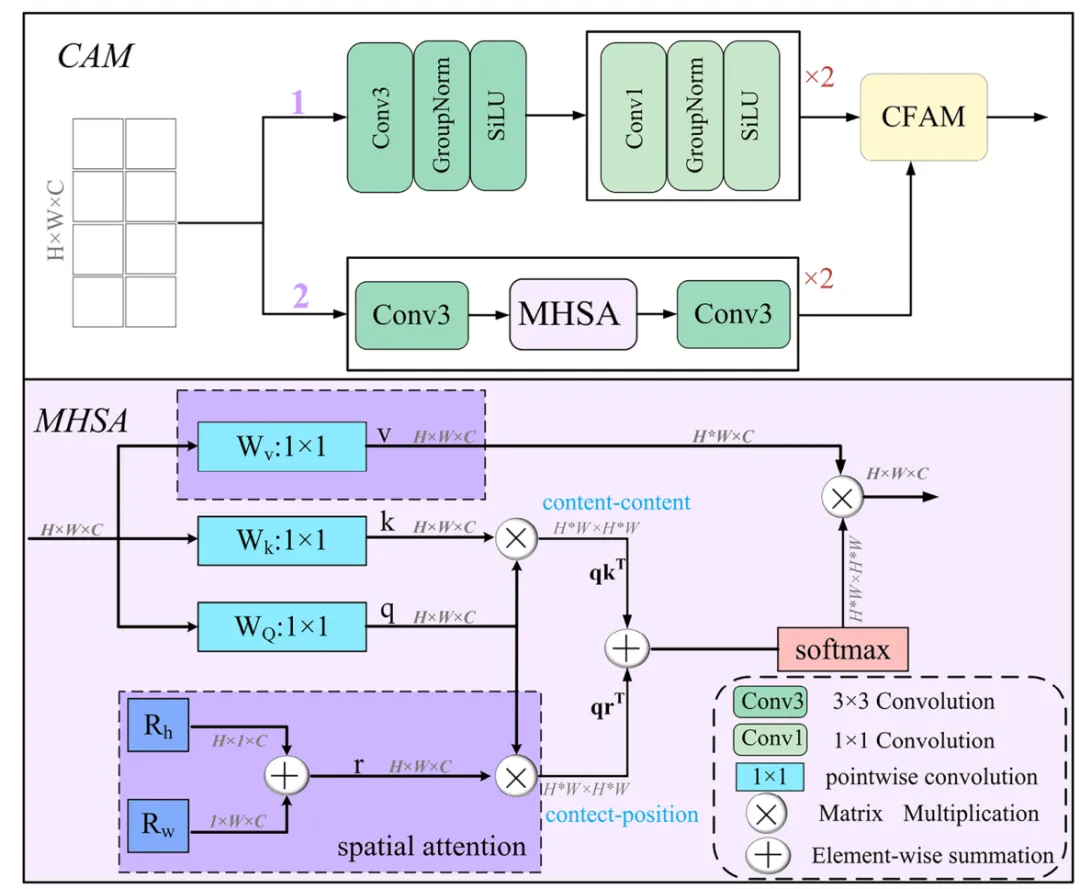
系统首先通过预处理构建金字塔特征 。具体流程包括:通过下采样操作生成四张三通道图像,随后应用内核大小为3*3的卷积层,生成特征序列X_{ij},如图 7 顶层分支所示,其中生成的特征定义为通道数C_i从64增加到512,考虑到连续的最大池化操作可能会导致网络牺牲细微的边缘细节,研究者利用这些初始金字塔特征X_i来补充 CAM 编码器在特征提取过程中流失的信息。模型的主干分支采用 PVTv2 网络,输入图像X后会生成四种不同尺度的特征E_i以及全局上下文信息 。如图 7 中间的绿色部分所示,由于分辨率最低的特征层E_4会丢失大量关键信息,模型仅选择前三层特征层与辅助分支 CAM 编码器提取的特征进行融合 。与此同时,CAM 编码器会产生一组对应的特征分布M_i。在特征聚合阶段,模型利用 CFAM 模块将 CAM 编码器产生的高级特征M_i与 PVTv2 分支的低级特征E_i深度融合,随后将其传递给对应的 CAM 解码器,如图 7 底部的预测路径所示,为了进一步提升分割质量,模型在解码器的最后阶段通过计算最大池化与最小池化结果的差值来提取边缘特征并将其作为边缘深度监督信号。这一流程最终产生了输出结果f^0、f^1CAM 模块被设计为同时担任网络的编码器和解码器,其核心目标是增强注意力的收敛速度并提升分割性能。虽然 Transformer 具有强大的特征提取能力,但在处理小规模数据集时往往需要极大的数据量支撑,且直接与 CNN 结合可能导致模型产生学习偏好,偏向于更易收敛的卷积特征。因此,如图 8 所示,CAM 采用了将输入特征图解耦为两个并行分支的策略,利用不同的特征提取方法独立学习输入特征。这种结构能够有效整合全局和局部信息,在保留甲骨边缘细节的同时,更好地模拟图像内部的长程相关性。图8 CAM结构包含两条平行分支。紫色填充区域为 MHSA 的具体结构。最终,这两条分支通过CFAM 融合在一起。图中×2表示该操作重复执行了两次。
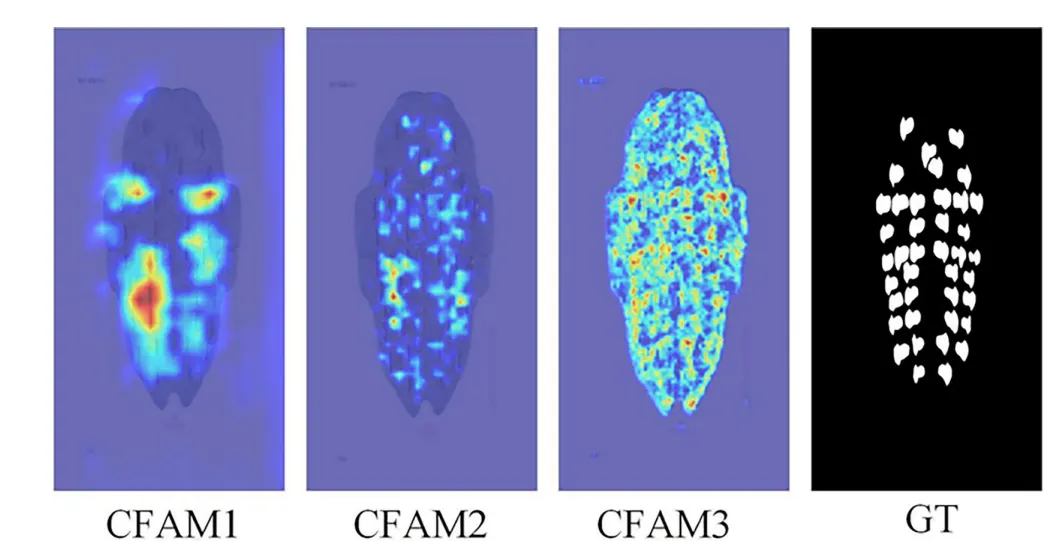
CAM 的第一分支主要由三组卷积组成,旨在协助第二分支增强对细微特征的提取能力 。处理流程首先采用一组3*3的卷积核:随后,模型通过两组1*1卷积核实现跨通道特征信息的交互:通过结合3*3卷积层与多头自注意力(MHSA)机制,旨在构建图像的整体概览并捕捉全局长程依赖关系。如图 8 底部紫色区域所示,其 MHSA 采用了空间注意力方案,通过嵌入代表高度R_h和宽度R_w维度的两个可学习向量来表征位置信息。这些向量与查询矩阵 q融合产生上下文位置向量,并与内容向量相乘得到空间敏感的相似性特征,使得模型能更精准地关注甲骨上的关键钻凿区域。局部边缘细节与全局上下文信息在分割任务中具有高度的互补性,但传统的简单融合方法(如直接拼接或相加)无法实现这两种异构特征间的有效互学习。为了解决这一瓶颈,本研究设计了通道特征聚合模块(CFAM)。该模块通过自适应权重计算方法,确保了特征在通道维度上的平滑融合,不仅显著增强了网络对不同尺度、不同机制生成特征的感知能力,还为后续层级提供了更具辨识度的特征信息。CFAM 的数学实现与特征重加权如图 9 所示,CFAM 的处理流程分为两个关键步骤。首先,将来自 Transformer 分支的特征T和来自卷积分支的特征C分别通过3*3卷积操作,得到中间特征C',随后,通过元素级求和得到初步融合特征U’之后对U'进行挤压与激励操作。SE 模块通过变换F_se将U'映射为权重向量,旨在增强模型对关键通道特征的敏感度,提升信息传输效率 。最后,利用该权重对T'和C‘行加权融合,得到最终输出U通过这种重加权机制,模型能够为图像的不同位置分配不同的重要度,从而优化通道维度的特征表达。如图 10 所示,通过 CFAM 融合 PVTv2 编码器的低级特征与 CAM 编码器的高级特征,可以将高级特征作为先验知识,引导低级特征的注意力精准集中在目标物体区域。图10 在CFAMi生成的模型热力图中,颜色越深表示注意力权重越高。从热力图可见,CFAM 为解码器提供了全局信息。
边缘深度监督的生成机制
为了平滑模型预测图中出现的锯齿状边缘,并进一步提升分割精度,研究者引入了边缘深度监督策略 。该策略通过执行类似于图像处理中腐蚀和膨胀的反向操作来生成所需的边缘特征 。在数学逻辑上,由于图像边缘通常是像素值发生剧烈变化的区域,最大池化(Max pooling)能够捕获边缘处的显著特征,而最小池化(Min pooling)则主要捕获黑暗区域或背景像素,两者的差值能有效地突出边缘信息在实验中,训练集和测试集图像均被统一调整为640×320尺寸,数据集按9:1的比例进行划分。训练阶段采用AdamW优化器更新网络参数,学习率与权重衰减均设为1×10⁻⁴。为提升数据集质量,我们采用了数据增强技术,包括马赛克数据增强、随机旋转、随机翻转和归一化处理,每种操作的概率均为0.5。此外,在训练阶段将训练集规模扩大十倍以进一步扩充数据集。所有实验中模型均训练100个周期,批量大小设为4。
消融实验
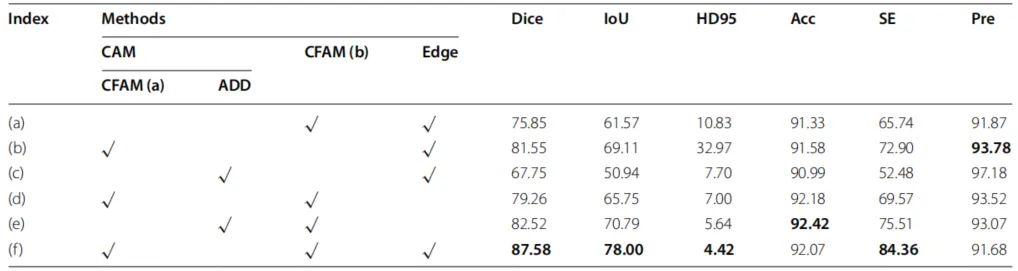
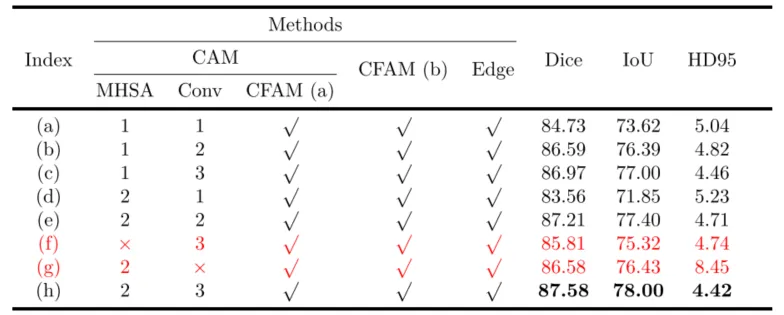
为了系统验证 GCA-PVT-Net 各核心组件的有效性,研究者在相同实验条件下进行了多组消融实验。如表 2 所示,当移除卷积注意力模块(CAM)后,模型的 Dice 系数和 IoU 分别大幅下降了 11.73% 和 16.43%,这证明了 CAM 在精准定位目标及丰富全局细节方面起着决定性作用。同时,若去掉边缘深度监督策略,Dice 指标会下降 8.32%,且在可视化结果中(如图 10d 所示)可以观察到明显的边缘锯齿和细节捕获不足的问题。针对 CAM 内部结构的实验进一步揭示了卷积与注意力机制的互补性 。如表3所示,在缺乏多头自注意力(MHSA)的情况下,模型的 Dice 指标下降了 1.77%,表明了全局长程依赖对提升分割性能的贡献 。而若移除卷积分支,模型对边缘特征的提取能力显著削弱,导致表征边缘误差的 HD95 指标增加了 4.03%,强调了卷积层在补充边缘细微细节时的必要性。表2 使用不同模块进行消融研究的结果
表3 在保持所有其他参数一致的条件下,对CAM结构进行的消融研究。
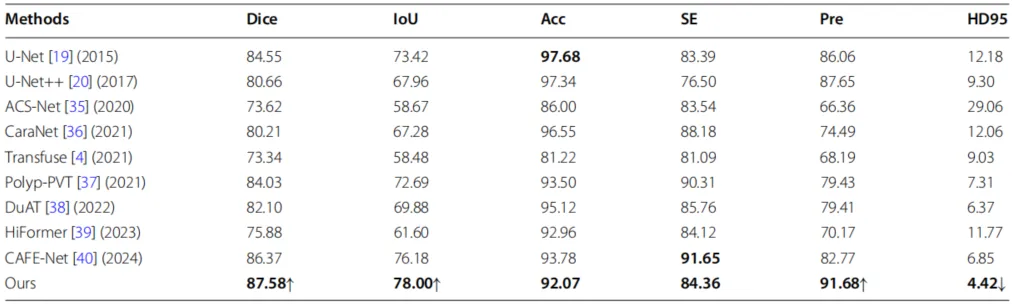
通道特征聚合模块(CFAM)的实验结果则展示了自适应融合的优势。如表2所示,采用 CFAM 模块的完整模型在各项指标上均优于使用简单元素相加(ADD)的版本,尤其是在 HD95 指标上优势显著,证明了 CFAM 能够有效平衡 CNN 与 Transformer 两种异构特征,防止模型因过度关注局部信息而导致分割图完整性缺失。此外,研究者还探讨了图像输入分辨率对模型性能的影响。如表4所示,在对 256*256、512 *512及640*320三种分辨率进行测试后发现,640*320的方案在 Dice、IoU 及 HD95 等核心指标上均达到了最优值。实验分析指出,由于高层特征在连续下采样过程中会损失信息,过低的分辨率会导致噪声增加,而适当的分辨率设置则能确保特征提取的精准度。本文将GCA–PVT–Net与九种最先进的(SOTA)方法进行了比较。
表5 不同网络模型在Obdc数据集上的实验对比结果
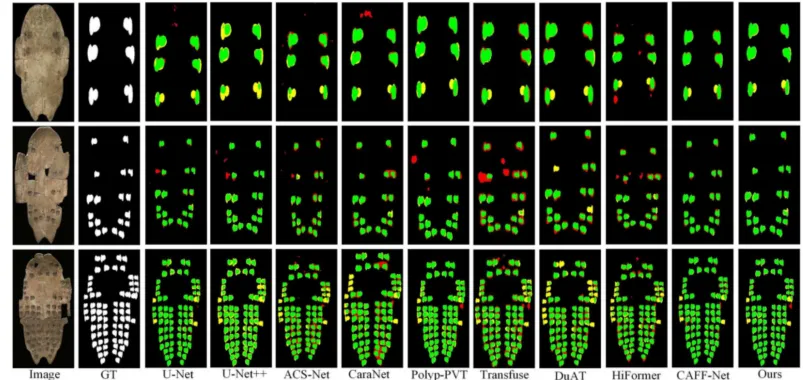
图15 Obdc数据集上不同 SOTA 方法结果的对比。绿色、红色和黄色区域分别代表真阳性、假阳性和假阴性结果。
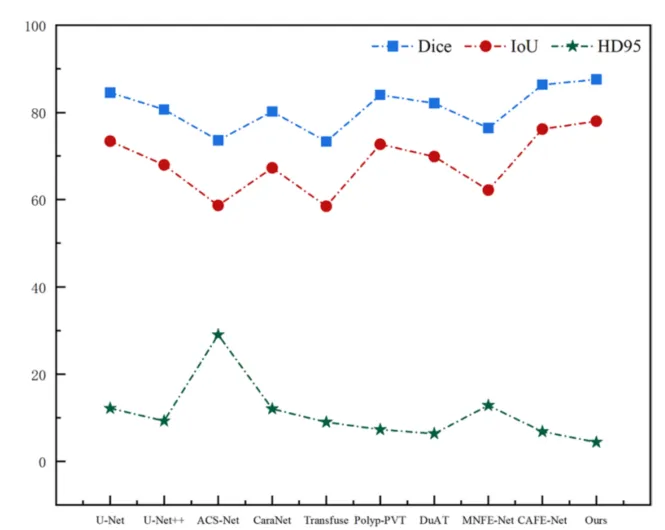
图16 不同分割方法在 Obdc 数据集上的Dice、IoU 和HD95 指标
本研究针对甲骨钻凿自动化分割这一空白领域,成功构建了首个专门的Obdc数据集,并提出了高效的GCA-PVT-Net双分支网络。实验证明,核心模块CAM有效融合了卷积与Transformer的优势,实现了目标与背景的精准分离并平衡了模型收敛;CFAM模块则通过异构特征的自适应融合,显著强化了全局信息下的边缘提取能力;配合边缘深度监督策略,预测图的平滑度得到极大提升。综合评价结果显示,该方法在Dice、IoU及HD95等关键指标上均全面超越现有SOTA模型。尽管目前在处理重度残损甲骨时仍面临挑战,但本研究为甲骨文数字化保护及考古断代提供了强有力的技术支撑,未来将重点攻克复杂损毁场景下的分割难题。 夜雨聆风
夜雨聆风